Ubuntu 14+ Hadoop 2.7 + Hive 安装全攻略
版权申诉
"虚拟机Ubuntu+Hadoop+hive安装教程"
该教程主要涵盖了在虚拟机环境中安装Ubuntu操作系统、Hadoop以及Hive的详细步骤。首先,我们从虚拟机的配置开始,通过VMware Workstation 10创建一个新的虚拟机,选择自定义配置,并指定为Linux的Ubuntu 64位系统。在虚拟机设置中,分配适当的资源如内存和磁盘空间,并设定网络连接模式为NAT,以便虚拟机能够联网。
接下来是Ubuntu的安装过程。启动虚拟机后,按照界面提示选择英文语言并安装Ubuntu。在安装过程中,会要求擦除磁盘并进行系统安装,同时设置地理位置、键盘布局以及用户账户和密码。安装完成后,系统会自动重启。
安装完毕后,为了方便虚拟机与主机之间的文件交互,需要安装VMware Tools。这可以通过虚拟机菜单中的“安装VMware Tools”选项来实现。将安装文件复制到临时目录,解压缩后进入解压后的文件夹,按照提示进行安装。VMware Tools的安装有助于改善图形性能和提供共享文件夹功能。
接下来是Hadoop的安装。Hadoop是一个分布式计算框架,用于处理和存储大量数据。在Ubuntu中,通常通过添加Hadoop的官方仓库,然后使用apt-get命令进行安装。这包括安装Hadoop的核心组件、HDFS、MapReduce和YARN等。安装完成后,需要配置Hadoop的环境变量,以及集群的配置文件如`core-site.xml`, `hdfs-site.xml`, 和 `yarn-site.xml`等,以设置数据节点、名称节点和其他相关参数。
最后是Hive的安装,Hive是一个基于Hadoop的数据仓库工具,可将结构化的数据文件映射为一张数据库表,并提供SQL查询功能。同样,通过添加Hive的仓库源,然后使用apt-get或编译源码的方式安装。安装后,需要配置Hive的环境变量,以及`hive-site.xml`配置文件,定义Hadoop的路径和其他相关设置。
整个教程的目标是搭建一个完整的Hadoop大数据处理环境,包括操作系统的安装、Hadoop集群的配置以及Hive的安装与设置。这对于学习和实践大数据处理技术是非常基础且重要的步骤。通过这个教程,用户能够掌握在虚拟机环境下构建这样的环境的方法,从而能够进行大数据相关的实验和开发工作。
默认所有参数,然后下一步:
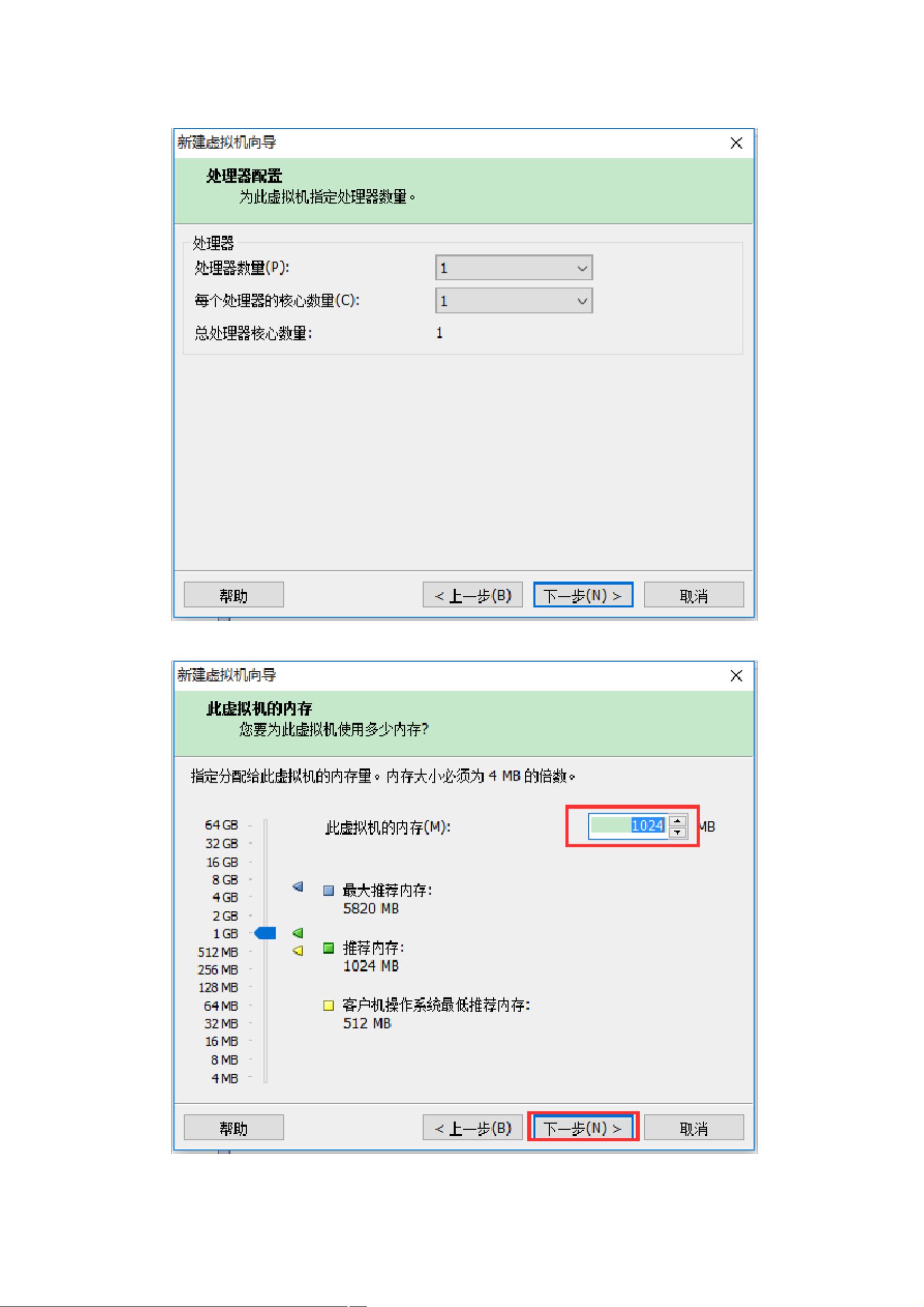
这里设置虚拟机的资源大小,默认:
剩余24页未读,继续阅读
171 浏览量
130 浏览量
159 浏览量
171 浏览量
290 浏览量
190 浏览量
154 浏览量
243 浏览量
2023-06-01 上传

春哥111
- 粉丝: 1w+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python大数据应用教程:基础教学课件
- Android事件分发库:对象池与接口回调实现指南
- C#开发的斗地主网络版游戏特色解析
- 微信小程序地图功能DEMO展示:高德API应用实例
- 构建游戏排行榜API:Azure Functions和Cosmos DB的结合
- 实时监控系统进程CPU占用率方法与源代码解析
- 企业商务谈判网站模板及技术源码资源合集
- 实现Webpack构建后自动上传至Amazon S3
- 简单JavaScript小计算器的制作教程
- ASP.NET中jQuery EasyUI应用与示例解析
- C语言实现AES与DES加密算法源码
- 开源项目实现复古游戏机控制器输入记录与回放
- 掌握Android与iOS异步绘制显示工具类开发
- JAVA入门基础与多线程聊天售票系统教程
- VB API实现串口通信的调试方法及源码解析
- 基于C#的仓库管理系统设计与数据库结构分析
