线性判别分析(LDA):降维与分类
需积分: 0 191 浏览量
更新于2024-08-05
收藏 555KB PDF 举报
"本文主要介绍了线性判别分析(LDA),一种用于降维和分类的监督学习方法。LDA的主要思想是通过投影使类内方差最小化,类间方差最大化,从而达到区分不同类别的目的。文章详细阐述了LDA的基本原理,包括二类LDA的算法步骤,并探讨了LDA的目标优化问题以及如何找到最佳投影方向。最后,概述了LDA的执行流程。"
线性判别分析(LDA)是一种广泛应用的监督学习降维技术,与无监督的主成分分析(PCA)不同,LDA在处理数据时考虑了样本的类别信息。LDA的核心理念是将高维数据投影到一个低维空间,通常是单个维度,使得不同类别的样本在这个新空间中的差异最大化,同时保持同一类样本的紧密性。
在LDA中,类内方差和类间方差的概念至关重要。LDA的目标是找到一条投影直线,使得投影后同类样本的分布尽可能紧密,不同类样本的分布尽可能分离。具体来说,投影后,同类样本的协方差要尽可能小,而不同类样本的中心点距离要尽可能大。
二类LDA的算法流程如下:
1. 计算每类样本的均值向量和样本协方差矩阵。
2. 构建类间散度矩阵,它衡量的是不同类别的样本中心之间的距离。
3. 构建类内散度矩阵,反映了同类样本的离散程度。
4. 求解最优投影方向,这通常对应于类间散度矩阵与类内散度矩阵的某种比例的最大特征值所对应的特征向量。
5. 将原始数据投影到这个方向上,形成降维后的数据表示。
6. 使用投影后的数据进行分类或其他后续分析。
在数学表达上,LDA涉及到瑞丽商和广义瑞丽商的概念。瑞丽商是向量在特定矩阵作用下的比值,其最大值和最小值分别对应于该矩阵的特征值。在LDA中,优化目标是最大化类间散度与类内散度的比值,这可以通过寻找类间散度矩阵的最大特征值对应的特征向量来实现。
LDA算法流程包括输入数据集、计算统计数据(如均值和协方差)、求解最优投影方向、投影数据并进行分类。这种方法在高维数据处理中非常有用,特别是在分类任务中,因为它能够保留区分不同类别的关键信息,同时降低数据的复杂性。然而,LDA的一个限制是假设数据服从正态分布,且类内协方差矩阵相同,这在实际应用中可能并不总是成立。尽管如此,LDA仍然是数据预处理和特征选择的重要工具之一。
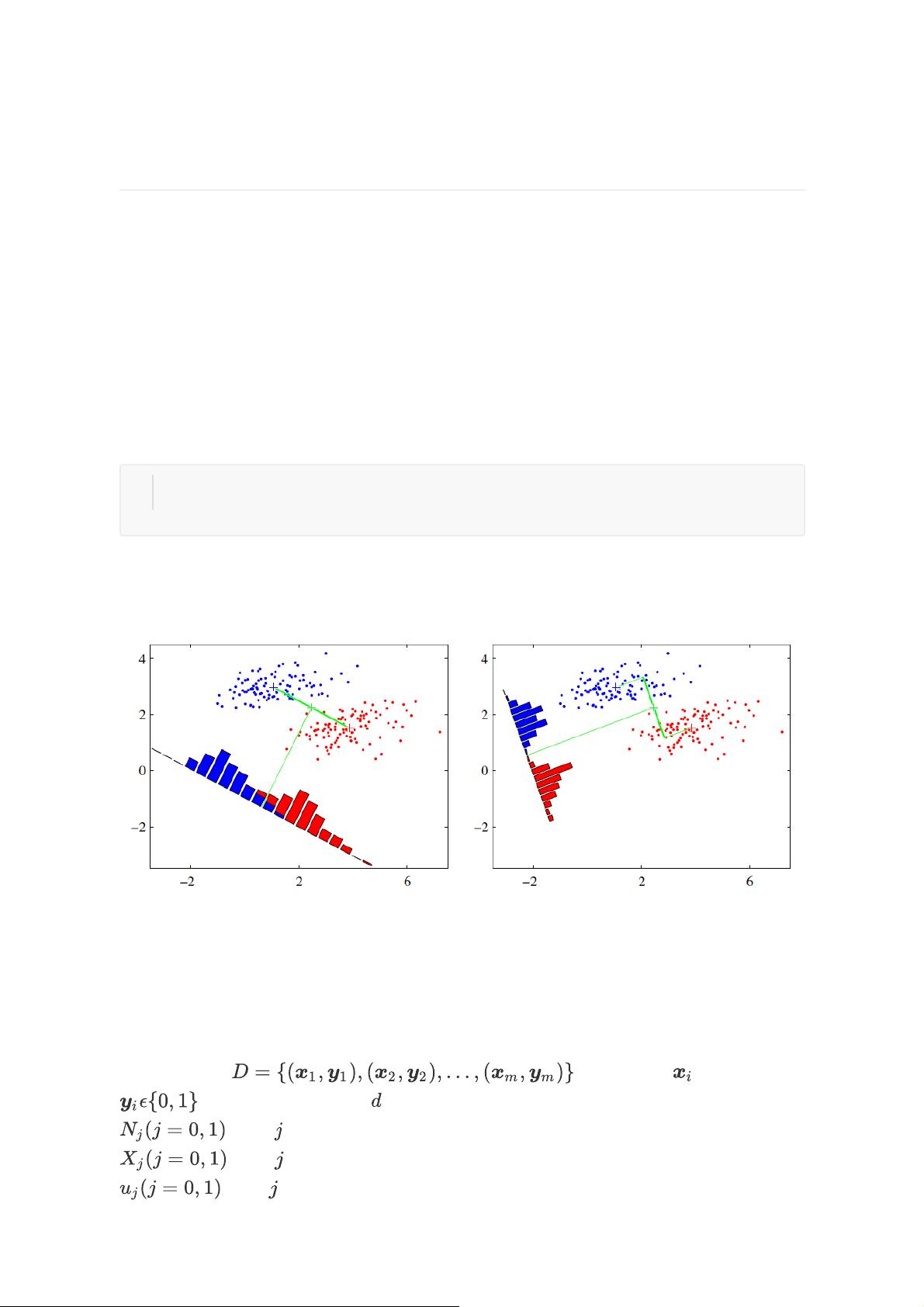
线性判别分析(Linear Discriminant
Analysis, LDA)
LDA是一种经典的降维方法,和主成份分析PCA不考虑样本类别输出的无监督降维技
术有所区别,LDA是一种监督学习的将为技术,数据集的每个样本有类别输出。
1. LDA思想总结
“投影后类内方差最小,类间方差最大”
1. LDA将多维空间中的数据投影到一条直线上,将d维数据转化成以为数据进行处
理
3. 对数据分类时,将其投影到同样的这条直线上,再根据投影点位置确定样本类
别。
左图:让不同类别的平均点距离最远
右图:让同类别数据相距最近
2. 二类LDA算法原理
输入数据集: ,其中样本 是n维向量,
,降维后的目标维度 。定义:
为第 类样本个数;
为第 类样本的集合;
为第 类样本的均值向量;
2. 将多维训练数据投影到一条直线上,同类数据的投影点尽量接近,异类数据点尽
量远离。
1
下载后可阅读完整内容,剩余3页未读,立即下载
113 浏览量
2020-03-02 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-06-27 上传
2023-05-27 上传

豆瓣时间
- 粉丝: 26
- 资源: 329
 我的内容管理
展开
我的内容管理
展开







最新资源
- Hadoop生态系统与MapReduce详解
- MDS系列三相整流桥模块技术规格与特性
- MFC编程:指针与句柄获取全面解析
- LM06:多模4G高速数据模块,支持GSM至TD-LTE
- 使用Gradle与Nexus构建私有仓库
- JAVA编程规范指南:命名规则与文件样式
- EMC VNX5500 存储系统日常维护指南
- 大数据驱动的互联网用户体验深度管理策略
- 改进型Booth算法:32位浮点阵列乘法器的高速设计与算法比较
- H3CNE网络认证重点知识整理
- Linux环境下MongoDB的详细安装教程
- 压缩文法的等价变换与多余规则删除
- BRMS入门指南:JBOSS安装与基础操作详解
- Win7环境下Android开发环境配置全攻略
- SHT10 C语言程序与LCD1602显示实例及精度校准
- 反垃圾邮件技术:现状与前景
