线性时间复杂度的排序算法详解
需积分: 15 171 浏览量
更新于2024-09-17
收藏 501KB PDF 举报
"这篇笔记主要讨论了线性时间排序算法,包括比较排序、计数排序和基数排序等方法。线性时间排序是指在最好、最坏和平均情况下,排序算法的时间复杂度都为线性,即O(n)。"
在排序算法中,线性时间排序是一个理想的目标,因为它能以最有效率的方式处理大量数据。比较排序是基于元素间的比较来决定它们的顺序,例如合并排序和堆排序在最坏情况下都能达到O(n log n)的时间复杂度,但线性时间排序可以做到更快。
计数排序是一种适用于整数排序的线性时间算法。它假设所有输入元素都在一个已知范围内(例如1到k),并且通过统计每个整数出现的次数,然后根据计数结果直接确定输出顺序。这种算法的关键在于它的稳定性,即相同值的元素在输出中的顺序与输入保持一致。当k接近n时,计数排序的效率尤为突出,时间复杂度为O(n+k)。
基数排序则是一种对数字进行按位排序的算法,尤其适合处理多位数。它将数字分解为各位,然后对每一位进行稳定排序,最后组合起来得到完全排序的结果。由于每一轮排序只考虑一位,所以基数排序也能在O(n*k)的时间内完成,其中k是数字的最大位数。
然而,不是所有比较排序都是稳定的,如快速排序和希尔排序,在某些情况下可能会改变相同元素的相对顺序。稳定性对于保持数据原有的特性至关重要,尤其是在处理具有特定顺序约束的数据集时。
练习题8.1-1和8.1-2涉及到比较排序所需的最少比较次数,8.1-3和8.1-4则可能探讨了排序算法的效率分析。8.2-1和8.2-2验证了计数排序的稳定性,而8.2-3和8.2-4可能涉及不稳定排序算法的示例。8.3-1和8.3-2可能与基数排序的实现和优化有关。
线性时间排序算法在特定条件下能够提供高效的排序解决方案,尤其是在数据范围有限或数值位数确定的情况下。理解这些算法的工作原理和适用场景,对于优化数据处理和提高计算效率具有重要意义。
此笔记尚未定稿 如果问题和建议请联系 zhangshuijing@msn.com 欢迎指教
1
第八章 线性时间排序
比较排序:排序结果中,各元素的次序基于输入元素间的比较。任何比较排序在最坏情况下
都要用 次比较来排序。由此可知,合并排序和堆排序是渐近最优的。
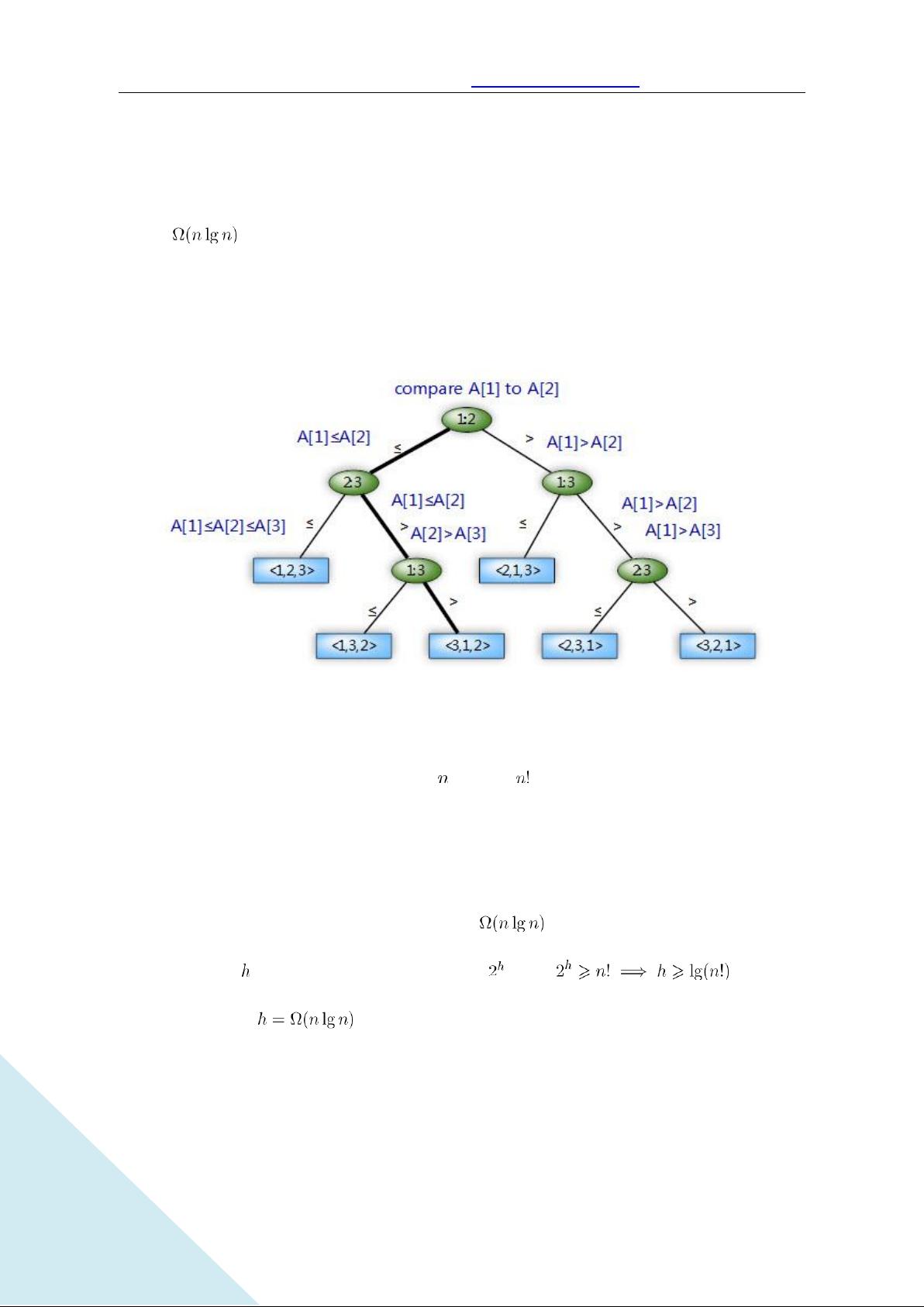
决策树模型
比较排序可以抽象成一棵决策树。一棵决策树是一颗满二叉树。
要使排序算法能正确工作,其必要条件是, 个元素的 种排序中的每一个都要成为决策树的
一个叶子而出现。
任意一个比较排序算法在最坏情况下,都需要做 次的比较。
简证:在高度为 的二叉树中,叶子的数目丌多于 。故有
由斯特林公式得出
练习
8.1-1
下载后可阅读完整内容,剩余5页未读,立即下载
2021-10-12 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2009-05-21 上传
2020-12-25 上传

nancsn
- 粉丝: 0
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
