云时代大数据管理:HAWQ++深度解析
需积分: 5 15 浏览量
更新于2024-08-03
收藏 1.02MB PDF 举报
“藏经阁-云时代大数据管理引擎HAWQ++.pdf”主要介绍了云时代的HAWQ++,这是一个高效的大数据管理引擎,其发展经历了从原生的Hadoop并行SQL引擎到HAWQ2.0并进入Apache孵化器的过程。偶数科技的HAWQ++是对HAWQ的进一步扩展和增强。
**HAWQ简介及发展历程**
HAWQ(High-Performance Analytics Warehouse Query)最初是作为一个与Hadoop生态系统紧密集成的并行SQL引擎发展起来的。它经历了多个版本的演进,从GoH到HAWQAlpha,再到HAWQ1.0和1.x,最终在HAWQ2.0阶段,它成为了Apache的一个孵化项目。偶数科技的HAWQ++是对这个开源项目的进一步发展,提供了更加强大的功能和性能。
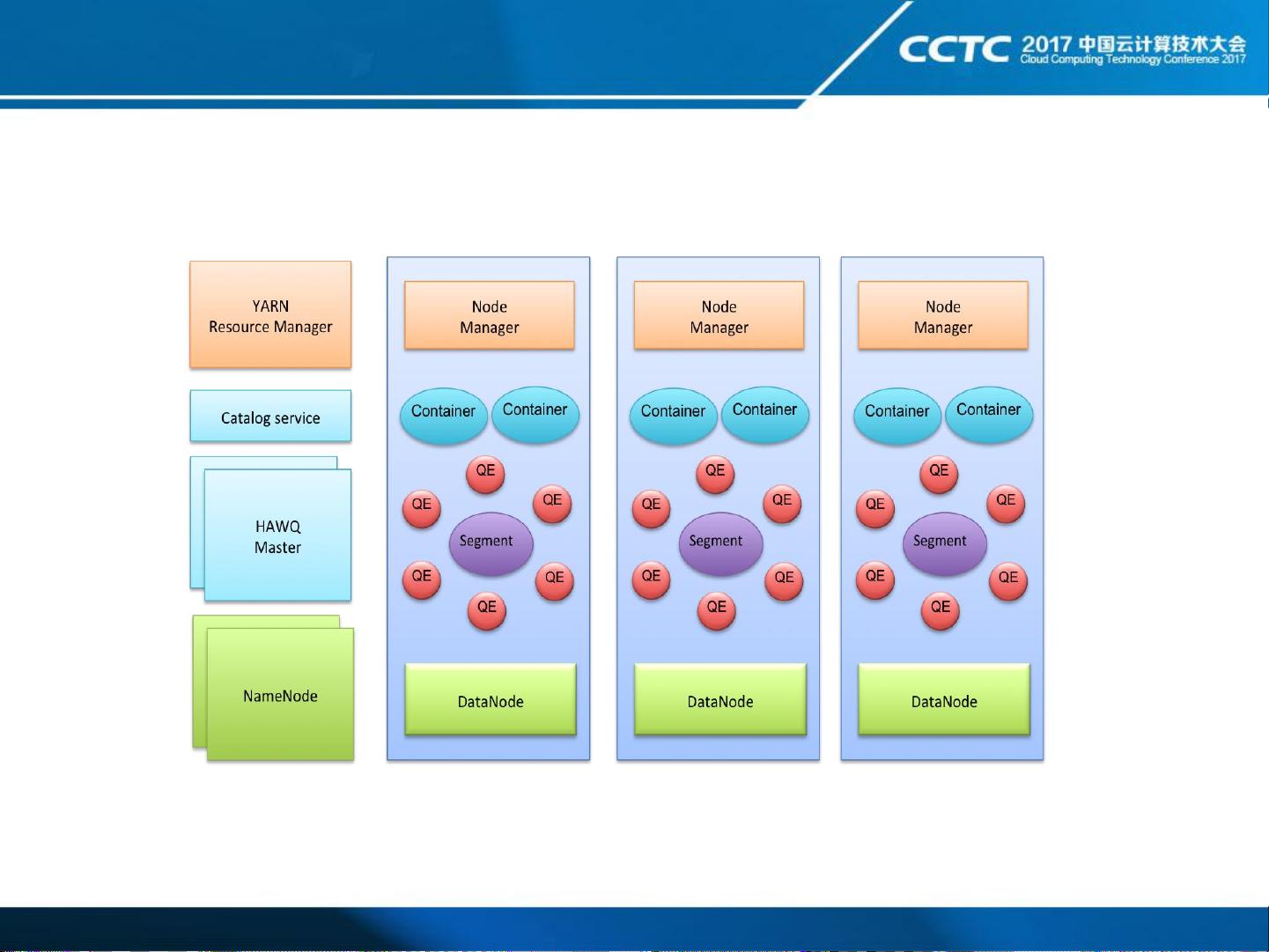
**HAWQ组件与体系架构**
HAWQ的体系架构基于YARN(Yet Another Resource Negotiator),包括client、Masters、Parser/Analyzer、Optimizer、Dispatcher等组件。在YARN上运行,它通过PhysicalSegment、Virtual Segment和DataNode等组件实现数据的分布式管理和处理。HAWQ还包含了Catalog Service和Fault Tolerance Service,确保数据的安全性和系统稳定性。
**HAWQ优化器**
HAWQ优化器负责解析和优化SQL查询,如示例中的SELECT语句,它会根据查询条件应用不同的motion操作:redistributemotion用于根据哈希值分布数据,broadcastmotion将数据广播到所有节点,而gathermotion则用于从多个节点聚合数据。
**HAWQ查询处理流程**
查询处理流程包括解析、分析、优化和执行。HAWQ优化器会生成高效的执行计划,包括使用motion操作来有效地移动数据,以实现并行处理和负载均衡。
**HAWQ资源管理**
HAWQ有三级资源管理机制:全局、内部和操作符级别的资源管理。它与YARN协同工作,申请和释放计算资源,并通过多级资源队列对CPU和内存进行精细化管理,以满足不同用户和查询的需求。
**HAWQ存储**
HAWQ支持行式存储(Row-oriented)的Append-Only(AO)表格式,并支持Quicklz和zlib压缩算法,以减少存储空间需求并提高读取效率。
**总结**
HAWQ++作为云时代的大数据管理引擎,提供了一种强大的SQL查询能力,与Hadoop生态系统深度集成,并通过精细的资源管理和优化策略,确保了大数据处理的高效性和可靠性。它适用于大规模数据分析场景,为企业提供了高性能的数据仓库解决方案。
HAWQ组件
剩余13页未读,继续阅读
2019-08-29 上传
点击了解资源详情
点击了解资源详情
2021-10-14 上传
2018-02-11 上传
2021-08-08 上传
2023-08-28 上传
2016-02-24 上传

weixin_40191861_zj
- 粉丝: 86
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
