PyTorch深度解析:核心开发者揭示内部机制
4 浏览量
更新于2024-07-15
1
收藏 2.89MB PDF 举报
"PyTorch 内部机制,核心开发者全面解读"
PyTorch是当今广泛使用的深度学习框架之一,尤其因其动态计算图和易用性而受到开发者青睐。本文由PyTorch的核心开发者Edward Z. Yang撰写,旨在帮助那些已经使用PyTorch但对其实现细节感到困惑的开发者深入了解其内部工作原理。
首先,我们要讨论的是PyTorch的核心数据结构——张量。张量是多维数组,可以存储各种标量类型的数据,如浮点数或整数。它们的维度和数据类型(dtype)定义了张量的形状和内容。张量不仅包含数据,还有元数据,如步幅(stride)、形状(shape)、布局(layout)和设备(device),这些信息对于高效地在内存中存储和操作张量至关重要。步幅描述了在内存中访问张量的下一个元素所需的步长,这对于理解和优化张量操作的性能非常关键。
PyTorch的另一个关键特性是自动微分(autograd),它使得计算梯度变得简单,这是训练神经网络必不可少的部分。在张量库中,每个操作都有对应的梯度算子,当启用autograd时,这些算子会记录在计算图中,以便于反向传播计算梯度。虽然在纽约聚会的演讲中这部分内容被略过,但在本文中,Edward会详细解释autograd的工作机制,包括如何编写自定义的autograd函数和扩展点。
在深入到张量库的C++实现时, Edward还会探讨如何利用扩展点来定制张量的行为,例如添加新的运算符或数据类型。此外,他还涵盖了布局和设备的概念,这对于理解如何在CPU和GPU之间有效地移动数据以及如何利用CUDA进行加速至关重要。
第二部分,Edward将引导读者了解实际编写PyTorch代码时需要注意的细节。他将讨论如何在autograd代码中导航,识别关键部分,并介绍编写高效核(kernel)的方法。核是执行特定计算的基本单元,如矩阵乘法,它们通常在底层硬件级别上实现,以实现最佳性能。
这篇文章为PyTorch的高级用户提供了深入洞察,帮助他们理解框架的底层机制,从而能够更有效地利用PyTorch进行深度学习开发,甚至为PyTorch社区做出贡献。通过理解张量的内部结构、autograd的工作原理以及如何优化代码,开发者可以提高模型的效率,解决性能瓶颈,并为PyTorch的未来发展提供有价值的见解。
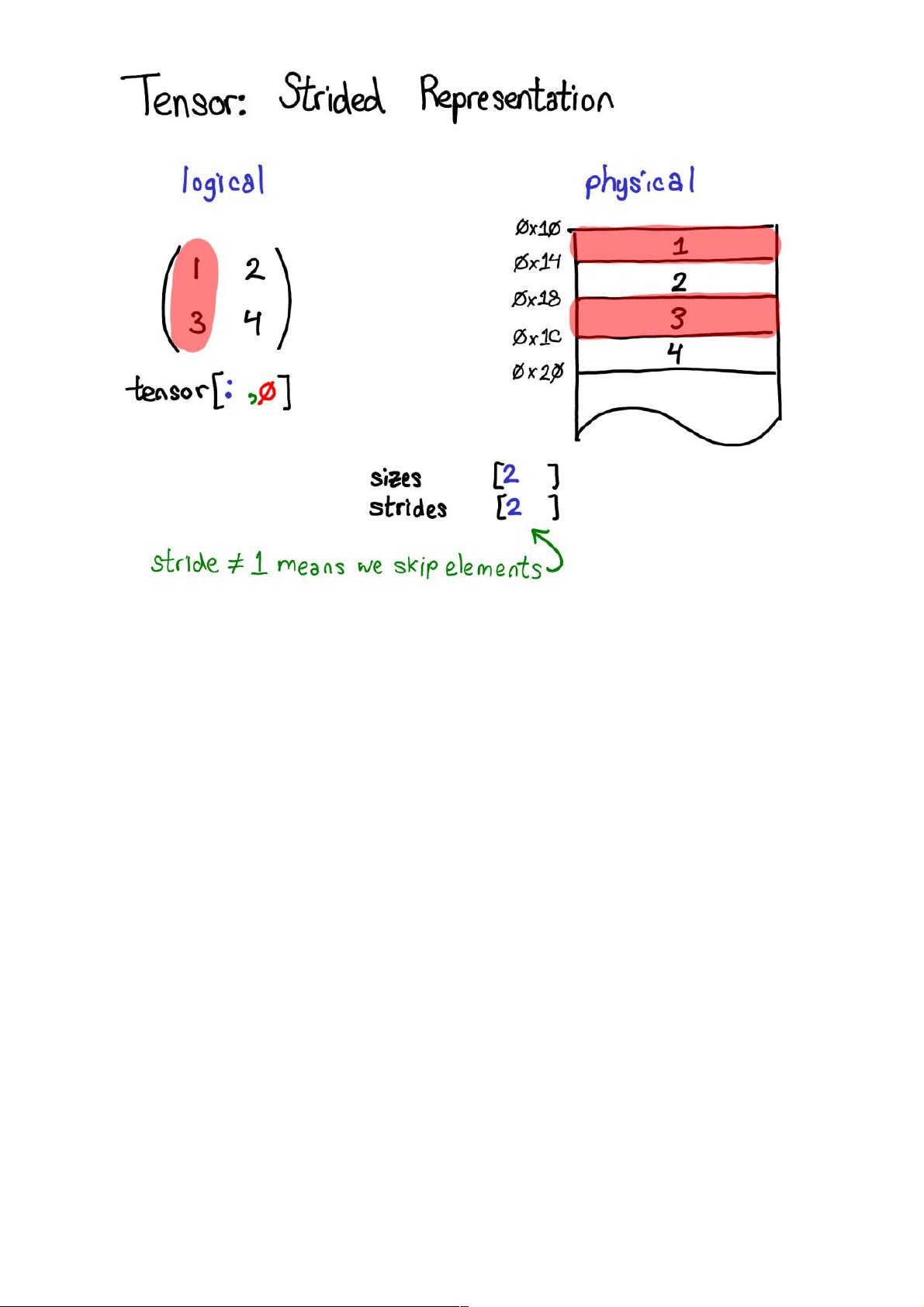
当我们查看物理内存时,可以看到该列的元素不是相邻的:两者之间有一个元素的间隙。步幅在这里就大显神威了:我们不再将一个元素与下一个
元素之间的步幅指定为 1,而是将其设定为 2,即跳两步。(顺便一提,这就是其被称为「步幅(stride)」的原因:如果我们将索引看作是在布局
上行走,步幅就指定了我们每次迈步时向前多少位置。)
步幅表示实际上可以让你表示所有类型的张量域段;如果你想了解各种不同的可能做法,请参阅 https://ezyang.github.io/stride-
visualizer/index.html
我们现在退一步看看,想想我们究竟如何实现这种功能(毕竟这是一个关于内部机制的演讲)。如果我们可以得到张量的域段,这就意味着我们必
须解耦张量的概念(你所知道且喜爱的面向用户的概念)以及存储张量的数据的实际物理数据的概念(称为「存储(storage)」):
剩余28页未读,继续阅读
2023-10-18 上传
2020-10-07 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38719635
- 粉丝: 3
- 资源: 971
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
