

always do more reading than writing), but also helps clarify what is going on at each point. Finally, this
separates future concerns, which would make it easier to troubleshoot and scale a problem like slow reads.
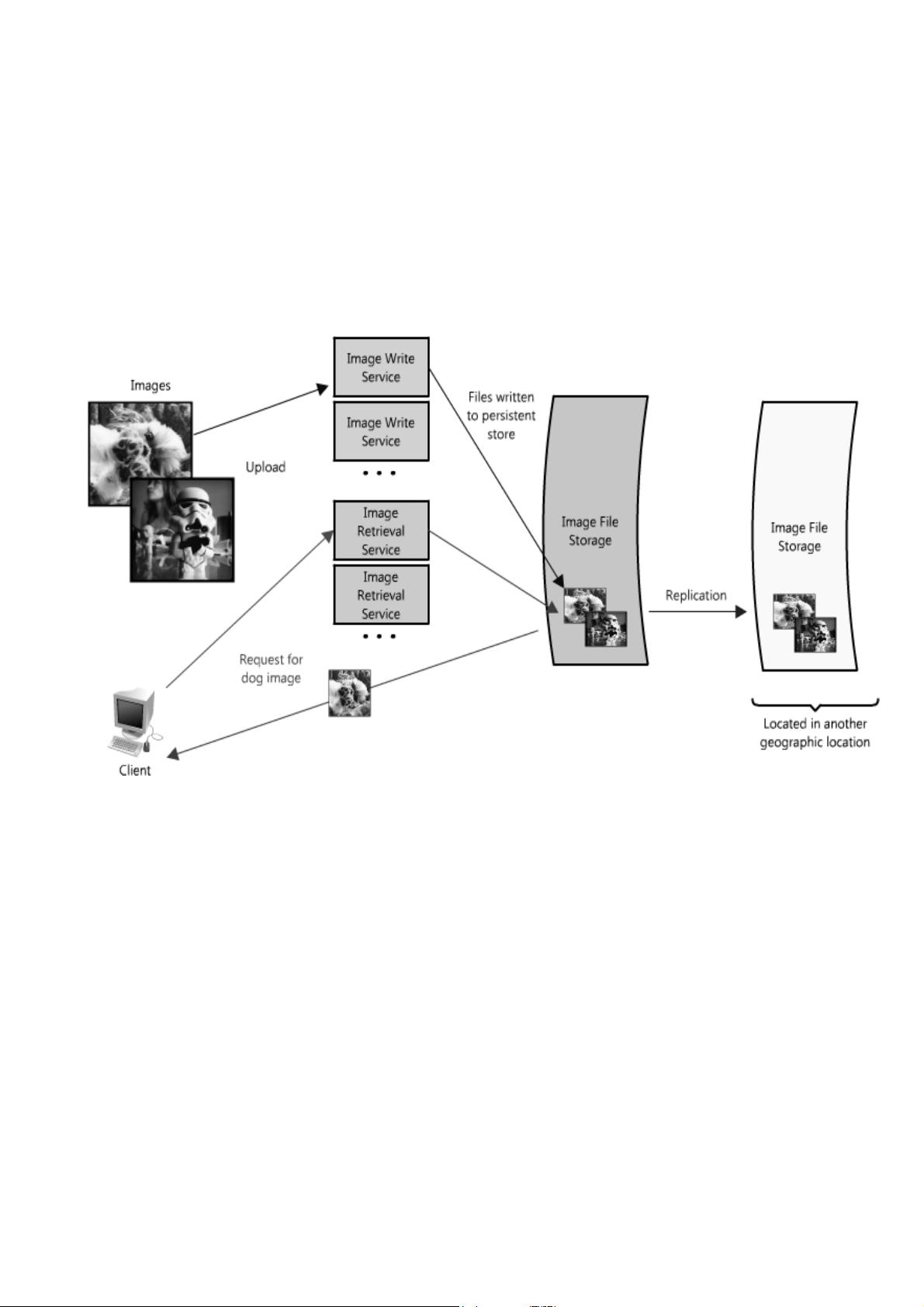
The advantage of this approach is that we are able to solve problems independently of one another—we don't
have to worry about writing and retrieving new images in the same context. Both of these services still
leverage the global corpus of images, but they are free to optimize their own performance with
service-appropriate methods (for example, queuing up requests, or caching popular images—more on this
below). And from a maintenance and cost perspective each service can scale independently as needed,
which is great because if they were combined and intermingled, one could inadvertently impact the
performance of the other as in the scenario discussed above.
Of course, the above example can work well when you have two different endpoints (in fact this is very similar
to several cloud storage providers' implementations and Content Delivery Networks). There are lots of ways
to address these types of bottlenecks though, and each has different tradeoffs.
For example, Flickr solves this read/write issue by distributing users across different shards such that each
shard can only handle a set number of users, and as users increase more shards are added to the cluster
(see the presentation on Flickr's
scaling,http://mysqldba.blogspot.com/2008/04/mysql-uc-2007-presentation-file.html). In the first example it is
easier to scale hardware based on actual usage (the number of reads and writes across the whole system),
whereas Flickr scales with their user base (but forces the assumption of equal usage across users so there
can be extra capacity). In the former an outage or issue with one of the services brings down functionality
across the whole system (no-one can write files, for example), whereas an outage with one of Flickr's shards
will only affect those users. In the first example it is easier to perform operations across the whole
dataset—for example, updating the write service to include new metadata or searching across all image
metadata—whereas with the Flickr architecture each shard would need to be updated or searched (or a
search service would need to be created to collate that metadata—which is in fact what they do).
When it comes to these systems there is no right answer, but it helps to go back to the principles at the start of
this chapter, determine the system needs (heavy reads or writes or both, level of concurrency, queries across
the data set, ranges, sorts, etc.), benchmark different alternatives, understand how the system will fail, and
have a solid plan for when failure happens.
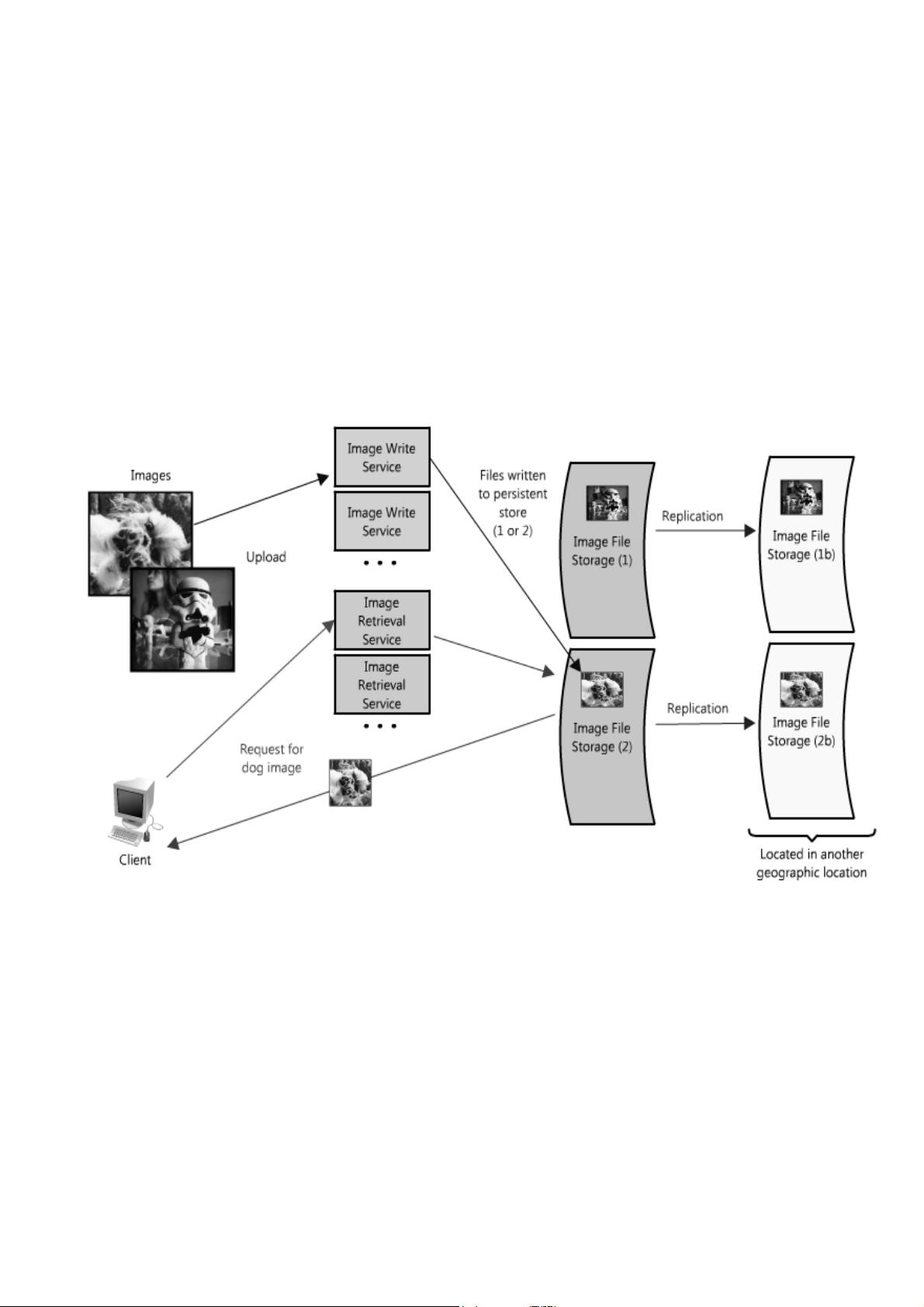
Redundancy
In order to handle failure gracefully a web architecture must have redundancy of its services and data. For
example, if there is only one copy of a file stored on a single server, then losing that server means losing that
file. Losing data is seldom a good thing, and a common way of handling it is to create multiple, or redundant,
copies.
This same principle also applies to services. If there is a core piece of functionality for an application, ensuring
that multiple copies or versions are running simultaneously can secure against the failure of a single node.
Creating redundancy in a system can remove single points of failure and provide a backup or spare
functionality if needed in a crisis. For example, if there are two instances of the same service running in
production, and one fails or degrades, the system can failoverto the healthy copy. Failover can happen
automatically or require manual intervention.
Another key part of service redundancy is creating a shared-nothing architecture. With this architecture, each
node is able to operate independently of one another and there is no central "brain" managing state or
剩余428页未读,继续阅读

sinat_21954747
- 粉丝: 0
- 资源: 24
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多模态联合稀疏表示在视频目标跟踪中的应用
- Kubernetes资源管控与Gardener开源软件实践解析
- MPI集群监控与负载平衡策略
- 自动化PHP安全漏洞检测:静态代码分析与数据流方法
- 青苔数据CEO程永:技术生态与阿里云开放创新
- 制造业转型: HyperX引领企业上云策略
- 赵维五分享:航空工业电子采购上云实战与运维策略
- 单片机控制的LED点阵显示屏设计及其实现
- 驻云科技李俊涛:AI驱动的云上服务新趋势与挑战
- 6LoWPAN物联网边界路由器:设计与实现
- 猩便利工程师仲小玉:Terraform云资源管理最佳实践与团队协作
- 类差分度改进的互信息特征选择提升文本分类性能
- VERITAS与阿里云合作的混合云转型与数据保护方案
- 云制造中的生产线仿真模型设计与虚拟化研究
- 汪洋在PostgresChina2018分享:高可用 PostgreSQL 工具与架构设计
- 2018 PostgresChina大会:阿里云时空引擎Ganos在PostgreSQL中的创新应用与多模型存储
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


