深度学习模型DeepFM:融合因子机与深度学习的CTR预测解决方案
需积分: 0 126 浏览量
更新于2024-08-05
收藏 1.74MB PDF 举报
在深度学习应用于推荐系统中的CTR(点击率)预测方面,DeepFM算法是一项重要的进展。该模型的目标是捕捉用户行为背后的复杂特征交互,以便最大化点击率。CTR预估数据的特点主要包括:
1. **多元输入类型**:DeepFM模型处理的数据包含类别型和连续型数据。类别型数据通常通过one-hot编码来表示,而连续型数据可以选择离散化后再编码,或者保留原始数值,取决于数据处理的需求。
2. **高维特性**:由于数据往往来自多个不同的特征域(Field),导致维度非常高。这种高维特性在传统方法中可能导致过拟合问题,因此对模型的泛化能力提出了挑战。
3. **数据稀疏性**:推荐系统的数据通常很稀疏,因为用户的行为记录往往是局部和不全面的。这使得传统的线性模型如逻辑回归在处理这些数据时效率低下。
4. **特征组织**:DeepFM采用Field为单位组织特征,这有助于区分不同来源或含义的特征,并且在神经网络架构中更好地整合它们。
**模型演进与创新**:
DeepFM模型是对Google的Wide & Deep模型的扩展。传统的Wide & Deep模型在“宽”(Wide)部分倾向于低阶特征交互,而“深”(Deep)部分则关注高阶特征的学习。然而,DeepFM通过将 Wide 和 Deep 部分共享输入层,消除了对专家特征工程的依赖,仅使用原始特征进行训练。这种设计简化了模型构建流程,同时强调了对低阶和高阶特征交互的双重学习。
**实验验证**:
作者通过一系列实验对比DeepFM与现有模型(如FM、Deep & Cross Network等)在CTR预测任务上的效果,结果显示DeepFM在效率和性能上具有显著优势。无论是基准数据还是商业数据集,DeepFM都能够更准确地捕捉用户行为的复杂性,从而提高点击率预测的准确性。
总结来说,DeepFM作为一种结合因子机和深度学习的神经网络架构,有效解决了CTR预测中的高维稀疏数据和复杂特征交互问题,简化了模型设计,提升了预测性能,对于提升推荐系统的效果具有实际应用价值。
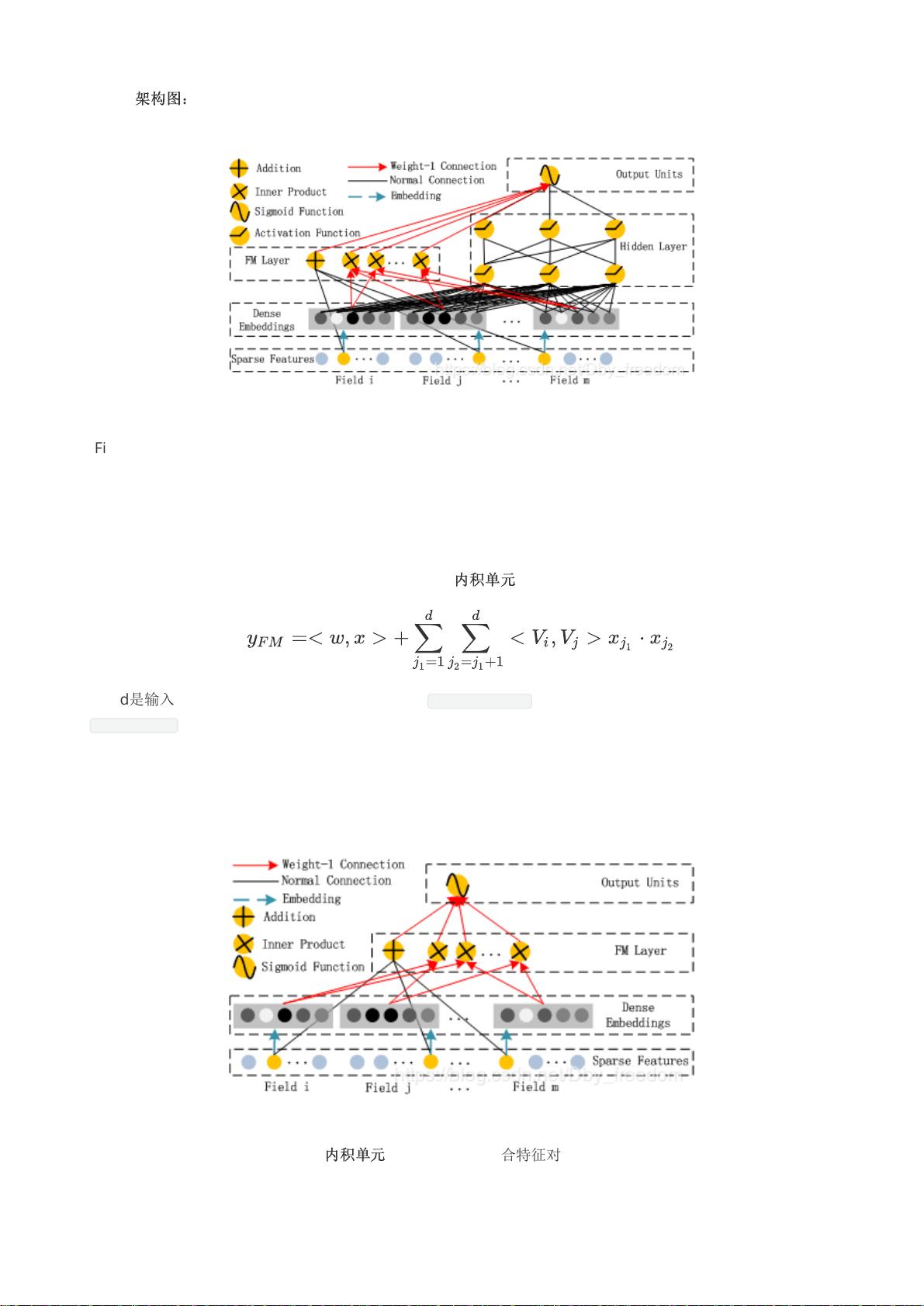
DeepFM
架
构
图
:
Figure 1: Wide & deep architecture of DeepFM. The wide and deep component share the same input raw
feature vector, which enables DeepFM to learn low- and high-order feature interactions simultaneously from
the input raw features.
3.1 FM Component
FM部分的输出由两部分组成:一个Addition Unit,多个
内
积
单
元
。
这里的d是输入one-hot之后的维度,我们一般称之为 feature_size 。对应的是one-hot之前的特征维度,我们称之
为 field_size 。
FM架构图:
Figure 3: The architecture of DNN
Addition Unit 反映的是1阶的特征。
内
积
单
元
反映的是2阶的组合特征对于预测结果的影响。
剩余11页未读,继续阅读
360 浏览量
472 浏览量
178 浏览量
230 浏览量
360 浏览量
2022-08-03 上传
2022-08-03 上传
159 浏览量
2021-05-17 上传

CyberNinja
- 粉丝: 29
- 资源: 297
 我的内容管理
展开
我的内容管理
展开







