Hadoop完全分布式环境搭建详解
需积分: 5 143 浏览量
更新于2024-07-05
收藏 3.06MB PDF 举报
"Hadoop完全分布式安装教程"
在大数据处理领域,Hadoop是一个不可或缺的开源框架,它主要用于存储和处理大规模数据。本教程将详细介绍如何在分布式环境中安装和配置Hadoop,以便搭建一个完整的Hadoop集群。
1. **准备工作**:
- 首先,你需要在计算机上安装虚拟机软件,例如VMware。这允许你在一台物理机器上模拟多台虚拟服务器,用于搭建Hadoop集群。下载并安装适合的VMware版本,如VMware Workstation Pro 15.5。
- 接下来,使用虚拟机软件创建新的虚拟机,并选择Linux作为操作系统,通常选择Ubuntu Server作为Hadoop的推荐操作系统。
2. **安装Ubuntu操作系统**:
- 在虚拟机中安装Ubuntu Server,按照屏幕提示进行操作,确保为虚拟机分配足够的资源,如处理器核心和内存。
3. **安装VMware Tools**:
- 安装VMware Tools能提高虚拟机的性能,例如改善显示效果和文件共享功能。
4. **设置共享文件夹**:
- 允许主机和虚拟机之间共享文件,这对于在虚拟机中部署Hadoop时传输文件非常有用。
5. **关闭防火墙**:
- Hadoop集群中的节点需要开放特定端口进行通信,关闭防火墙可以避免因安全策略导致的连接问题。
6. **安装SSH**:
- SSH(Secure Shell)用于远程登录,便于在集群中的不同节点间进行无密码登录,提高管理效率。
7. **安装Xshell**:
- Xshell是一款终端模拟器,用于远程管理和控制Linux服务器,提供命令行界面。
8. **设置静态IP**:
- 为每个虚拟机分配静态IP地址,确保集群中的节点间通信稳定。
9. **安装JDK**:
- Hadoop需要Java环境支持,所以必须安装Java Development Kit (JDK)。
10. **下载Hadoop并解压**:
- 从Apache官方网站下载Hadoop的最新稳定版本,将其解压缩到虚拟机的适当目录。
11. **克隆主机**:
- 创建更多虚拟机实例以构建Hadoop集群,这些实例基于已配置好的主节点进行克隆。
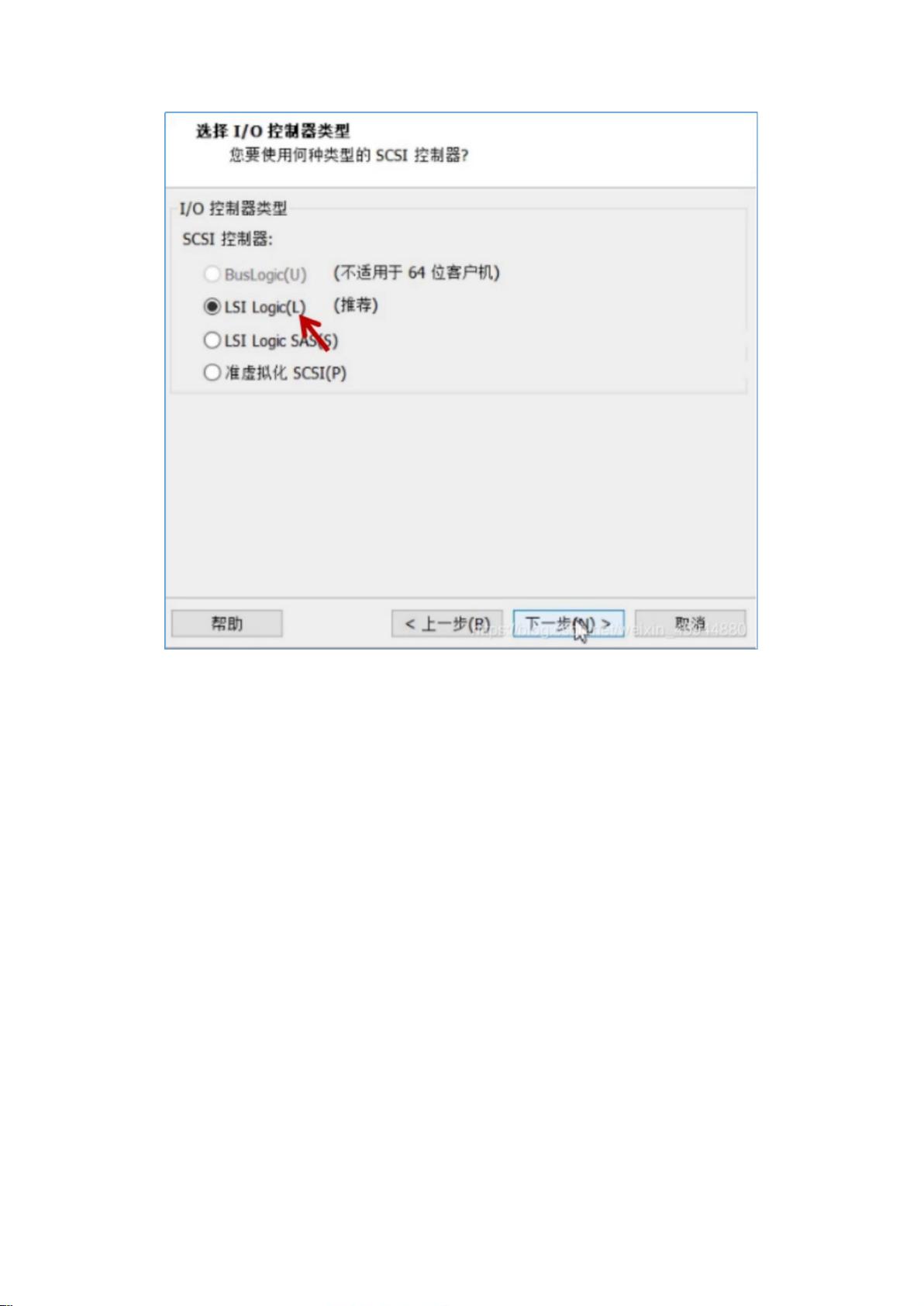
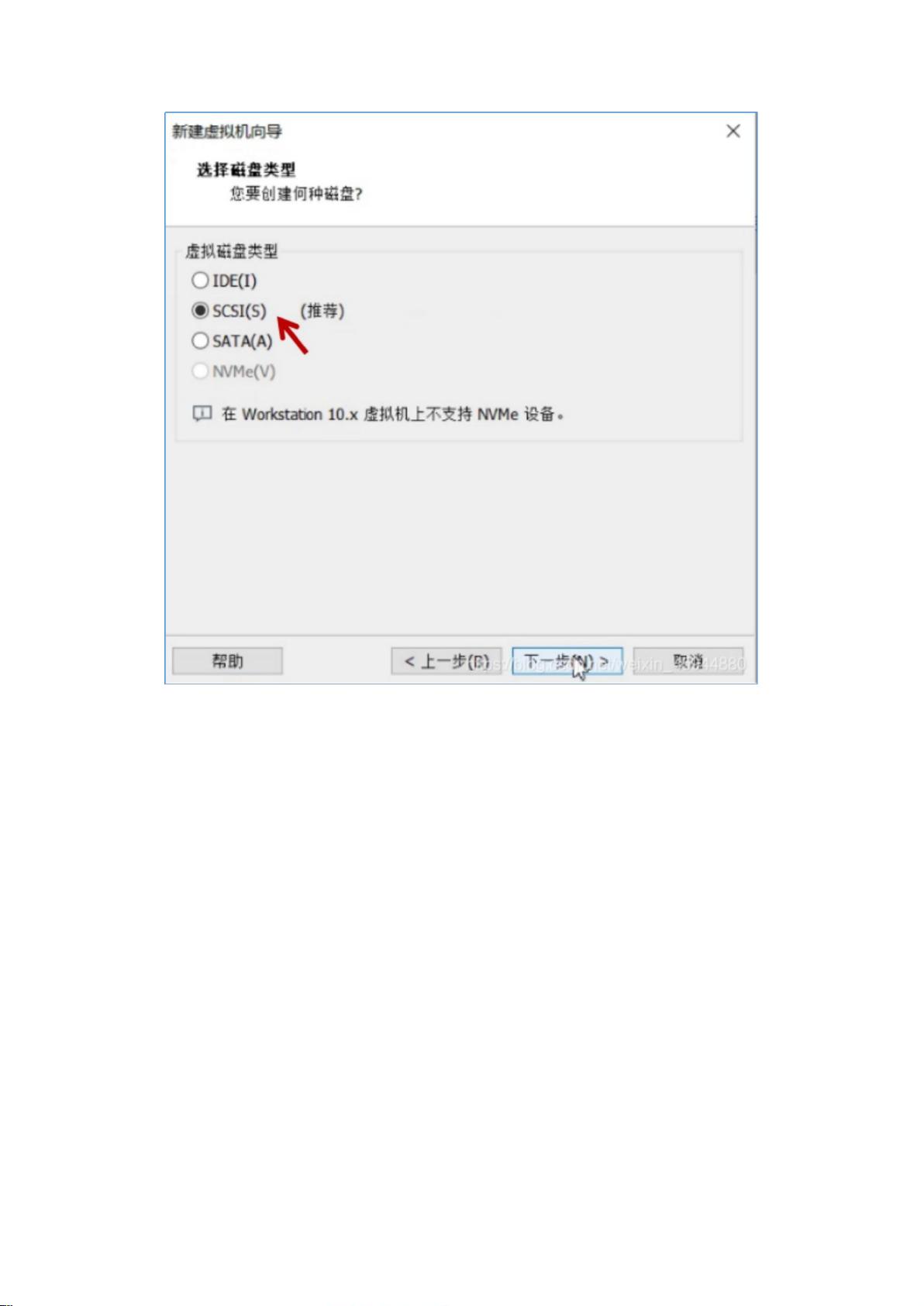
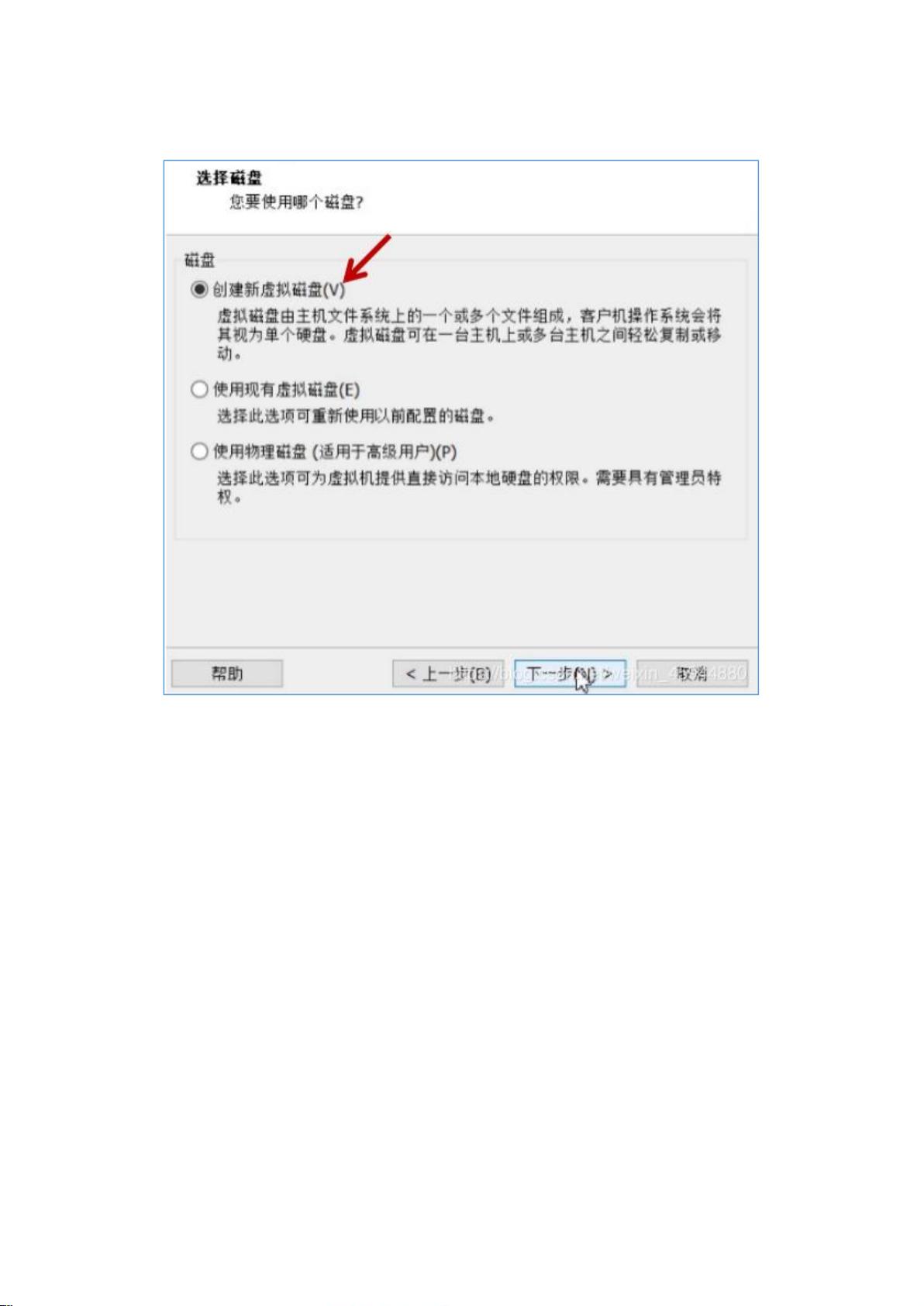
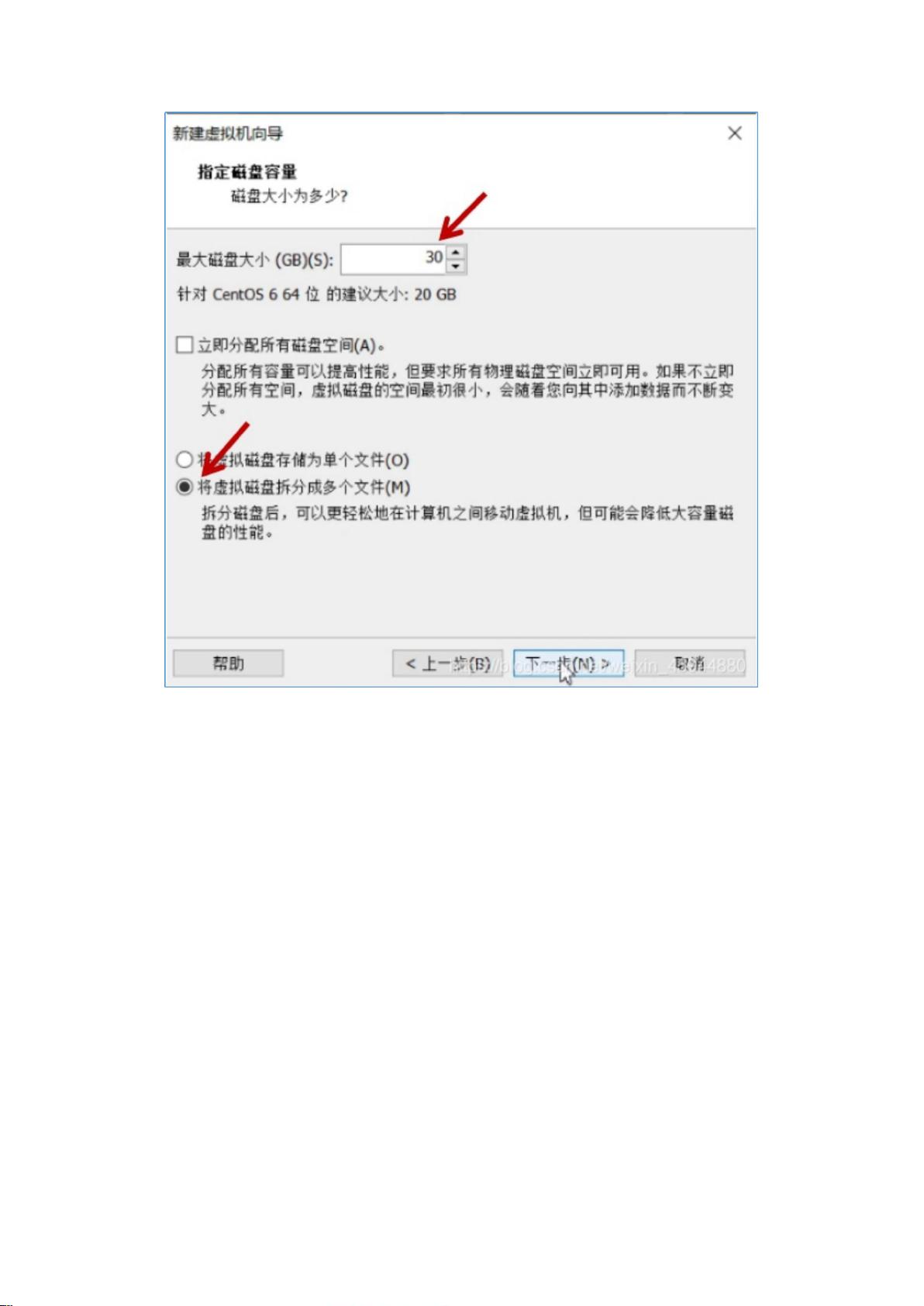
12. **完全分布式安装**:
- 包括一系列配置步骤,如修改主机名、映射IP地址与主机名、设置SSH免密登录、安装NTP服务以同步时间,以及配置Hadoop的配置文件(如`core-site.xml`, `hdfs-site.xml`, `mapred-site.xml`, `yarn-site.xml`等)。
13. **格式化HDFS**:
- 初始化Hadoop Distributed File System (HDFS),这是Hadoop数据存储的核心部分。
14. **启动Hadoop**:
- 启动Hadoop的相关守护进程,包括DataNode、NameNode、ResourceManager、NodeManager等。
15. **验证Hadoop进程**:
- 使用`jps`命令检查Hadoop进程是否正常运行。
16. **通过Web访问Hadoop**:
- 可以通过浏览器访问NameNode和ResourceManager的Web界面监控集群状态。
17. **测试Hadoop**:
- 运行简单的MapReduce任务,比如WordCount,以验证Hadoop集群是否能正确处理数据。
18. **停止Hadoop进程**:
- 当需要维护或更新集群时,需要正确地停止所有Hadoop进程。
整个Hadoop完全分布式安装过程需要耐心和细致,每一步都至关重要。遵循上述步骤,你将能够成功构建一个能够处理大数据的Hadoop集群。这个集群可以用于各种大数据应用,如数据分析、日志处理、机器学习等。
276 浏览量
2024-04-06 上传
129 浏览量
143 浏览量
129 浏览量
260 浏览量
2018-10-10 上传
151 浏览量

xvwen
- 粉丝: 2w+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Node.js基础代码示例解析
- MVVM Light工具包:跨平台MVVM应用开发加速器
- Halcon实验例程集锦:C语言与VB的实践指南
- 维美短信API:团购网站短信接口直连解决方案
- RTP转MP4存储技术解析及应用
- MySQLFront客户端压缩包的内容分析
- LSTM用于PTB数据库中ECG信号的心电图分类
- 飞凌-MX6UL开发板QT4.85看门狗测试详解
- RepRaptor:基于Qt的RepRap gcode发送控制器
- Uber开源高性能地理数据分析工具kepler.gl介绍
- 蓝色主题的简洁企业网站管理系统模板
- 深度解析自定义Launcher源码与UI设计
- 深入研究操作系统中的磁盘调度算法
- Vim插件clever-f.vim:深度优化f,F,t,T按键功能
- 弃用警告:Meddle.jl中间件堆栈使用风险提示
- 毕业设计网上书店系统完整代码与论文
