C++实现贪心策略:普里姆与克鲁斯卡算法求最小生成树
需积分: 0 96 浏览量
更新于2024-08-04
收藏 160KB DOC 举报
"实验5介绍了贪心算法在寻找图的最小生成树问题中的应用,主要涉及普里姆算法和克鲁斯卡算法。这两个算法都是通过贪心策略来逐步构建最小生成树。"
贪心算法是一种解决最优化问题的策略,它每次选择当前状态下最好的解决方案,希望通过一系列局部最优解来达到全局最优解。在最小生成树问题中,贪心策略被用于找到一个树形结构,使得树中所有边的权重之和最小。
普里姆算法(Prim's Algorithm)是贪心算法的一种实现,主要用于找寻加权无向图的最小生成树。算法从一个起始节点开始,逐步将相邻的最小权重边加入到生成树中,直到包括所有节点。在Prim算法中,集合A最初只包含一个节点,然后每次添加一条连接树内节点和树外节点的最小权重边,直到所有节点都在树中。这个过程可以使用优先队列(如二叉堆)来优化,以O(E log V)的时间复杂度完成,其中E是边的数量,V是节点的数量。
克鲁斯卡算法(Kruskal's Algorithm)则是另一种贪心策略实现,它按照边的权重非递减顺序处理所有边。初始时,每个节点被视为一个独立的连通分量,算法逐步选择一条连接不同连通分量且不会形成环的边(即安全边)。每当添加一条边时,需要使用并查集数据结构来判断两个端点是否已经属于同一个连通分量,以避免形成环。克鲁斯卡算法同样可以在O(E log E)或O(E log V)的时间复杂度内完成,具体取决于并查集的实现。
实验内容包括使用C++编程实现这两种算法,并完成实验报告,分析它们的效率和效果。实验者需要理解图的表示方法,掌握贪心策略的原理,以及并查集和优先队列等数据结构的使用。
Kruskal算法在图的执行流程中,首先对所有边进行排序,然后逐个考虑边,如果加入这条边不会导致环的形成,就将其加入到最小生成树中。这个过程通过并查集维护连通分量,确保不会形成环。
普里姆算法则从一个节点开始,逐步扩展生成树,每次选择与当前树连接的最小权重边。这个过程可以用Dijkstra算法的思路来实现,也可以使用优先队列辅助。
实验5的目标是加深对贪心策略的理解,通过编程实践掌握最小生成树的两种经典算法——普里姆算法和克鲁斯卡算法。
(i)
(j)
(k)
(l)
(m)
(n)
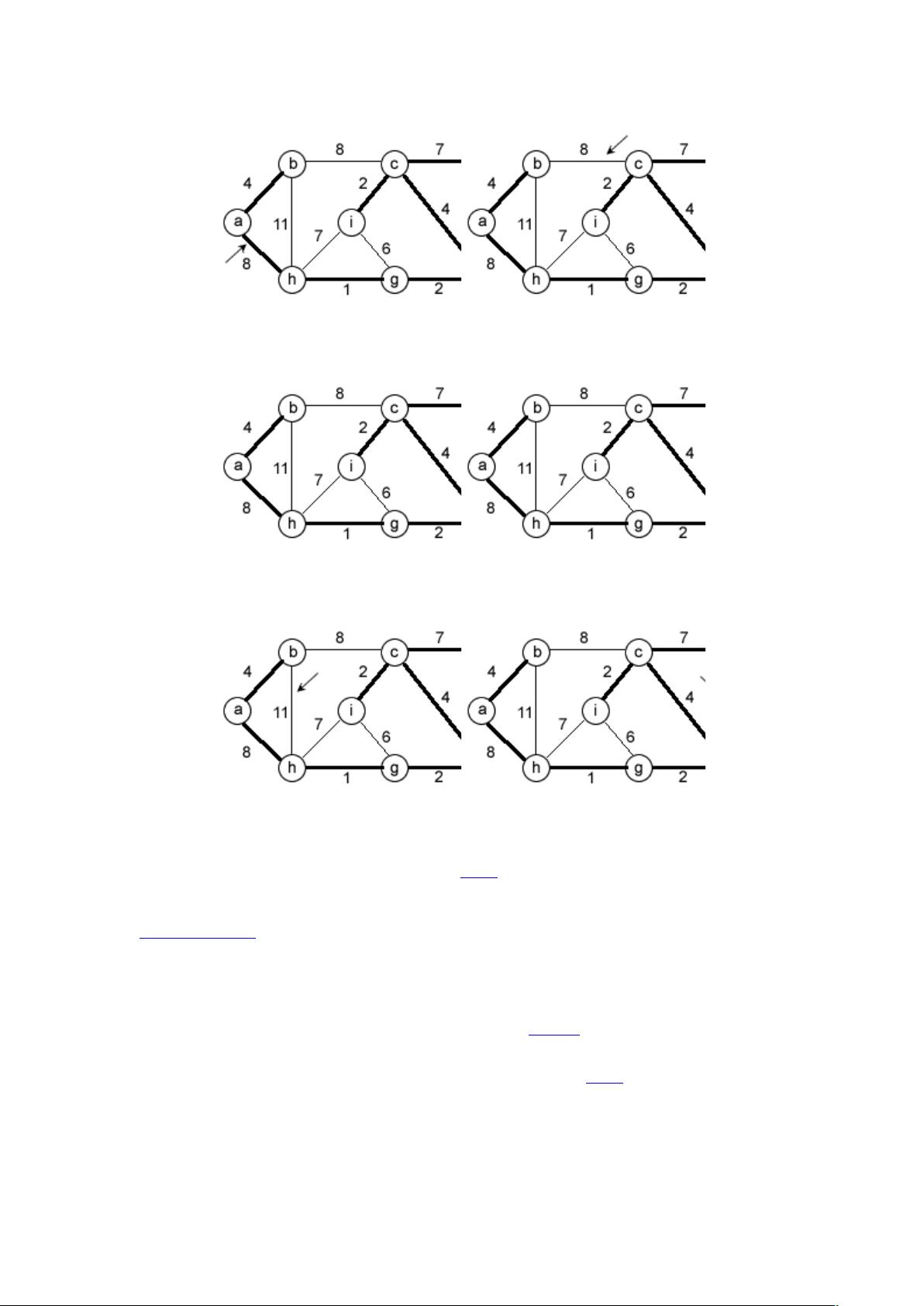
图 3-1 Kruskal 算法在图 1 所示的图上的执行流程
正如 Kruskal 算法一样,PPrim 算法的执行非常类似于寻找图的最短通路的
Dijkstra 算法。Prim 算法的特点是集合 A 中的边总是只形成单棵树。如图 3-2
所示,阴影覆盖的边属于正在生成的树,树中的结点为黑色。在算法的每一步,
树中的结点确定了图的一个割,并且通过该割的轻边被加进树中。树从任意根结
点 r 开始形成并逐渐生长直至该树跨越了 V 中的所有结点。在每一步,连接 A 中
某结点到 V-A 中某结点的轻边被加入到树中,由推论 2,该规则仅加大对 A 安全
的边,因此当算法终止时,A 中的边就成为一棵最小生成树。因为每次添加到树
中的边都是使树的权尽可能小的边,因此上述策略也是贪心的。
有效实现 Prim 算法的关键是设法较容易地选择一条新的边添加到由 A 的边
所形成的树中,在下面的伪代码中,算法的输入是连通图 G 和将生成的最小生成
树的根 r。在算法执行过程中,不在树中的所有结点都驻留于优先级基于 key 域
剩余10页未读,继续阅读
2021-12-08 上传
2021-12-08 上传
242 浏览量
295 浏览量
点击了解资源详情
657 浏览量
2024-12-06 上传
2023-05-13 上传
176 浏览量

m0_71968931
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- VS2010环境Qt链接MySQL数据库测试程序
- daycula-vim主题:黑暗风格的Vim色彩方案
- HTTPComponents最新版本发布,客户端与核心组件升级
- Android WebView与JS互调的实践示例
- 教务管理系统功能全面,操作简便,适用于winxp及以上版本
- 使用堆栈实现四则运算的编程实践
- 开源Lisp实现的联合生成算法及多面体计算
- 细胞图像处理与模式识别检测技术
- 深入解析psimedia:音频视频RTP抽象库
- 传名广告联盟商业正式版 v5.3 功能全面升级
- JSON序列化与反序列化实例教程
- 手机美食餐饮微官网HTML源码开源项目
- 基于联合相关变换的图像识别程序与土豆形貌图片库
- C#毕业设计:超市进销存管理系统实现
- 高效下载地址转换器:迅雷与快车互转
- 探索inoutPrimaryrepo项目:JavaScript的核心应用
