Spark与Kafka结合:内存计算加速大数据分析
需积分: 50 170 浏览量
更新于2024-07-18
收藏 1.34MB PDF 举报
"这篇文档是关于Spark与Kafka的整合学习笔记,主要涵盖了Spark的基本概念、特点以及Spark如何与Kafka进行数据交互。Spark是一种快速、通用的大数据分析引擎,其特点是易用性、成本效益、兼容性和高效的数据处理。文章强调Spark作为MapReduce的替代方案,能够更好地适应大数据环境下的实时需求。"
Spark是一种分布式计算框架,它的设计目标是提供快速、通用、可扩展的数据处理能力。Spark生态系统包括SparkSQL、SparkStreaming、GraphX和MLlib等多个子项目,这些子项目覆盖了数据处理的不同领域。Spark的核心优势在于内存计算,它减少了磁盘I/O,提高了数据处理速度,同时提供了高容错性和高可伸缩性,可以在大规模硬件集群上运行。
Spark的特点主要有以下几点:
1. **易用性**:Spark支持多种编程语言,包括原生的Scala、Java、Python和SparkSQL。SparkSQL提供类似SQL92的语法,使得熟悉SQL的用户可以快速上手。此外,Spark还提供了交互式Shell,便于开发人员和用户实时查看和测试查询结果。
2. **成本效益**:Spark在处理大规模数据时表现出色,能够在较少的硬件资源上实现高效的性能。例如,在处理100TB数据的排序任务中,Spark比Hadoop MapReduce快3倍。
3. **兼容性**:Spark可以无缝集成到Hadoop生态系统中,兼容HDFS和Hive,并且像MapReduce一样,通过JDBC和ODBC与多种数据源和商业智能工具进行交互。
4. **数据处理**:与MapReduce的批量处理不同,Spark支持更灵活的数据处理模型,如微批处理和实时流处理。它可以连续地从数据源如Kafka读取数据,进行实时分析,并立即响应结果。
在大数据处理中,Kafka常作为消息队列,用于数据的实时传输。Spark可以与Kafka结合,实现数据的实时摄入和处理。Spark Streaming能够连接到Kafka,实时消费Kafka的主题数据,进行流处理作业,从而提供低延迟的数据处理解决方案。
Spark-Kafka的结合在大数据实时处理场景中发挥着重要作用,为用户提供了快速响应、高吞吐量的数据处理能力,是现代大数据架构中的关键组件。通过Spark的内存计算和Kafka的流处理能力,企业可以构建出高效、弹性的数据处理系统。
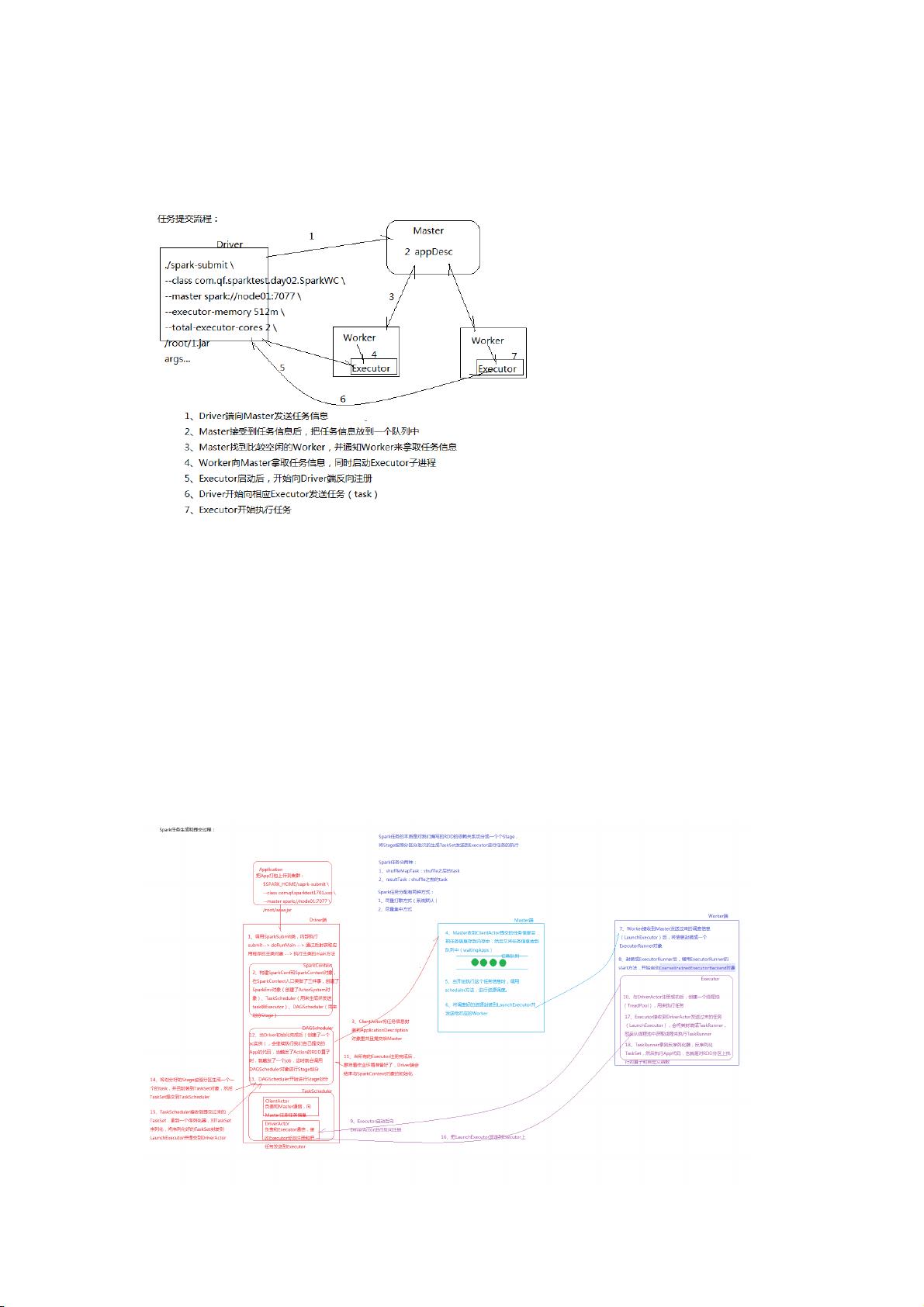
8.Spark任务提交流程
1. Driver端向Master发送任务消息
2. Master接受到任务信息后,把任务信息放到个队中
3. Master找到较空闲的Worker,并通知Worker来拿取任务信息
4. Worker向Master拿取任务信息,同时启动Executor进程
5. Executor启动后,开始向Driver端反向注册
6. Driver开始向相应Executor发送任务(task)
7. Executor开始执任务
9.Spark任务成和提交流程(源码级分析)
剩余27页未读,继续阅读
580 浏览量
2023-04-24 上传
175 浏览量
231 浏览量
2023-04-08 上传
2024-12-13 上传

王峥jeff
- 粉丝: 11
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 数字电子技术基础_阎石第四版课后习题答案详解
- 高质量c++c编程指南
- 软件评测师2008年真题
- 利用ArcObjects组件技术实现图层的分类符号化
- CodeIgniter 教程
- 华为关于gpon简介
- LiferayPortal二次开发指南
- Active Man in the Middle Atacks
- 电磁兼容原理及其应用课件
- 全国软件考试软件设计师考试大纲
- 基于ArcObjects的网络三维地形场景生成
- 2009年软考程序员级考试大纲
- POP3与Foxmail+Server邮件服务器配置教程
- Log4简明手册(配置)
- net2003/2005编程技巧大全
- 数字电子技术基础 阎石第四版课后习题答案详解.pdf
