
一、集成学习简介
三个臭皮匠顶一个诸葛亮,聚合一组预测器(分类器或回归器)的预测,得到的预测
器结果比单个预测器要好,这种技术成为集成学习
常用的集成学习方法:
1. Voting(投票)
2. Bagging—随机森林
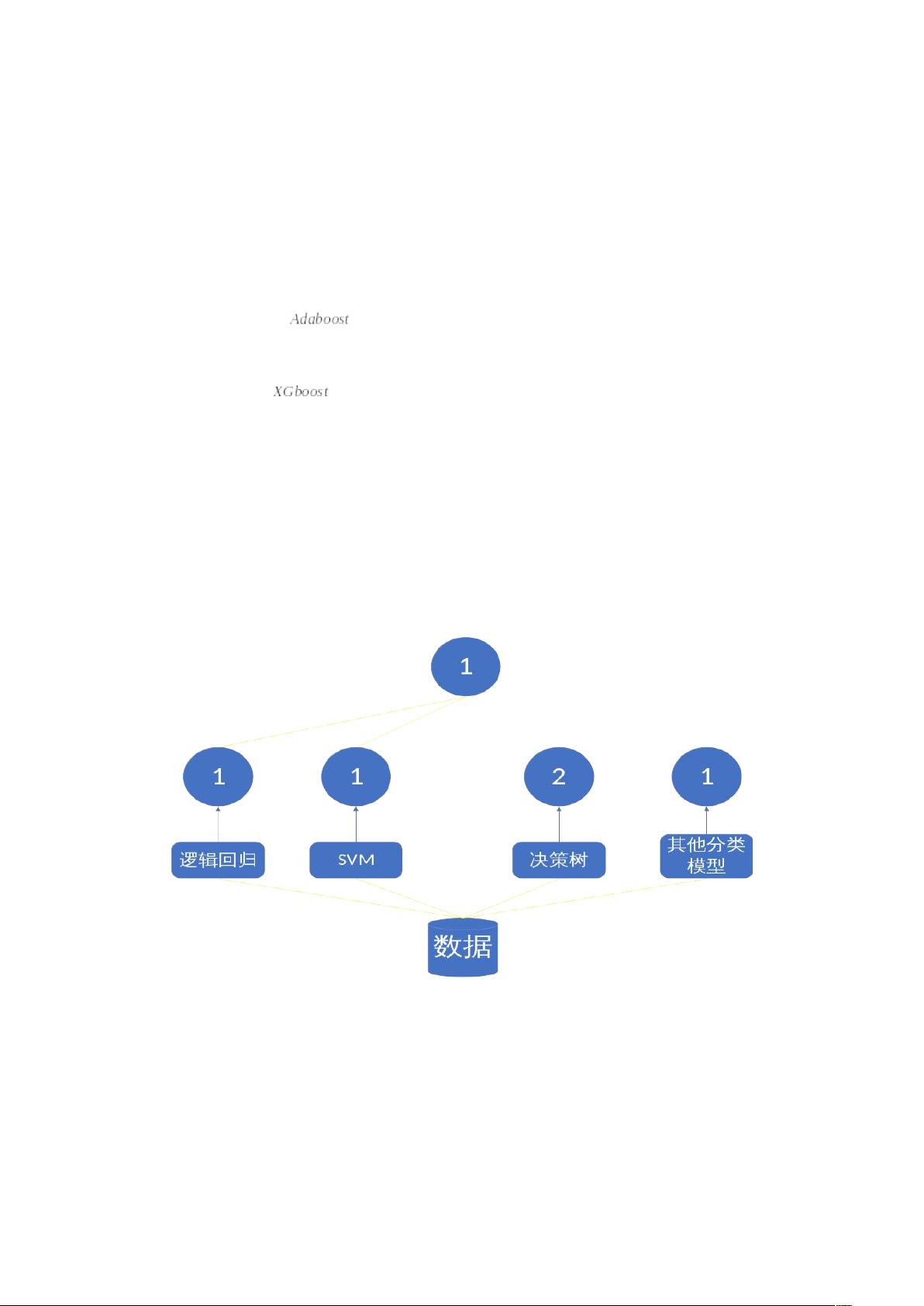
3. Boosting—
—提升树
—
4. Stacking
二、Voting—投票
1. Voting 的原理
1). 硬投票分类器
2). 软投票分类器
如果所有分类器都能够估算出类别概率,那么可以将概率在所有单个分类器上平均,
然后让给出平均概率最高的类别作为预测,这被称为软投票法。通常来说,它比硬投票法
更优,因为它给予那些高度自信的投票以更高的权重。举个例子来说:如果三个基本分类
器的类别概率,在某一类别 A 上,两个略低于 50%,一个接近 100%,硬投票分类器的
表现结果为不是 A,但在软投票分类器上表现为 A
下载后可阅读完整内容,剩余7页未读,立即下载

哎呦-_-不错
- 粉丝: 1921
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- OptiX传输试题与SDH基础知识
- C++Builder函数详解与应用
- Linux shell (bash) 文件与字符串比较运算符详解
- Adam Gawne-Cain解读英文版WKT格式与常见投影标准
- dos命令详解:基础操作与网络测试必备
- Windows 蓝屏代码解析与处理指南
- PSoC CY8C24533在电动自行车控制器设计中的应用
- PHP整合FCKeditor网页编辑器教程
- Java Swing计算器源码示例:初学者入门教程
- Eclipse平台上的可视化开发:使用VEP与SWT
- 软件工程CASE工具实践指南
- AIX LVM详解:网络存储架构与管理
- 递归算法解析:文件系统、XML与树图
- 使用Struts2与MySQL构建Web登录验证教程
- PHP5 CLI模式:用PHP编写Shell脚本教程
- MyBatis与Spring完美整合:1.0.0-RC3详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


