2023 ISSCC V32:智能生物医学电路与系统创新,集成275倍输入阻抗提升与多模态补偿
需积分: 3 45 浏览量
更新于2024-06-26
收藏 34.63MB PDF 举报
在2023年的国际固态电路会议(IEEE ISSCC)上,第32届分会聚焦于"Intelligent Biomedical Circuits and Systems",其中一项引人瞩目的创新成果是"Behind-the-Ear Patch-Type Mental Healthcare Integrated Interface"。这一研究论文介绍了一种新型的可穿戴设备,它旨在提供高度集成的解决方案,特别针对心理健康护理,其特点是拥有显著的输入阻抗提升(高达275倍)以及适应性的多模态补偿功能。
论文详细探讨了以下关键内容:
1. Behind-the-Ear Wearable System:该系统设计为轻便且易于佩戴的耳后贴片形式,旨在实现非侵入式且舒适的用户体验。这种设计使得用户可以在日常生活中长时间使用,而不会感到不适或影响其外观。
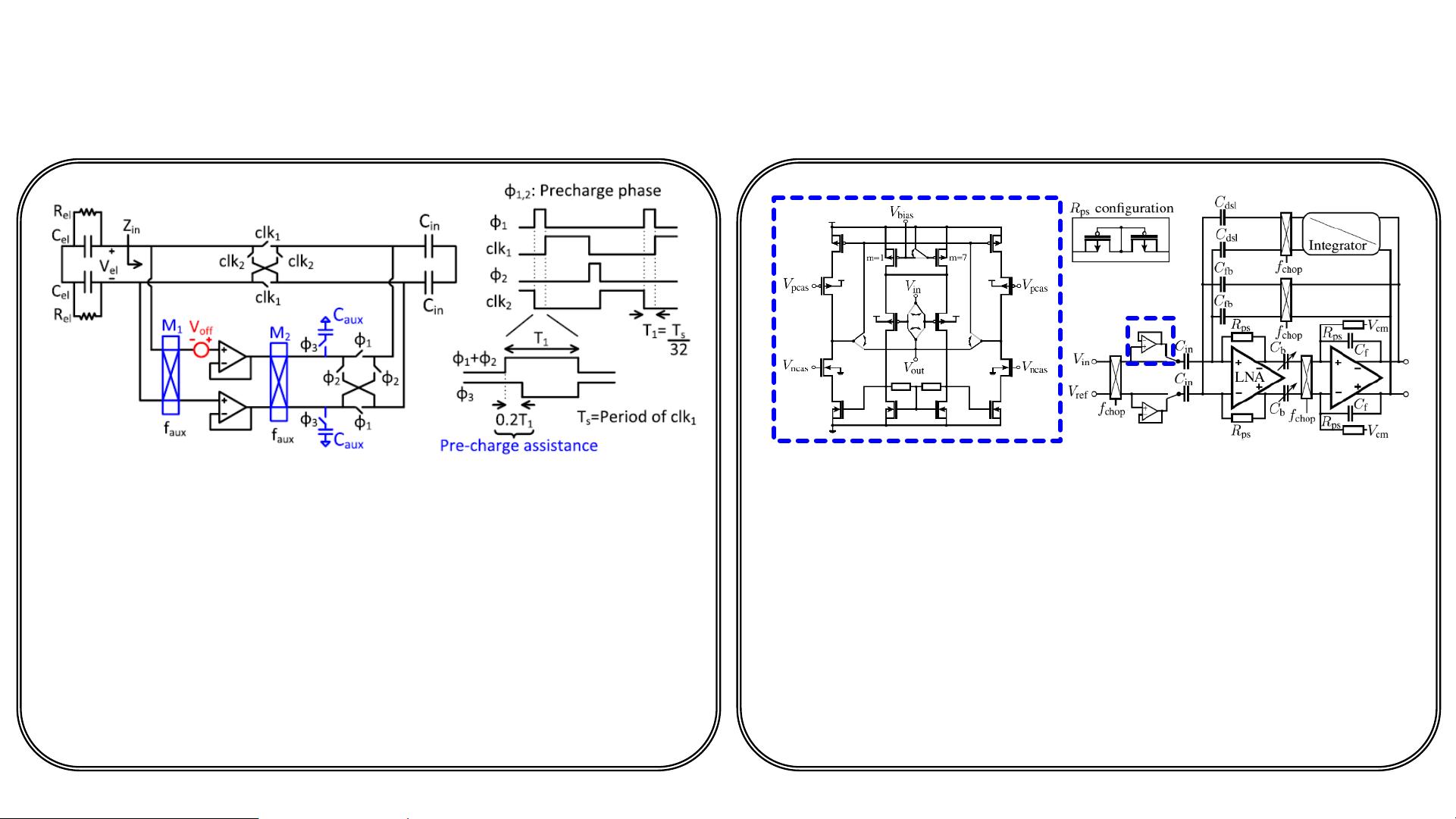
2. IC Implementation & Measurements:研究人员深入介绍了集成电路(IC)的设计与实现,包括电路架构、信号处理技术以及对各项性能指标如功耗、带宽和灵敏度的测量。这展示了他们在微电子技术上的专业知识,以确保系统的高效性和精确性。
3. System Implementation & Measurements:论文进一步阐述了整个系统的组装和测试过程,包括硬件和软件的协同工作,以及如何通过系统级的集成来优化整体性能。这部分涉及了信号传输、数据处理和用户界面设计。
4. Comparison and Summary:研究者还对比了他们的设计与其他类似产品的优劣,突出了275倍输入阻抗增益和多模态补偿能力的优势。这些特性有助于减少外部干扰,提高信号质量,并可能支持多种健康监测模式,如生物电信号、声音和压力感应。
这项工作不仅体现了当前可穿戴技术在医疗健康领域的前沿进展,而且强调了在复杂环境中的信号处理挑战和解决方案。这对于未来的智能生物医学系统的发展具有重要意义,可能会推动这一领域的产品创新和临床应用。
32.1: A Behind-The-Ear Patch-Type Mental Healthcare Integrated Interface with 275-Fold Input Impedance Boosting
and Adaptive Multimodal Compensation Capabilities
© 2023 IEEE
International Solid-State Circuits Conference
15 of 59
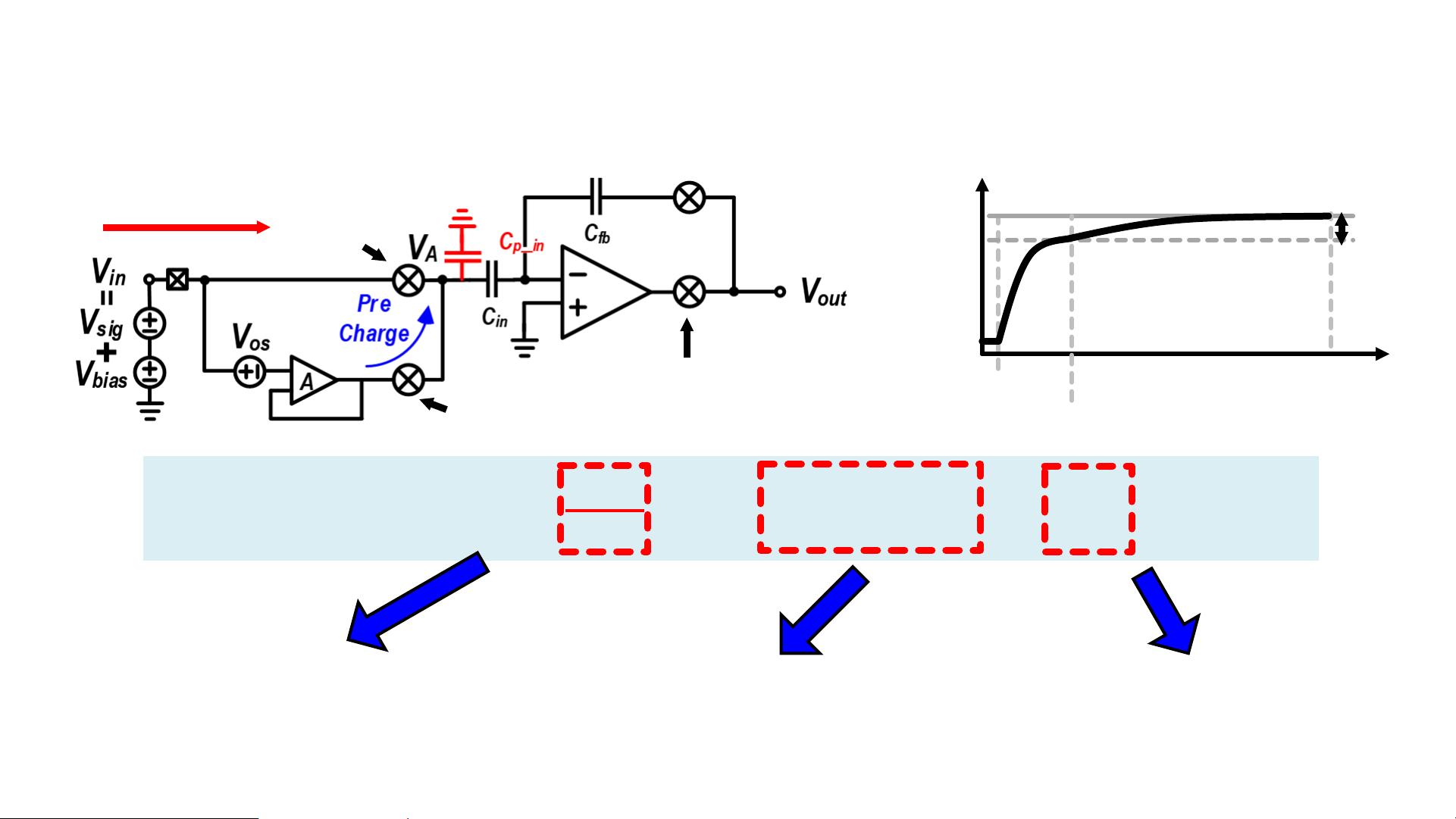
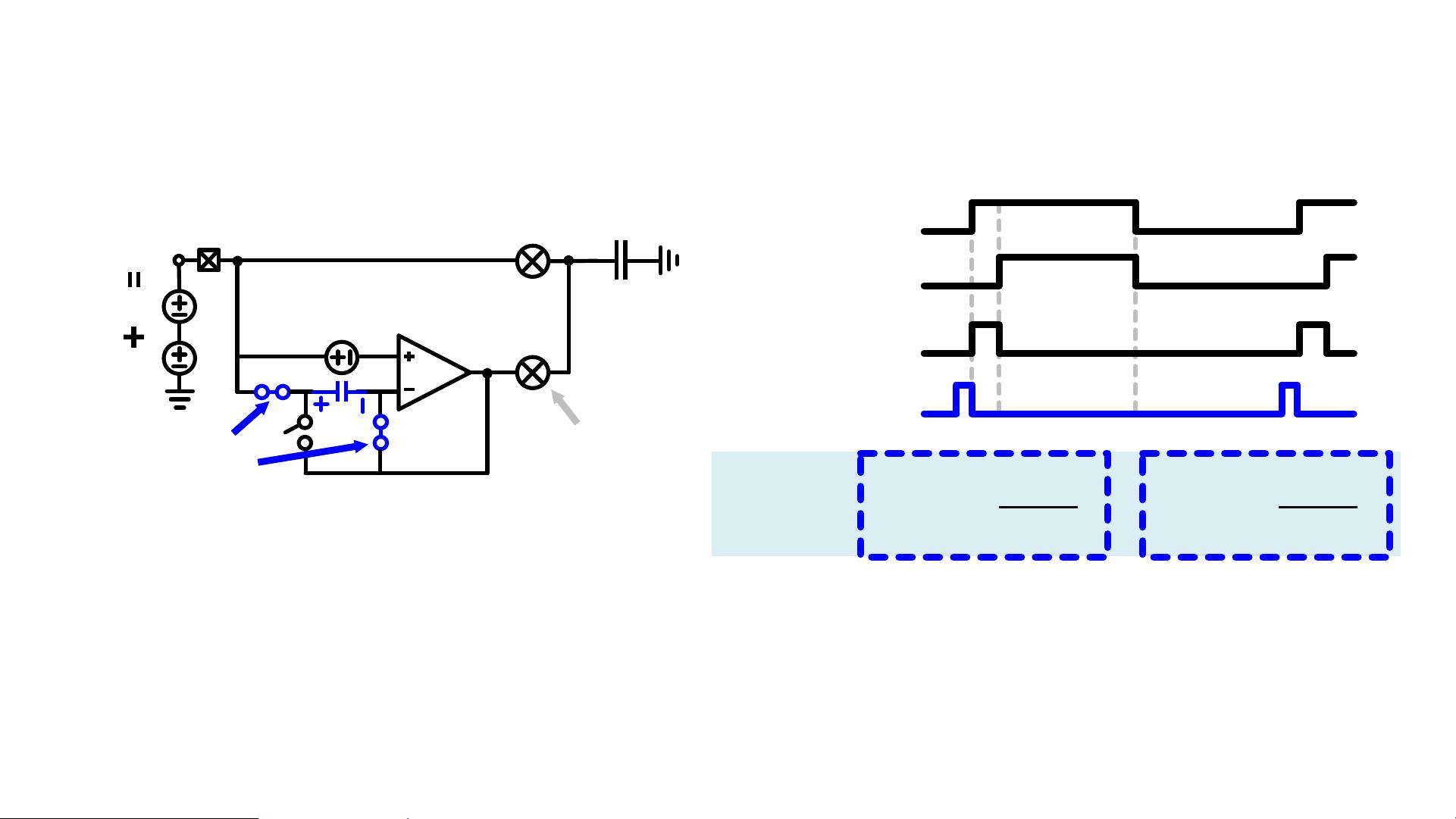
Limiting Factors in Auxiliary Path
Limited
Bandwidth
Random Intrinsic Offset
(unpredictable effect)
Finite
Gain
Time (t)
V
IN
V
A
(v)
ɸ
1,AUX
ɸ
1
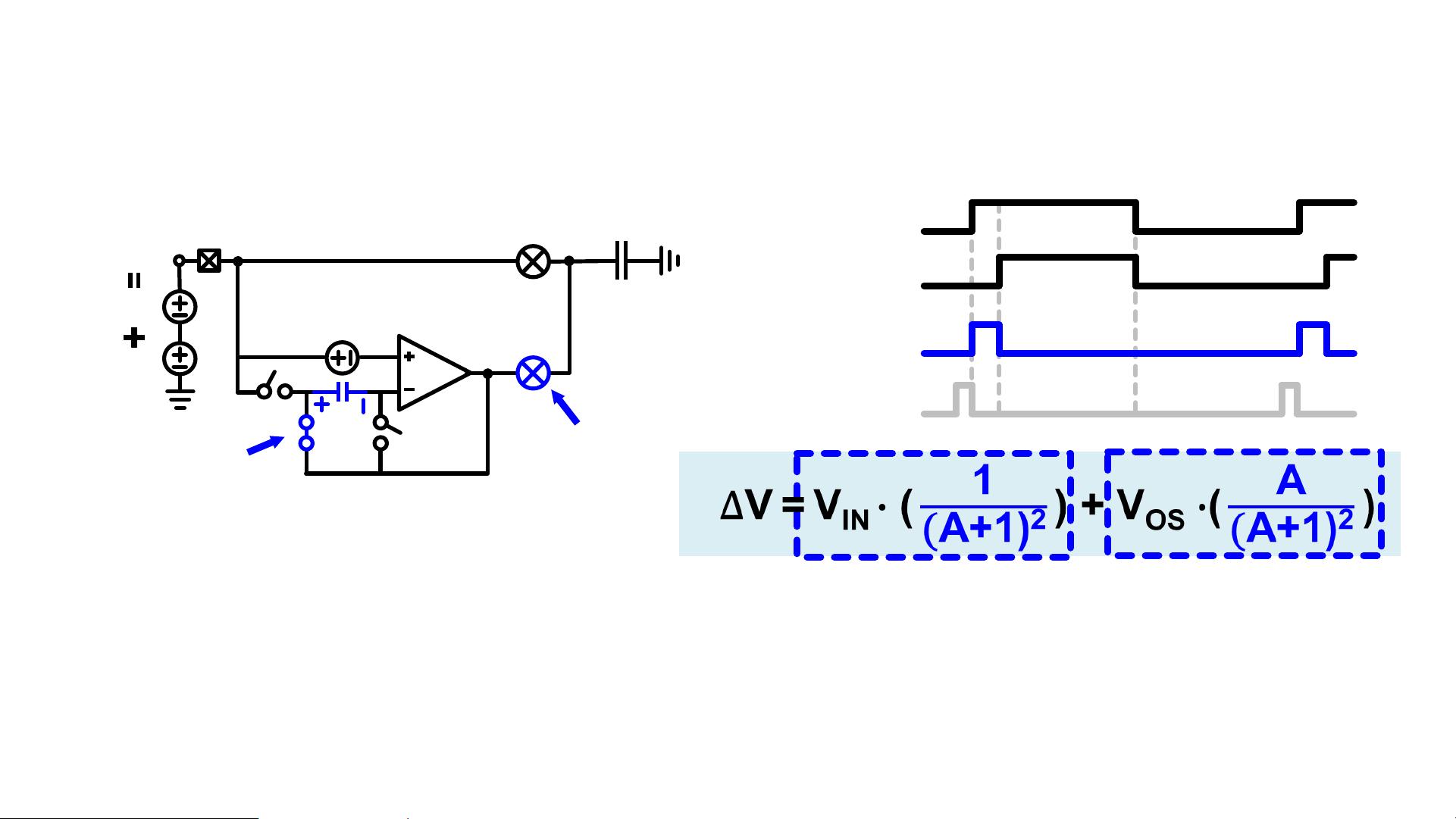
V ≈ V
IN
(
1
A+1
+ exp(
−ɸ
1,AUX
τ
))
± V
OS
ɸ
1
ɸ
1,AUX
ɸ
chop
ΔV charging
ΔV
Residue voltage

剩余393页未读,继续阅读
2023-03-14 上传
2023-06-22 上传
2024-01-16 上传
2024-02-06 上传
2024-01-15 上传
2023-05-09 上传
2023-09-08 上传
2024-09-06 上传
2024-09-06 上传
2024-09-06 上传

netshell
- 粉丝: 11
- 资源: 185
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
