文库下载技术揭秘:从Flash到文档解析
"本文档主要探讨了网络文库下载的基本原理,通过解析文档的源代码和Flash对象,展示了如何制作类似豆丁、百度文库的下载工具,适用于开发者自行开发其他网站文库的下载器。内容包括对Open文档的实例分析,解析HTML中的关键参数,以及Flash对象的查找和利用。"
文库下载原理通常涉及到以下几个关键步骤:
1. **文档信息获取**:在网页源代码中,关键信息如文档的唯一标识符(如wgDocKey)、标题(wgDocTitle)以及Flash文档的路径(fpath)等都存储在JavaScript脚本中。例如,在Open文档的示例中,这些信息被嵌入在`<script>`标签内。
2. **Flash地址解析**:许多文库使用Flash技术来显示文档,以防止直接下载。我们需要找到加载Flash文档的URL,这可以通过解析页面上的JavaScript文件(如`view.js`)来完成。在JavaScript中,Flash对象的相关参数被定义,这些参数用于在Flash播放器中加载和展示文档。
3. **Flash数据抓取**:一旦有了Flash的地址,我们可以使用网络请求工具(如curl或Python的requests库)下载Flash文件的数据。这些数据通常是二进制流,包含文档的实际内容。
4. **数据转换**:下载的Flash数据需要进一步处理才能恢复成可读的文档格式。这可能涉及到解码、解析Flash的内部格式,并将其转换为PDF、DOCX或其他常见格式。有时,Flash数据可能包含分页信息,需要正确重组。
5. **实现下载器**:理解了上述原理后,开发者可以编写程序自动执行这些步骤,实现文库文档的自动化下载。这可能涉及到网页爬虫技术,使用正则表达式或DOM解析库来提取关键信息,以及使用如BeautifulSoup、PyFlasher等库处理Flash数据。
6. **兼容性处理**:不同的文库平台可能采用不同的保护机制,因此,一个通用的文库下载器需要能适应多种情况,包括但不限于处理JavaScript加密、动态加载内容、登录验证等复杂情况。
7. **法律与道德考虑**:在进行文库下载时,必须遵守版权法和网站的使用条款。未经授权的批量下载可能侵犯作者权益,因此,这样的工具应谨慎使用,最好仅用于个人学习和研究目的。
文库下载原理主要依赖于解析网页结构、理解和操作Flash内容,以及将原始数据转换为可读格式。通过掌握这些技术,开发者可以创建自定义的下载工具,但同时也需要注意遵守互联网的使用规则和尊重他人的知识产权。
邮箱:xianghuaizi@126.com 个人原创
文库下载原理分析
当前网络上有很多文库,我们经常没有积分去下载这些资源。但是我们能
够在线看到这些资料,那我们怎么下载这些预览的资料呢?
既然可以预览,那我们就可以找到一个 地址,下载这个地址的数据,
再经过一系列的转化,就能生产我们想要的资料了。
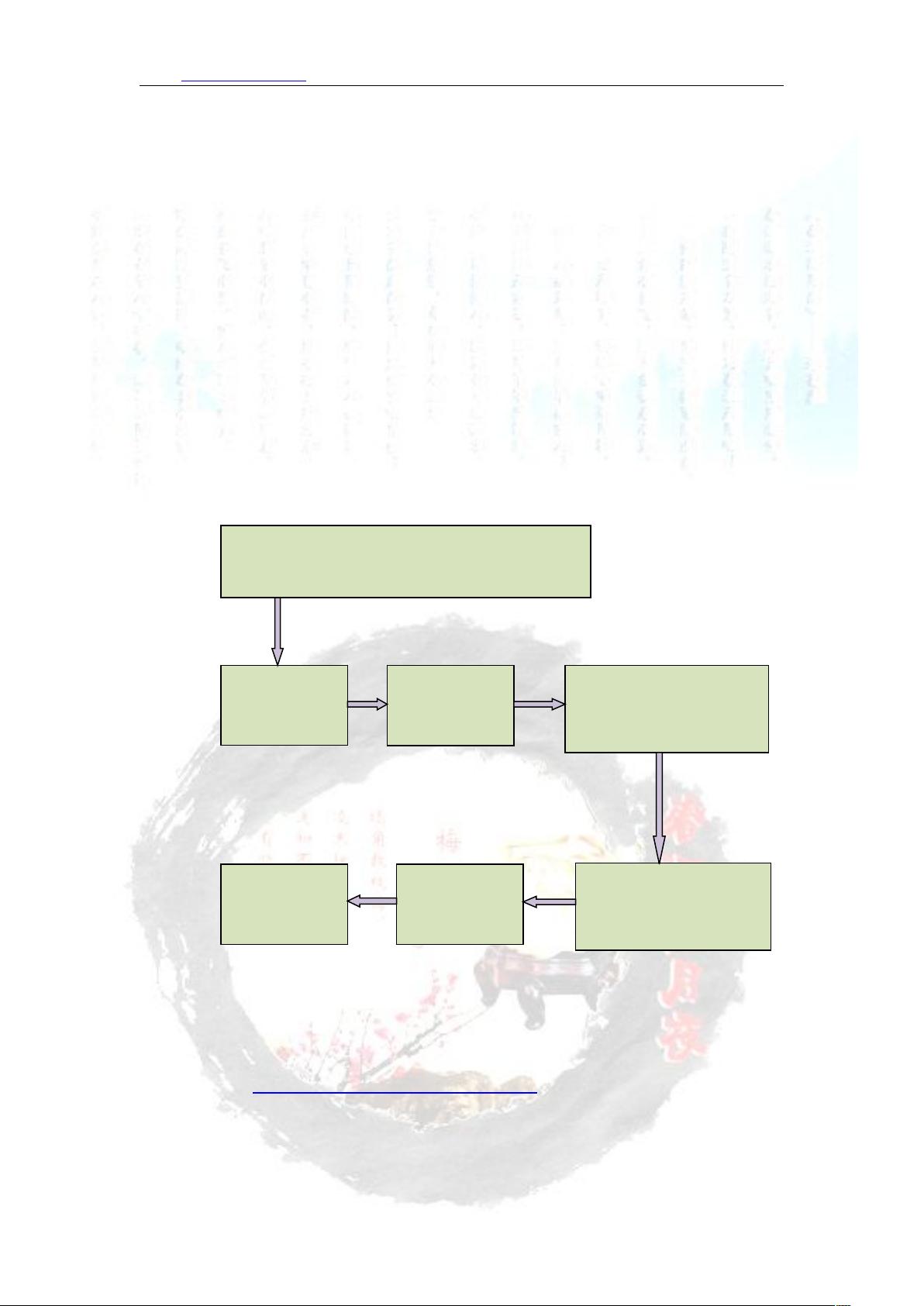
可以概括原理如下图:
下面我们就分析一个简单的文档:
http://www.open-open.com(Open 文档)
首先是 文档下载地址解析,打开一个 文档,右击查看源代码。
1
查 找 Flash 对 象 , 网 页 中 直 接 或 JS 中 定 义
SWFOBJ ,查找需要的 ashvar 和文档信息
下载该网页指
出的标准 swf
使用工具分析
标准 swf 内容
使用 ashvar 的名称搜索
swf 信 息 , 找 到 可 疑 地
方,构建数据源地址
下 载 数 据 , 直 接 得 到
swf 或继续分析标准 swf
文件,得到转化 swf 的
方法
SWFToImage
转化为 jpg
pdib 转 化 为
pdf
下载后可阅读完整内容,剩余3页未读,立即下载
589 浏览量
115 浏览量
2116 浏览量
226 浏览量
102 浏览量
2018-12-31 上传
2012-10-23 上传
2014-03-13 上传
2011-10-06 上传

湘淮子
- 粉丝: 135
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- 实战Visual C#数据库编程
- windows xp 故障恢复台
- OpenGL.Extensions.-.Nvidia
- ibatis 开发指南.pdf
- 悟透JavaScript
- ASP.NET常用代码
- Struts in Action 中文版.pdf
- 注册电气工程师2009年考试大纲
- 网络银行的现状及发展策略
- WCDMA系统网络规化技术
- EJB3.0(PDF)电子书
- Ajax3D-SIGGRAPH2006幻灯片Ajax3D The Open Platform for Rich 3D Web Applications.pdf
- C# C# C#
- TD-SCDMA通信系统呼叫处理详细过程
- oracle 与db2比较
- 线形代数同济第四版答案
