Tensorflow入门:搭建神经网络详解与训练机制
175 浏览量
更新于2024-08-29
收藏 554KB PDF 举报
本文是一篇详细教程,旨在教授读者如何使用Tensorflow这个强大的深度学习框架来构建神经网络。Tensorflow是谷歌出品的工具,它简化了神经网络的实现过程,使得初学者能够快速入门。神经网络是计算机科学中的核心概念,它模仿人脑的神经元网络结构,通过大量节点(神经元)的连接和计算来处理复杂的输入输出关系。
文章首先介绍了神经网络的基本概念,包括其工作原理:神经元通过连接形成多层结构,如输入层、隐藏层和输出层,每层负责不同的任务。输入层接收外部信息,隐藏层负责信息的处理和特征提取,输出层则根据输入判断或预测结果。神经网络通过大量数据的训练进行学习,通过比较预测结果与实际答案的差异,调整神经元的权重,从而逐渐优化模型。
在Tensorflow中,作者强调了使用激活函数的重要性,它决定了神经元的响应和信息传递。例如,当输入是一只猫的图片时,只有与猫相关的特征会被激活,而其他不相关的特征会被抑制。如果预测错误,错误信息会反向传播,调整神经元参数,使其在未来更倾向于正确识别。
文章还提到了神经网络的应用广泛性,可以用于分类任务和拟合问题,例如图像识别、语音识别或自然语言处理等。学习者可以通过阅读本文并实践Tensorflow提供的代码示例,逐步掌握神经网络的搭建和训练流程。
这篇教程不仅讲解了神经网络的基础理论,还提供了实用的Tensorflow操作指南,非常适合想要入门神经网络领域的读者参考和学习。对于那些希望深入理解神经网络工作原理,并能实际运用到项目中的学习者来说,这是一份难得的资源。
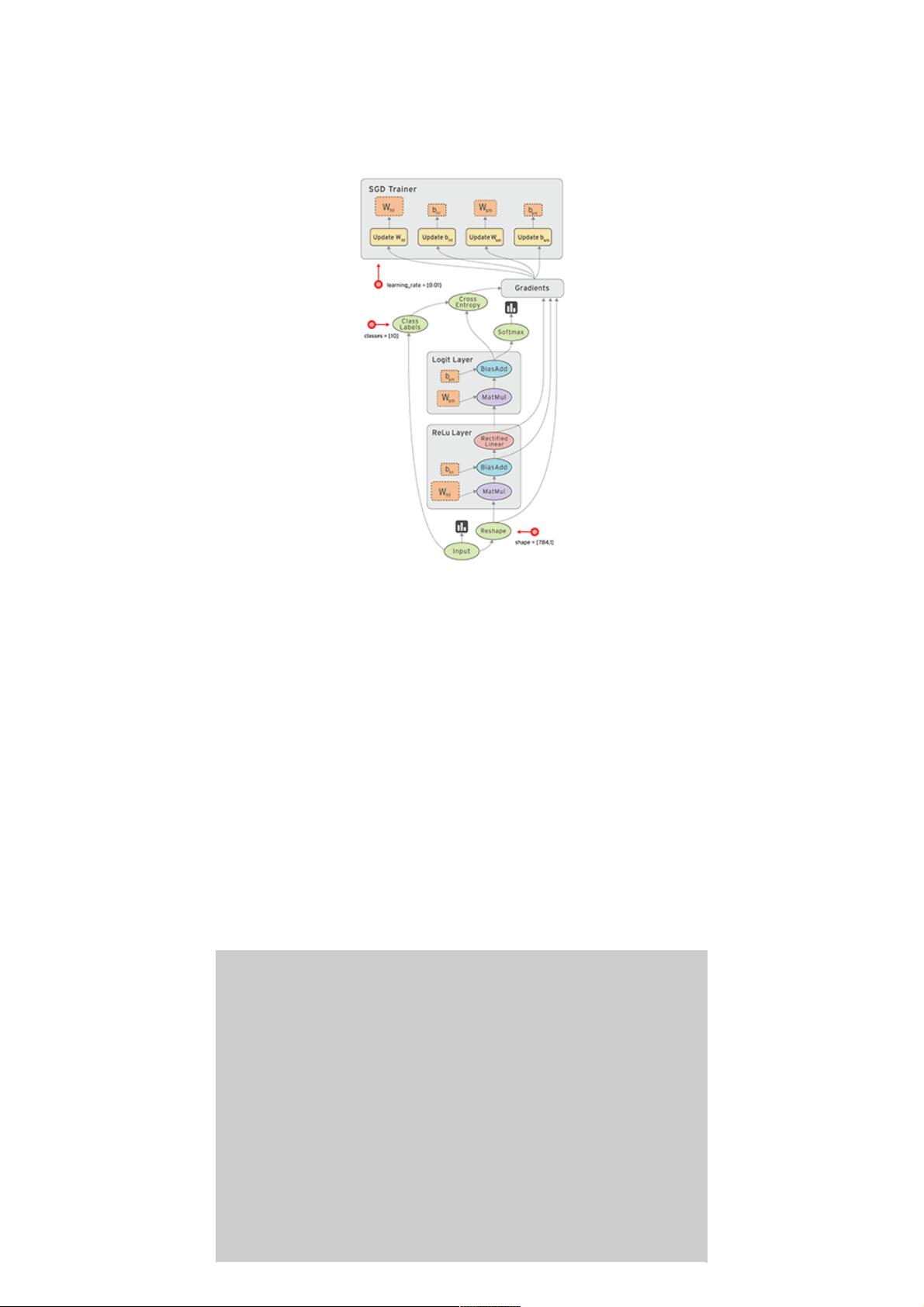
那我们要做的就是要建立一个这样的结构,然后把数据喂进去。
把数据放进去后它就可以自己运行,TensorFlow 翻译过来就是向量在里面飞。
这个动图的解释就是,在输入层输入数据,然后数据飞到隐藏层飞到输出层,用梯度下降处理,梯度下降会对几个参数进行更
新和完善,更新后的参数再次跑到隐藏层去学习,这样一直循环直到结果收敛。
tensors_flowing.gif
今天一口气把整个系列都学完了,先来一段完整的代码,然后解释重要的知识点!
1. 搭建神经网络基本流程
定义添加神经层的函数
1.训练的数据
2.定义节点准备接收数据
3.定义神经层:隐藏层和预测层
4.定义 loss 表达式
5.选择 optimizer 使 loss 达到最小
然后对所有变量进行初始化,通过 sess.run optimizer,迭代 1000 次进行学习:
剩余10页未读,继续阅读
2023-05-13 上传
2021-01-07 上传
点击了解资源详情
2024-06-17 上传
2022-08-03 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38654315
- 粉丝: 5
- 资源: 962
 我的内容管理
展开
我的内容管理
展开







最新资源
- PyPI 官网下载 | pipython3-0.1.3.tar.gz
- Preclipse-开源
- FPGA通用SPI驱动程序
- iugi:使用CodeSandbox创建
- cool-partial-dump:mongoosemongoDB的部分转储
- gatling:将现代负载测试作为代码
- test-prj:测试项目
- pandas_flavor-0.1.0.tar.gz
- 在各种公开可用的对话数据集上训练和评估AI模型的框架。-Python开发
- Focuser-crx插件
- Bakery:使用HTML,Bootstrap和PHP为TPA类制作的网站
- pandas_flavor-0.5.0.tar.gz
- 注册表同步:从远程npm注册表同步选定的软件包
- flow:在PyTorch中规范化流程
- 参考资料-项目投资收益测算模板全1451484626.zip
- 【IT十八掌徐培成】Java基础第02天-02.字节-负数表示-补码-128计算.zip
