
射得到的低维特征来反映射得到高维的非线性映
射空间,因此自编码器网络能够提取非线性特征
[18]
.
去噪自编码器
[19]
的原理与自编码器相同,都是尽
量使重构输出数据等于输入数据,两者的不同之
处在于,去噪自编码器的输入是被人为破坏的噪
声数据. 原始干净数据为x,进行加噪处理后,输
入网络得到的特征图
[19]
表示为
h(
˜
x) = f (W ×
˜
x + b). (1)
˜
x
式中: 为将输入x进行加噪处理后的噪声数据,
W为网络权重,b为偏置. 该阶段为编码阶段.
在得到噪声数据的特征图之后,网络已经学
习到输入数据的隐含特征,接着网络会用已经学
习到的特征来重构出原始干净的数据. 最终网络
得到的重构无噪数据如下式所示:
y(
˜
x) =g[W
′
×h(
˜
x) + b
′
] =
g[W
′
× f (W ×
˜
x + b) + b
′
]. (2)
式中:W′为权重,b′为偏置. 该阶段为解码阶段.
基于降噪自编码器原理,LLNet将自编码器
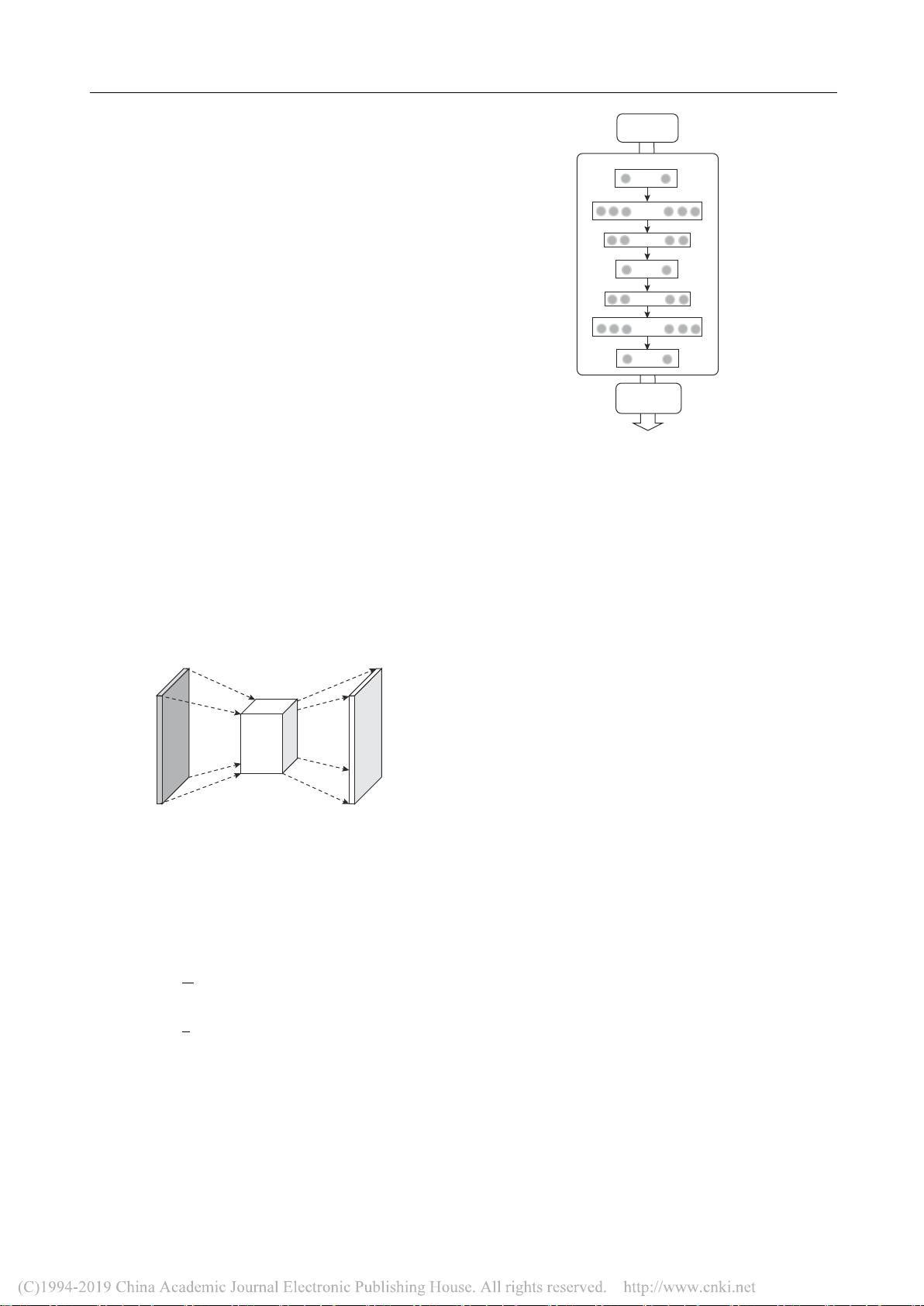
应用在图像增强领域中. LLNet的结构示意图如
图1所示,输入低光图像,经过多层隐藏单元,最
终得到重构的增强图像.
得到重构增强图像之后,网络开始进行参数
微调. 首先进行原始干净图像与重构增强图像之
间损失函数的计算. 损失函数计算公式
[17]
如下:
L
DA
(D; θ) =
1
N
N
∑
i=1
|| y
i
− ˆy(x
i
)||
2
2
+ β
K
∑
j=1
KL( ˆρ
j
|| ρ)+
λ
2
[||W ||
2
F
+ ||W||
2
F
]. (3)
θ = {W, b,W
′
, b
′
}
KL( ˆρ
j
|| ρ)
γ
β
式中: 为模型参数,D为低光图像,
N为样本数量, 为KL散度, 、 为通过
交叉验证确定的标量超参数.
当损失函数计算完成后网络会采用向后传播
算法,以最小化损失函数的原则进行网络微调.
LLNet的模型结构图如图2所示.
尽管LLNet方法具有很好的图像增强效果,
该网络会产生大量冗余参数,同时数据前期处理
的时间成本较大. 为了克服以上缺点,本文提出
基于卷积自编码器的图像增强方法
—
CAENet.
2 采用卷积自编码器的图像增强
网络
基于LLNet方法,提出基于卷积自编码器的
图像增强框架—CAENet. 首先,为了减少前期数
据处理时间,CAENet将LLNet的人为低光处理模
块添加到整体网络框架中,实现了框架统一,避
免了多平台处理存在的诸多不便因素;其次,为
了将该方法更好地应用到三通道彩色图像中,受
卷积自编码器
[20]
启发,将卷积操作当作自编码器
的编码操作来得到低光图像的低维特征表示,结
构图如图3所示. 网络训练时输入处理后的低光
图像,随后经过卷积网络进行编码,得到特征图,
此时网络学习到低光图像的隐含特征,接着进行
反卷积得到重构明亮图像,最后计算损失函数以
便网络调参.
2.1 低光处理
训练网络之前,首先需要对输入图像进行破
坏,即低光处理. 与去噪自编码原理相同,该操作
主要是为了避免隐藏层学习到没有意义的恒等函
数,其次也是为了网络能够学习到更加具有鲁棒
性的特征表达
[21]
.
编码 解码
特征图
图 1 低光网络(LLNet)结构图
Fig.1 Structure diagram of low light net (LLNet)
对
比
度
增
强
模
块
低光图像
增强图像
…
编码
解码
…
…
…
…
…
…
图 2 LLNet模型结构示意图
Fig.2 Diagram of module structure of LLNet
1730
浙 江 大 学 学 报(工学版) 第 53 卷
剩余12页未读,继续阅读

MurcielagoS
- 粉丝: 20
- 资源: 319
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建Cadence PSpice仿真模型库教程
- VMware 10.0安装指南:步骤详解与网络、文件共享解决方案
- 中国互联网20周年必读:影响行业的100本经典书籍
- SQL Server 2000 Analysis Services的经典MDX查询示例
- VC6.0 MFC操作Excel教程:亲测Win7下的应用与保存技巧
- 使用Python NetworkX处理网络图
- 科技驱动:计算机控制技术的革新与应用
- MF-1型机器人硬件与robobasic编程详解
- ADC性能指标解析:超越位数、SNR和谐波
- 通用示波器改造为逻辑分析仪:0-1字符显示与电路设计
- C++实现TCP控制台客户端
- SOA架构下ESB在卷烟厂的信息整合与决策支持
- 三维人脸识别:技术进展与应用解析
- 单张人脸图像的眼镜边框自动去除方法
- C语言绘制图形:余弦曲线与正弦函数示例
- Matlab 文件操作入门:fopen、fclose、fprintf、fscanf 等函数使用详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


