Kafka生产实践优化与部署:从100TPS到220TPS的提升
117 浏览量
更新于2024-09-01
收藏 148KB PDF 举报
本文档深入探讨了Kafka生产实践中的关键优化策略和实战经验。作者在处理一个高并发APP流量分析项目时,遇到了RDS性能瓶颈,决定引入Kafka作为数据缓冲层,以提升吞吐量。起初,通过单节点Kafka实现了100TPS的吞吐量,这表明Kafka在高并发场景下的优势。
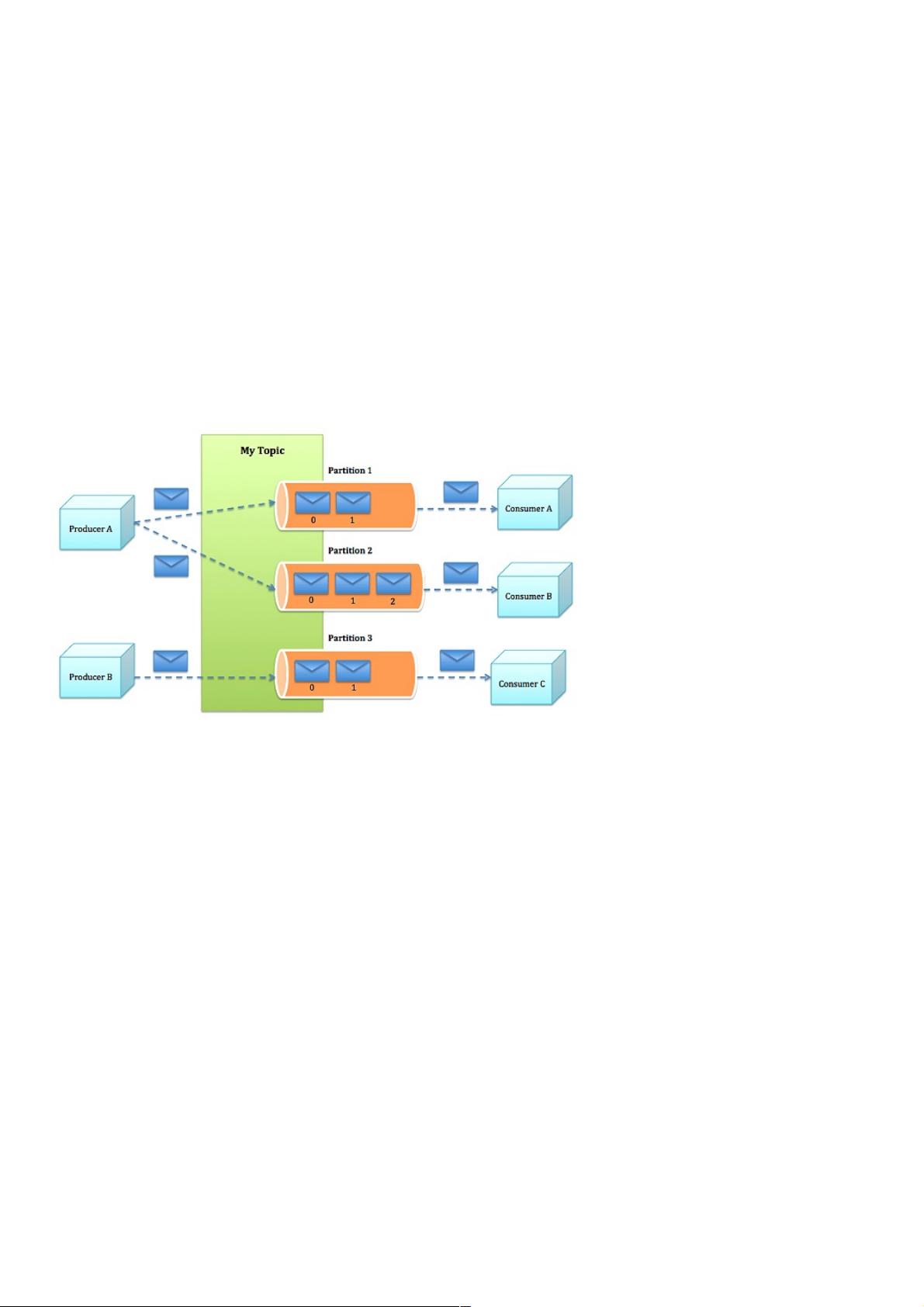
Kafka是一种分布式消息传递系统,其架构由生产者、主题(Topic)、分区(Partition)和消费者组成。文章首先介绍了Kafka的基本概念,包括其分布式架构和分区机制。每个主题可以被划分为多个分区,分区之间是并行处理的,确保消息的顺序性。一个分区通常由一个消费者实例消费,如果只有一个分区,系统的并发度就会受到限制。
作者着重强调了集群化的必要性,通过增加集群节点,可以显著提高系统的并发处理能力。分区的数量也是一个重要的调优因素,通过设置更多的分区,可以降低单个分区的负载,减少发送和确认消息时的等待时间,从而提升整体的吞吐量。
文章进一步讨论了作者对Kafka参数的调整过程,这可能涉及到了生产者和消费者的配置优化,例如调整batch大小、acks(确认模式)和fetch size等,这些设置直接影响到消息的发送效率和系统的稳定性。通过对参数的精细调优,作者最终将接口的吞吐量提升到了220TPS,这是一个显著的进步。
总结来说,这篇文档提供了Kafka在实际生产环境中的应用案例,涵盖了从问题识别、架构选择、参数调整到性能优化的全过程,对于有经验的开发者理解和优化分布式消息系统具有很高的参考价值。通过阅读这篇文章,读者可以了解到如何在高并发场景下利用Kafka实现高效的消息传递和数据处理。
kafka生产实践生产实践(详解详解)
下面小编就为大家带来一篇kafka生产实践(详解)。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起
跟随小编过来看看吧
1.引言引言
最近接触到一个APP流量分析的项目,类似于友盟。涉及到几个C端(客户端)高并发的接口,这几个接口主要用于C端数据的提
交。在没有任何缓冲的情况下,一个接口涉及到5张表的提交。压测的结果很不理想,主要瓶颈就在与RDS的交互。
一台双核,16G机子,单实例,jdbc最大连接数100,吞吐量竟然只有50TPS。
能想到的改造方案就是引入一层缓冲,让C端接口不与RDS直接交互,很自然就想到了rabbitmq,但是rabbitmq对分布式的支持比较
一般,我们的数据体量也比较大,所以我们借鉴了友盟,引入了kafka,Kafka是一种高吞吐量的分布式发布订阅消息系统,起初在不
做任何kafka优化的时候,简单地将C端提交的数据直接send到单节点kafka,就这样,我们的吞吐量达到了100TPS.还是有点小惊喜
的。
最近一段时间研究了一下kafka,对一些参数进行调整,目前接口的吞吐量已经达到220TPS,写这篇文章主要想记录一下自己优化和部
署经历。
2.kafka简介简介
kafka的结构图的结构图
这张图很好的诠释了kafka的结构,但是遗漏了一点,就是group的概念,我这里补充一下,一个组可以包含多个consumer对多个
topic进行消费,但是不同组的消费都是独立的。
也就是说同一个topic的同一条消息可以被不同组的consumer消费。
我这里的主要的优化途径就是将kafka集群化,多partition化,使其并发度更高。
集群化都很好理解,那什么是多partition?
partition是topic的一个概念,即对topic进行分组,不同partition之间的消费相互独立,并且有序。并且一个partiton只能被一个消费者
消费,所以咯,假如topic只有一个partition的话,那么消费者实例不能大于一个,那实例再多也没用,受限于kafka的partition。
上面都是讲消费,其实send操作也是一样的,要保证有序必然要等上一个发送ack之后,下一个发送才能进行,如果只有一个
partition,那send之后的ack的等待时间必然会阻塞下面一次send,设计多个partition之后,可以同时往多个partition发送消息,自然吞
吐量也就上去。
3.kafka集群的搭建以及参数配置集群的搭建以及参数配置
集群搭建集群搭建
准备两台机子,然后去官网(http://kafka.apache.org/downloads)下载一个包。通过scp到服务器上,解压进入config目录,编辑
server.config.
第一台机子配置(172.18.240.36):
broker.id=0 每台服务器的broker.id都不能相同
#hostname
host.name=172.18.240.36
#在log.retention.hours=168 下面新增下面三项
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
307 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38621312
- 粉丝: 4
- 资源: 934
 我的内容管理
展开
我的内容管理
展开







最新资源
- VOIP的配置资料1111111111111
- WindowsXP对宽带连接速度进行了限制,是否意味着我们可以改造操作系统,得到更快的上网速度
- myeclipse优化详解
- 多媒体与数字图像压缩技术
- 分页的JSP代码分页的JSP代码
- 面向对象系统设计循序渐进
- 小型游戏贪吃蛇的程序
- PIC 单片机的C 语言编程.pdf
- 第2代图像压缩技术回顾与性能分析.pdf
- 基于游程编码的分块交叉数字图像压缩算法.pdf
- 三星s3c2410数据手册
- OpenSceneGraph Quick Start__ Guide
- 快速成型中基于ST EP 的直接分层算法
- memcached中文学习文档
- 基于本体实现网页规则分类的方法
- EXT中文框架学习文档
