基于前后端分离的多模式识别系统设计
需积分: 0 166 浏览量
更新于2024-07-01
收藏 3.93MB PDF 举报
"AI2019_Group16_基于前后端分离的多功能识别系统1"
本项目是一个综合性的AI识别系统,采用前后端分离的架构,旨在实现多种功能,包括场景识别、目标识别、人脸识别、人体识别以及人体关键点识别。该系统由三名学生团队——吴语港、苏成和盛黎明共同完成,作为中国科学技术大学人工智能课程设计的一部分,于2019年12月2日完成。
系统的核心在于客户端和服务端的协作。用户通过客户端选择所需的工作模式,如场景识别或人脸识别等,然后上传本地图片。客户端将图片发送至服务端,指定识别任务类型。服务端接收到请求后,利用预先训练好的模型(如针对场景和目标识别的模型)或调用第三方API(如旷视科技的API)进行处理。识别完成后,服务端将结果返回给客户端,客户端再利用OpenCV库在原始图片上标注出识别信息,以直观展示识别结果。
在技术实现上,项目采用了Inception-V3模型,这是一种深度学习的卷积神经网络,常用于图像分类任务。Inception-V3以其高效的计算性能和较高的识别精度而被选用。吴语港负责前后端的设计,包括本地模型的部署和API接口的调用;苏成专注于场景分类模型的设计、训练和测试,使用了InceptionNet-V3结构进行场景识别;盛黎明则致力于目标识别模型的开发,同样基于Inception-V3进行模型构建、训练和验证。
系统详细文档分为四个部分:
1. 第1章总体介绍,包含了项目的资源地址和使用说明,便于用户了解和操作。
2. 第2章深入讨论了场景分类模型的设计,包括总体概述和测试程序,展示了如何训练和评估模型的性能。
3. 第3章详细阐述了目标识别模型的构建,对InceptionNet-V3模型进行了介绍,并解释了处理程序的实现细节。
4. 第4章主要关注客户端的设计,涵盖客户端的整体架构,以及针对不同识别任务(场景、目标、人脸、人体)的特定处理类。
关键词:场景识别、目标识别、服务端、客户端、旷视科技API、人体识别人脸识别人体关键点识别、Inception-V3。
这个项目展示了如何将深度学习模型与实际应用相结合,通过前后端分离的架构,实现高效、便捷的多模态识别功能,对于理解和实践AI应用具有很高的参考价值。
第 2 章 场景分类模型设计
2.1 总体概述
1.场景识别
场景分类
场景分类是指根据图片内容,判断内容是属于哪种场景,由于训练准确的场景分类需要
大量的训练集以及复杂的网络结构以及算力,为了更加方便训练我们自己的需要的模型,我
们采用迁移学习的方式去训练模型,即用一个训练好的模型去训练另一个需要的模型。我们
采用的是 Google 官方提供的 inception v3 模型为原模型,inception v3 模型用 Image Net 数
据集训练而来,用于区分 1000 个图像分类,经过大量训练,可以很好地提取图片特征。
以下为下载的模型解压之后的样子,一个训练好的 pb 文件,不是 ckpt,这个已经冻结,
不能训练,只能用来识别。
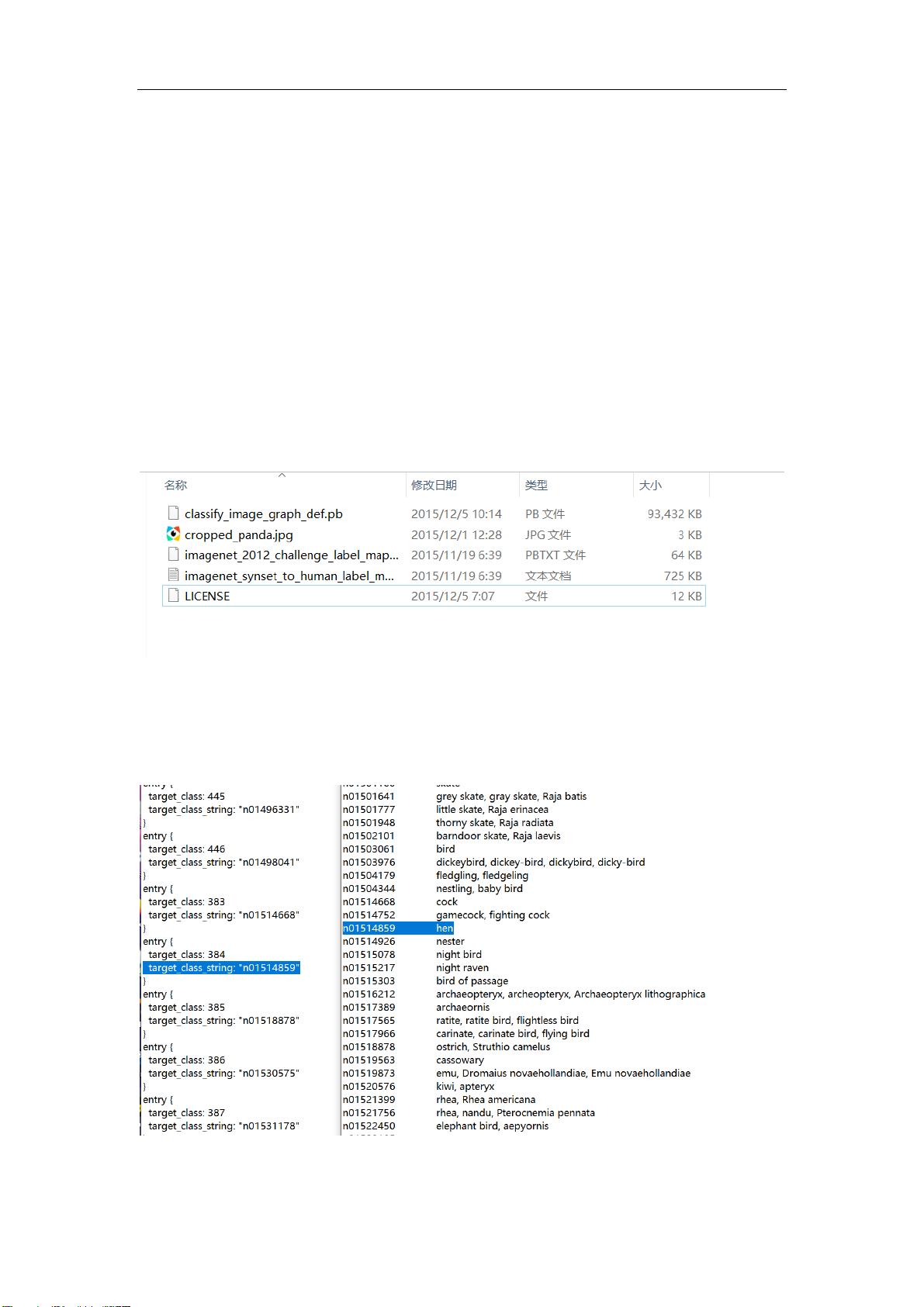
打开两个文件 imagenet_2012_challenge_label_map_proto.pbtxt 和
imagenet_synset_to_human_label_map.txt。这是原 inception v3 的检测的情况,就像下图的
384 是一个类别,对应的字符串编号是 n01514859,应该英文描述为 hen,母鸡,存储标签
内容。

剩余60页未读,继续阅读
2023-05-23 上传
2023-04-02 上传
2023-04-05 上传
2023-06-12 上传
2023-05-13 上传
2023-05-09 上传

我只匆匆而过
- 粉丝: 19
- 资源: 317
 我的内容管理
展开
我的内容管理
展开







最新资源
- 解决本地连接丢失无法上网的问题
- BIOS报警声音解析:故障原因与解决方法
- 广义均值移动跟踪算法在视频目标跟踪中的应用研究
- C++Builder快捷键大全:高效编程的秘密武器
- 网页制作入门:常用代码详解
- TX2440A开发板网络远程监控系统移植教程:易搭建与通用解决方案
- WebLogic10虚拟内存配置详解与优化技巧
- C#网络编程深度解析:Socket基础与应用
- 掌握Struts1:Java MVC轻量级框架详解
- 20个必备CSS代码段提升Web开发效率
- CSS样式大全:字体、文本、列表样式详解
- Proteus元件库大全:从基础到高级组件
- 74HC08芯片:高速CMOS四输入与门详细资料
- C#获取当前路径的多种方法详解
- 修复MySQL乱码问题:设置字符集为GB2312
- C语言的诞生与演进:从汇编到系统编程的革命
