kNN算法在手写识别中的应用
需积分: 23 54 浏览量
更新于2024-09-10
收藏 283KB DOCX 举报
"这篇文档是关于人工智能领域中的人工智能手写识别技术,特别是通过k最邻近算法(k-Nearest Neighbor, KNN)实现手写数字的识别。文档包含了一个实验报告,讨论了kNN算法的基本概念、计算过程,并提供了部分代码示例。"
在人工智能领域,手写识别是一项重要的技术,它涉及到计算机视觉和机器学习。手写识别主要用于自动识别手写字符,如银行支票上的数字、邮政编码或个人签名,广泛应用在金融、邮政服务和移动设备中。本文档关注的是利用k最邻近算法(KNN)实现这一功能。
kNN是一种基于实例的学习方法,其工作原理是将未知类别的新样本与已知类别的训练样本进行比较,找出最近的k个邻居,然后根据这些邻居的类别信息来决定新样本的类别。kNN算法简单直观,但在实际应用中需要考虑k值的选择,因为它直接影响到分类效果。k值太小可能导致分类过于依赖个别样本,而k值太大则可能引入噪声,使得分类结果变得模糊。
在计算过程中,kNN首先计算新样本与所有训练样本之间的距离,一般使用欧氏距离作为衡量标准。接着,根据距离排序,选取距离最小的k个样本。对于连续性数据,如图像的像素强度,通常采用k个样本的均值作为预测值;对于离散性数据,如类别标签,会选择出现频率最高的类别作为预测分类。
提供的代码片段展示了如何从图像文件转换为向量,这是处理图像数据的第一步。`img2vector`函数读取图像文件,将其每一行的像素值转化为一维向量。另外,`createDataset`函数用于读取指定目录下的训练数据,将图像文件和对应的标签(类别信息)组合成数据集。
kNN算法在手写识别中取得了显著的成果,特别是在MNIST这样的经典数据集上。然而,kNN也有其局限性,例如计算复杂度高,不适用于大规模数据集,以及对异常值敏感等问题。为了提高效率和准确性,后续的研究可能会结合其他机器学习模型,如支持向量机(SVM)、神经网络等,或是采用更高级的特征提取和预处理技术。
最邻近算法
使用 进行手写识别
实验报告
基本概念
最邻近算法(),是机器学习分类算法中最简单的
一类。假设一个样本空间被分为几类,然后给定一个待分类的特征数据,通过计算距
离该数据的最近的 个样本来判断这个数据属于哪一类。如果距离待分类属性最近的
个类大多数都属于某一个特定的类,那么这个待分类的数据也就属于这个类。所谓
最近邻,就是 个最近的邻居的意思,说的是每个样本都可以用它最接近的 个邻居
来代表。 在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分
样本所属的类别,在决策时,只与极少量的相邻样本有关。通常, 是不大于 的整
数。
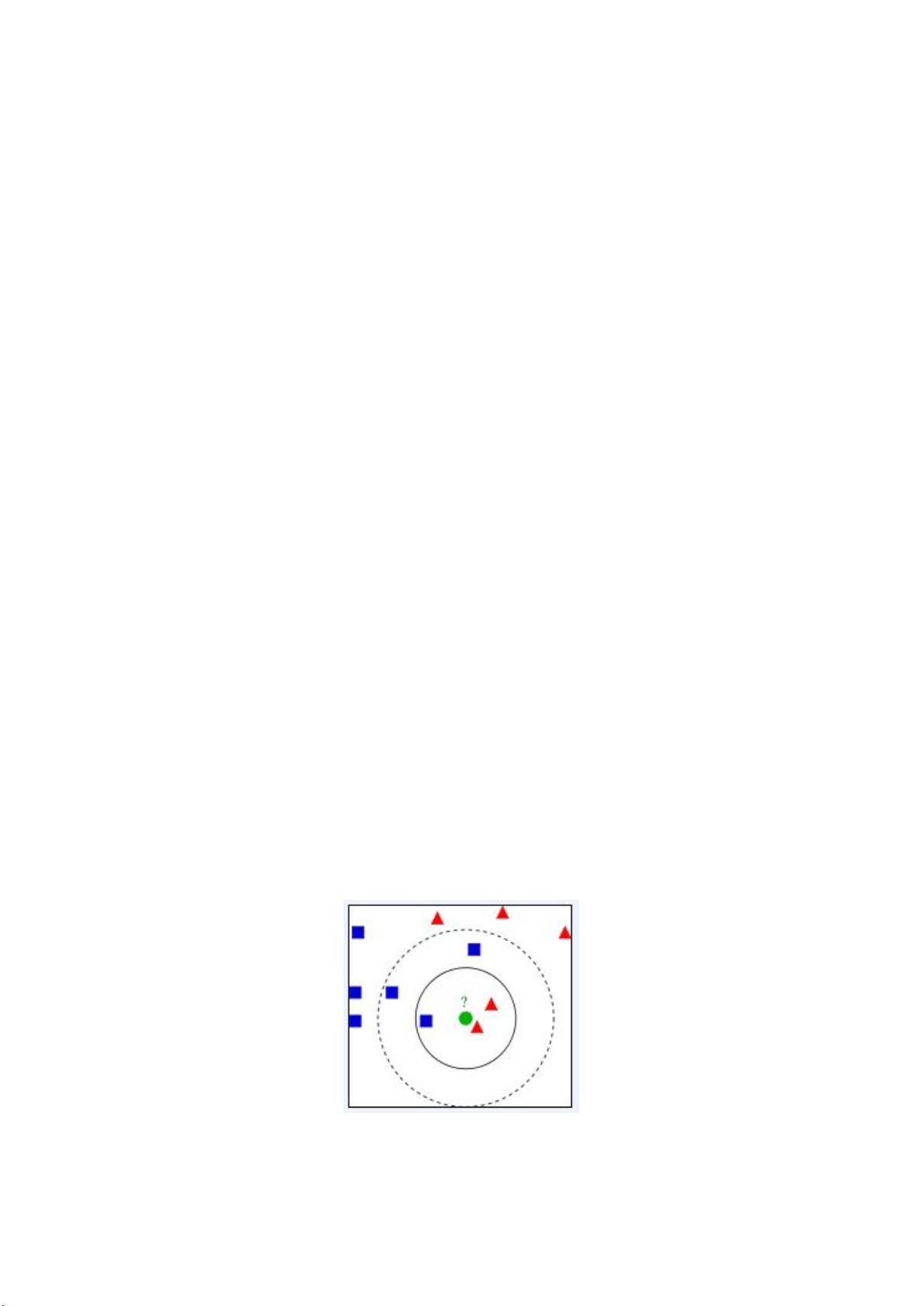
下图所示,圆要被决定赋予哪个类,是三角形还是四方形?如果 ,由于三角
形所占比例为 ,圆将被赋予三角形那个类,如果 ,由于四方形比例为 ,
因此圆被赋予四方形类。
在理想情况下, 值选择 ,即只选择最近的邻居。在现实生活中往往没这么理想,
比如对于价格来说,有些顾客消息闭塞,可能会为 “最近的邻居”多付很多钱,所以应
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-09-24 上传
2022-09-24 上传
2024-04-19 上传
2011-11-15 上传
2013-01-29 上传

Alvin畅
- 粉丝: 51
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- ednsl:用于在 clojure 中使用 edn 语法创建 dsl 的 dsl
- threes:RT-Thread终端益智类游戏| 一个独立的益智视频游戏在RT-Thread控制台上运行
- weather-page-demo
- 电子商务客户端:电子商务客户端
- Sayhub-express:我的Express博客后端
- 310V单相高压无刷直流电机驱动方案——(高压风机、高压落地扇、中央空调盘管风机等单相无刷电机应用)-电路方案
- 这是一本 MySQL 学习笔记.zip
- gze1206.github.io
- android-mypapayoo:Android-在Android上实施纸牌游戏“ Papayoo”(离线,正在进行中)
- intercom:用于对讲的 Go 客户端库
- Silvaco-LearningNote:Silvaco学习笔记
- 贪食蛇VC++小游戏 附源码贪食蛇
- 这是一个基于Springboot+Mybatis+Redis+MySql+RabbitMq的校园医疗管理系统,本来是.zip
- bst_in_mips:用MIPS汇编语言实现一些二进制搜索树操作
- Mod-Menu-Template:Android的Mod菜单模板
- FED-lessen:投资组合网站为FED
