Spring实现数据库读写分离:应用层与中间件方案
需积分: 9 36 浏览量
更新于2024-07-18
1
收藏 169KB DOCX 举报
"本文主要探讨了如何利用Spring框架解决数据库的读写分离问题,提供了两种解决方案:应用层解决和中间件解决,并详细介绍了基于应用层的Spring实现方式。"
在应对高并发的读取压力时,数据库的读写分离是一种有效的优化策略。这种策略将数据的写入操作集中在一个主库(写库)上,而读取操作则分散到多个从库(读库)中,以达到提高系统性能和可用性的目的。为了实现这一策略,需要确保以下几点:
1. 数据一致性:所有从库的数据应与主库保持同步,以保证读取的数据准确无误。
2. 写操作定向:所有写操作必须提交到主库,以确保数据的来源清晰。
3. 读操作定向:所有读操作需从从库进行,减轻主库的压力。
Spring 提供了两种解决读写分离的方案:
1. 应用层解决:这种方式由开发人员在应用程序中实现数据源的切换。优点是切换数据源灵活,无需额外中间件,理论上可支持任何数据库。缺点是开发成本较高,运维介入较少,且难以动态扩展数据源。
2. 中间件解决:通过使用特定的中间件,如 mysql-proxy 或 Amoeba for MySQL,可以实现透明化的读写分离。优点是无需修改源代码,动态添加数据源无需重启服务。缺点是增加了中间件依赖,可能影响性能,且数据库切换较为复杂。
对于应用层解决,Spring 提供了基于 AOP(面向切面编程)的实现。具体原理是在调用 Service 方法前,通过 AOP 切面判断是读操作还是写操作,例如,通过方法名判断以 "query", "find", "get" 等开头的方法走读库,其他方法则走写库。`DynamicDataSource` 是一个关键组件,它继承自 Spring 的 `AbstractRoutingDataSource`,并实现 `determineCurrentLookupKey` 方法来决定当前使用的数据源。为了确保线程安全,通常会使用 `ThreadLocal` 来存储当前线程所关联的数据源信息。
通过这种方式,Spring 能够帮助开发者轻松地实现读写分离,提高系统的处理能力,同时保持数据的一致性。然而,具体选择哪种方案,需要根据项目的实际需求、团队的技术栈以及对性能和可维护性的考量来决定。
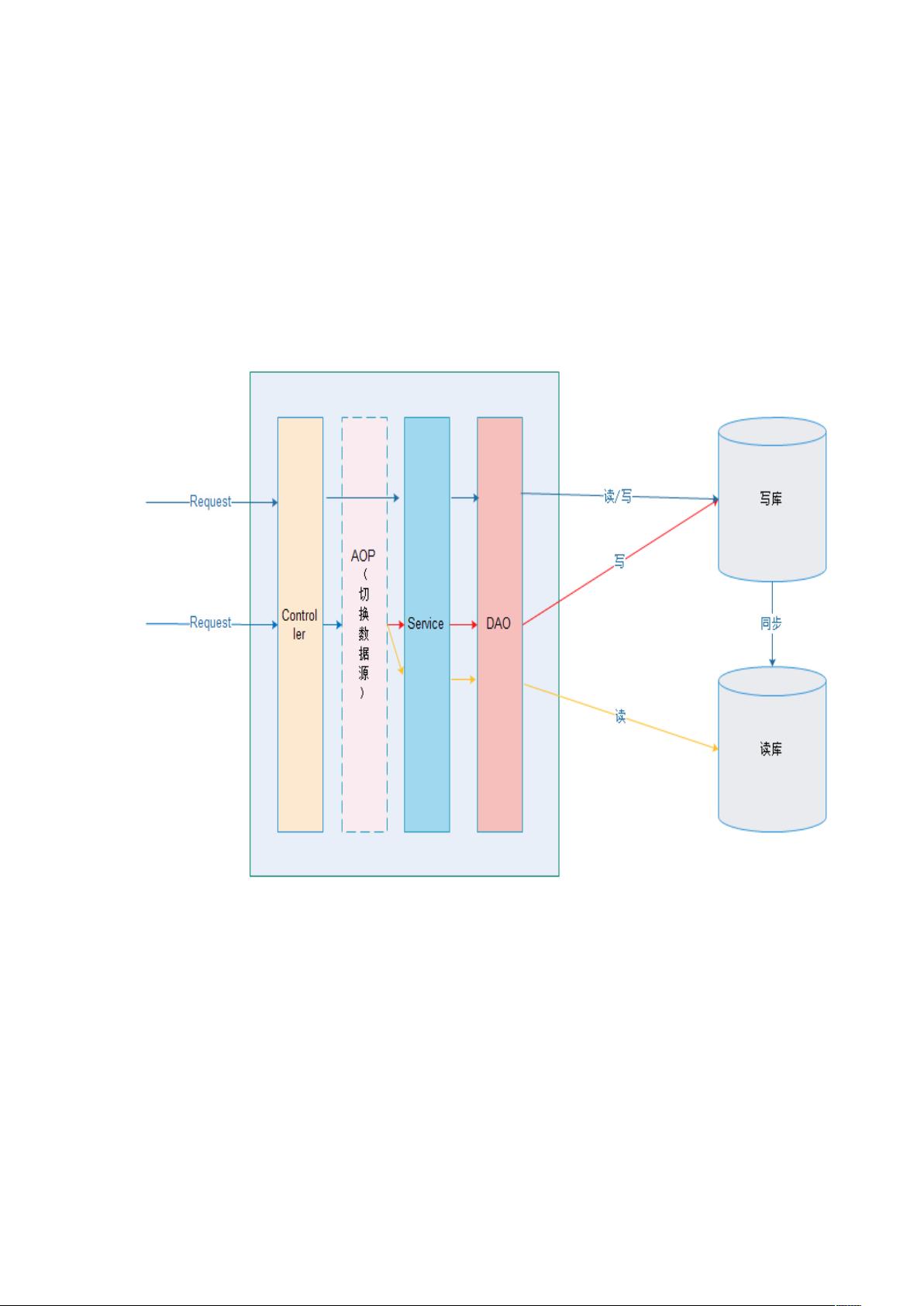
3. 使用 Spring 基于应用层实现
3.1. 原理
在进入 '+ 之前,使用 $,- 来做出判断,是使用写库还是读库,判断依据可
以根据方法名判断,比如说以 、./、 等开头的就走读库,其他的走
写库。
剩余23页未读,继续阅读
2020-08-31 上传
点击了解资源详情
点击了解资源详情
2023-05-16 上传
2023-09-20 上传
2023-09-12 上传
2024-06-28 上传

于亚超
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多模态联合稀疏表示在视频目标跟踪中的应用
- Kubernetes资源管控与Gardener开源软件实践解析
- MPI集群监控与负载平衡策略
- 自动化PHP安全漏洞检测:静态代码分析与数据流方法
- 青苔数据CEO程永:技术生态与阿里云开放创新
- 制造业转型: HyperX引领企业上云策略
- 赵维五分享:航空工业电子采购上云实战与运维策略
- 单片机控制的LED点阵显示屏设计及其实现
- 驻云科技李俊涛:AI驱动的云上服务新趋势与挑战
- 6LoWPAN物联网边界路由器:设计与实现
- 猩便利工程师仲小玉:Terraform云资源管理最佳实践与团队协作
- 类差分度改进的互信息特征选择提升文本分类性能
- VERITAS与阿里云合作的混合云转型与数据保护方案
- 云制造中的生产线仿真模型设计与虚拟化研究
- 汪洋在PostgresChina2018分享:高可用 PostgreSQL 工具与架构设计
- 2018 PostgresChina大会:阿里云时空引擎Ganos在PostgreSQL中的创新应用与多模型存储
