深入理解Hadoop集群:原理、拓扑与实现
PDF格式 | 1.38MB |
更新于2024-08-29
| 162 浏览量 | 举报
"看懂Hadoop集群原理与实现方式"
Hadoop是开源的大数据处理框架,其设计目标是处理和存储海量数据。理解Hadoop集群的原理与实现方式对于深入学习和应用Hadoop至关重要。Hadoop集群由不同角色的服务器构成,主要包括客户端、Masters节点和Slave节点。
客户端是用户与Hadoop集群交互的接口,它负责提交作业到集群,并在作业完成后获取结果。客户端并不参与实际的数据处理或存储,而是充当控制和通信的角色。
Masters节点是集群的核心组件,包括NameNode和JobTracker。NameNode是Hadoop分布式文件系统(HDFS)的元数据管理器,它维护文件系统的命名空间和文件块映射信息,监控所有DataNode的状态,并处理客户端的所有文件系统操作请求。JobTracker则是MapReduce框架的控制器,它负责调度作业的Mapper和Reducer任务,监控TaskTracker的执行情况,并处理作业的生命周期管理。
Slave节点包含两种类型:DataNode和TaskTracker。每个DataNode是HDFS的基本存储单元,它们存储实际的数据块,并负责与NameNode通信,报告存储状态和执行数据块的读写操作。TaskTracker运行在每个Slave节点上,接收JobTracker的指令,执行Mapper和Reducer任务,同时向JobTracker汇报任务进度和状态。
在Hadoop集群的部署中,小型集群可能采用单服务器多角色的方式,比如NameNode和JobTracker可以部署在同一台服务器上。然而,对于大型集群,为了保证高可用性和性能,应将这些关键服务分布在不同的物理机器上。例如,NameNode对内存需求较高,所以不建议与SecondaryNameNode合署,后者主要负责周期性地备份NameNode的元数据,以防NameNode故障。
集群的网络拓扑通常是基于机架设计的,每个机架上有一个交换机连接所有服务器,然后通过上行链路将不同机架连接成一个整体。这种设计有利于减少内部网络通信的延迟,提高数据传输效率。网络带宽是决定集群性能的关键因素,特别是在大规模数据处理时,必须确保有足够的带宽支持数据在节点间的流动。
在实际生产环境中,Hadoop通常运行在Linux服务器上,以充分利用其性能和稳定性。虽然可以在虚拟环境中学习Hadoop,但虚拟化环境可能限制了性能,不适合用于高性能计算和大数据处理的生产集群。
理解Hadoop集群的原理与实现涉及到Hadoop的角色分配、通信机制、网络拓扑和资源管理等多个方面。掌握这些知识对于构建、管理和优化高效稳定的Hadoop集群至关重要。
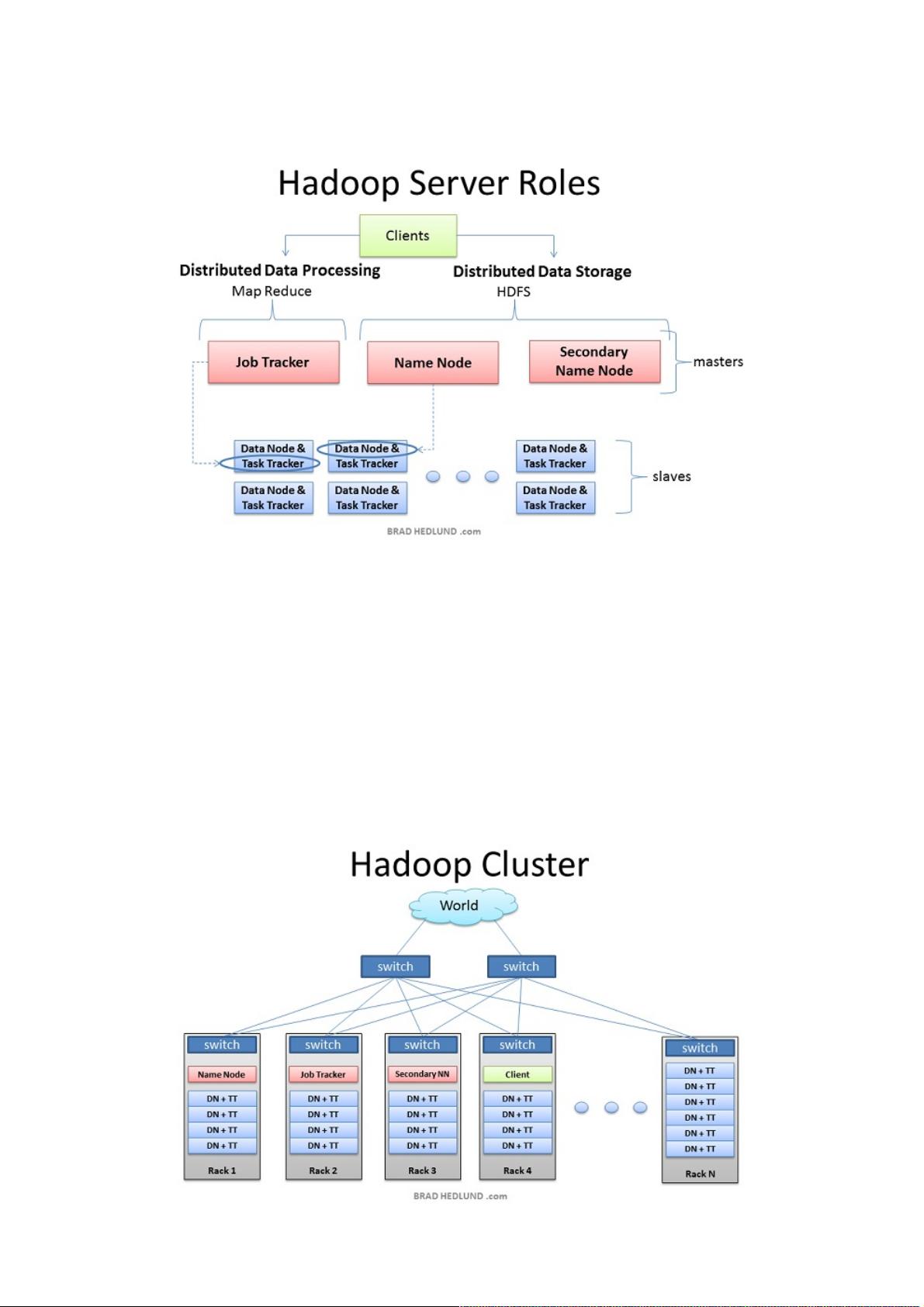
看懂看懂Hadoop集群原理与实现方式集群原理与实现方式
文章让大家通过拓扑图的形式直观的了解 Hadoop 集群是如何搭建、运行以及各个节点之间如何相互调用、每个节点是如何工
作以及各个节点的作用是什么。明白这一点将会对学习 Hadoop 有很大的帮助。首先,我们开始了解 Hadoop 的基础知识,以
及 Hadoop 集群的工作原理。
在Hadoop部署中,有三种服务器角色,他们分别是客户端、Masters节点以及Slave 节点。Master 节点,Masters 节点又称主
节点,主节点负责监控两个核心功能:大数据存储(HDFS)以及数据并行计算(Map Reduce)。其中,Name Node 负责监
控以及协调数据存储(HDFS)的工作,Job Tracker 则负责监督以及协调 Map Reduce 的并行计算。 而Slave 节点则负责具
体的工作以及数据存储。每个 Slave 运行一个 Data Node 和一个 Task Tracker 守护进程。这两个守护进程负责与 Master 节
点通信。Task Tracker 守护进程与 Job Tracker 相互作用,而 Data Node 守护进程则与 Name Node 相互作用。
所有的集群配置都会存在于客户端服务器,但是客户端服务器不属于 Master 以及 Salve,客户端服务器仅仅负责提交计算任
务给 Hadoop 集群,并当 Hadoop 集群完成任务后,客户端服务器来拿走计算结果。在一个较小的集群中(40个节点左
右),可能一台服务器会扮演多个角色,例如通常我们会将 Name Node 与 Job Tracker安置在同一台服务器上。(由于
Name Node对内存开销非常大,因此不赞成将 Name Node 与 Secondary Name Node 安置在同一台机器上)。而在一个大
型的集群中,请无论如何要保证这三者分属于不同的机器。
在真实的集群环境中,Hadoop 最好运行在 Linux 服务器上。当然,Hadoop 也可以运行在虚拟机中,但是,这仅仅是用来学
习的一种方法,而不能将其用在生产环境中。
上图是一个典型的 Hadoop 集群架构。这张图中,Hadoop 集群以机架为单位存在(而不是刀片机),而每个机架顶部都会有
一个交换机通过千兆网与外部关联,如果你的服务器比较给力,请确保带宽足够数据的传输以免带宽影响运算(例如万兆以太
下载后可阅读完整内容,剩余9页未读,立即下载
相关推荐





12 浏览量

weixin_38744778
- 粉丝: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- Vue.js波纹效果组件:Vue-Touch-Ripple使用教程
- VHDL与Verilog代码转换实用工具介绍
- 探索Android AppCompat库:兼容性支持与Java编程
- 探索Swift中的WBLoadingIndicatorView动画封装技术
- dwz后台实例:全面展示dwz控件使用方法
- FoodCMS: 一站式食品信息和搜索解决方案
- 光立方制作教程:雨滴特效与呼吸灯效果
- mybatisTool高效代码生成工具包发布
- Android Graphics 绘图技巧与实践解析
- 1998版GMP自检评定标准的回顾与方法
- 阻容参数快速计算工具-硬件设计计算器
- 基于Java和MySQL的通讯录管理系统开发教程
- 基于JSP和JavaBean的学生选课系统实现
- 全面的数字电路基础大学课件介绍
- WagtailClassSetter停更:Hallo.js编辑器类设置器使用指南
- PCB线路板电镀槽尺寸核算方法详解
