Byte-Pair Encoding (BPE) is a type of tokenizer used in Transformer models like GPT-3 for input encoding. BPE works by splitting words into subword units based on their frequency of occurrence in a given corpus. This method helps the model to learn complex representations of words and their variations, reducing the overall vocabulary size and improving efficiency.
In addition to BPE, there are two other main types of tokenizers used in Transformer models: WordPiece and Sentence Piece. Each tokenizer has its own advantages and limitations, and the choice of tokenizer can impact the model's performance and ability to handle different types of input data.
For example, the BertTokenizer in the Bert model uses the WordPiece tokenizer, which is similar to BPE but has some differences in terms of tokenization rules and implementation. By using WordPiece, the Bert model is able to effectively handle a wide range of input data and learn the appropriate representations for different words and subword units.
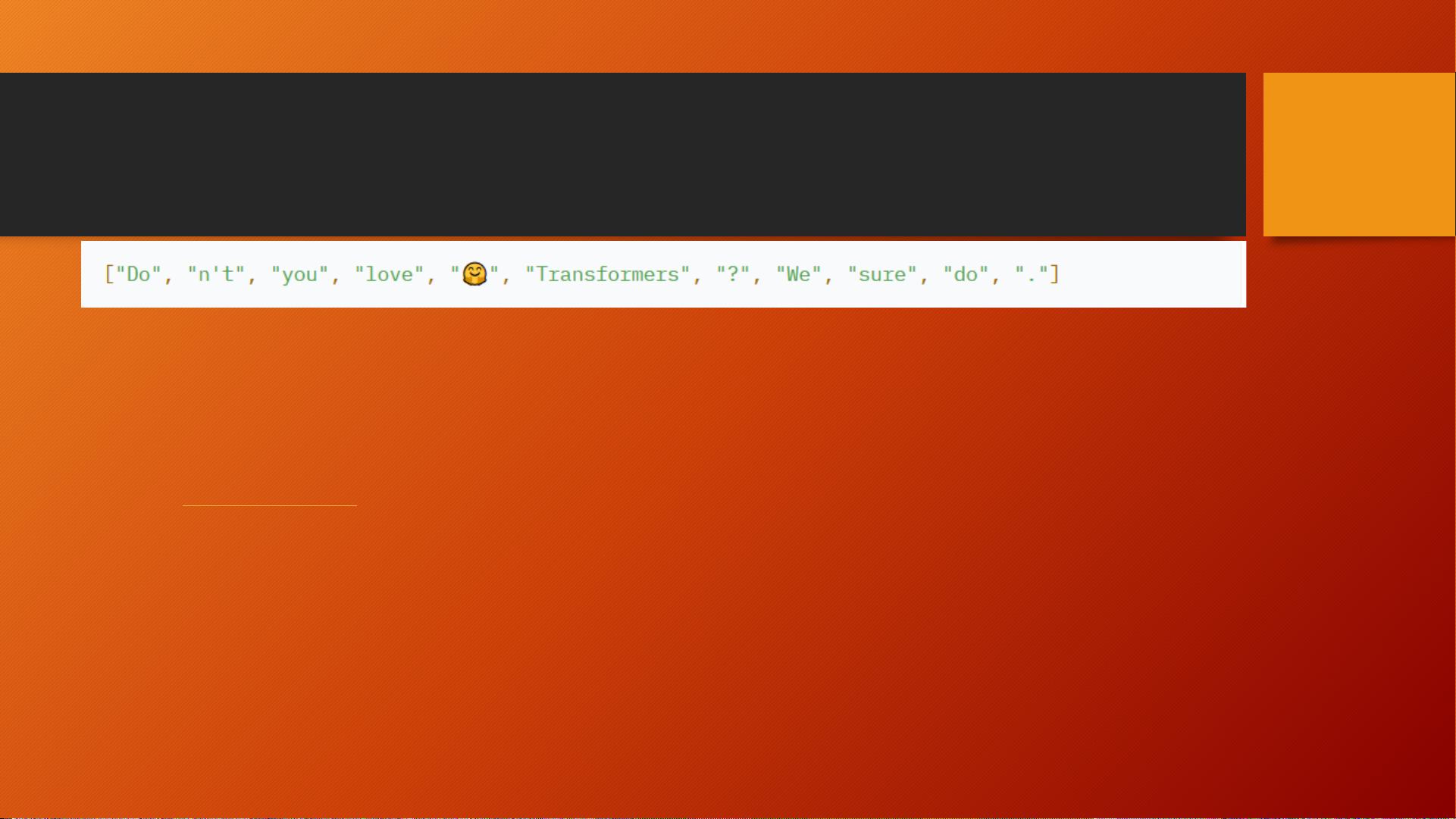
However, the choice of tokenizer can also lead to challenges in handling certain types of input data, such as dealing with contractions like "Don't" which should ideally be split into ["Do", "n't"] for proper tokenization. This highlights the importance of using the right tokenizer for a given task and ensuring that the tokenizer's rules align with the data used for training the model.
Overall, tokenization plays a crucial role in the performance and effectiveness of Transformer models, and choosing the right tokenizer can significantly impact the model's ability to process and understand input data. By understanding the strengths and limitations of different tokenization methods like BPE, WordPiece, and Sentence Piece, researchers and practitioners can ensure that their models are properly trained and equipped to handle a wide range of input data effectively.



 我的内容管理
收起
我的内容管理
收起
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助 






