华为高级经理Anoop Sam John分享HBase二级索引优化与实践经验
需积分: 48 149 浏览量
更新于2024-07-23
收藏 619KB PDF 举报
在2012年的HBTC(华为大数据大会)上,华为高级技术经理Anoop Sam John进行了题为《HBase的二级索引》的分享。Anoop在演讲中详细探讨了华为在实际项目中如何优化HBase性能以及他们在Hadoop生态系统中的经验,特别强调了HBase二级索引的重要性。HBase作为NoSQL数据库,原生并不支持二级索引,这使得在处理大量数据时,特别是需要根据列值进行复杂查询时,性能受限。
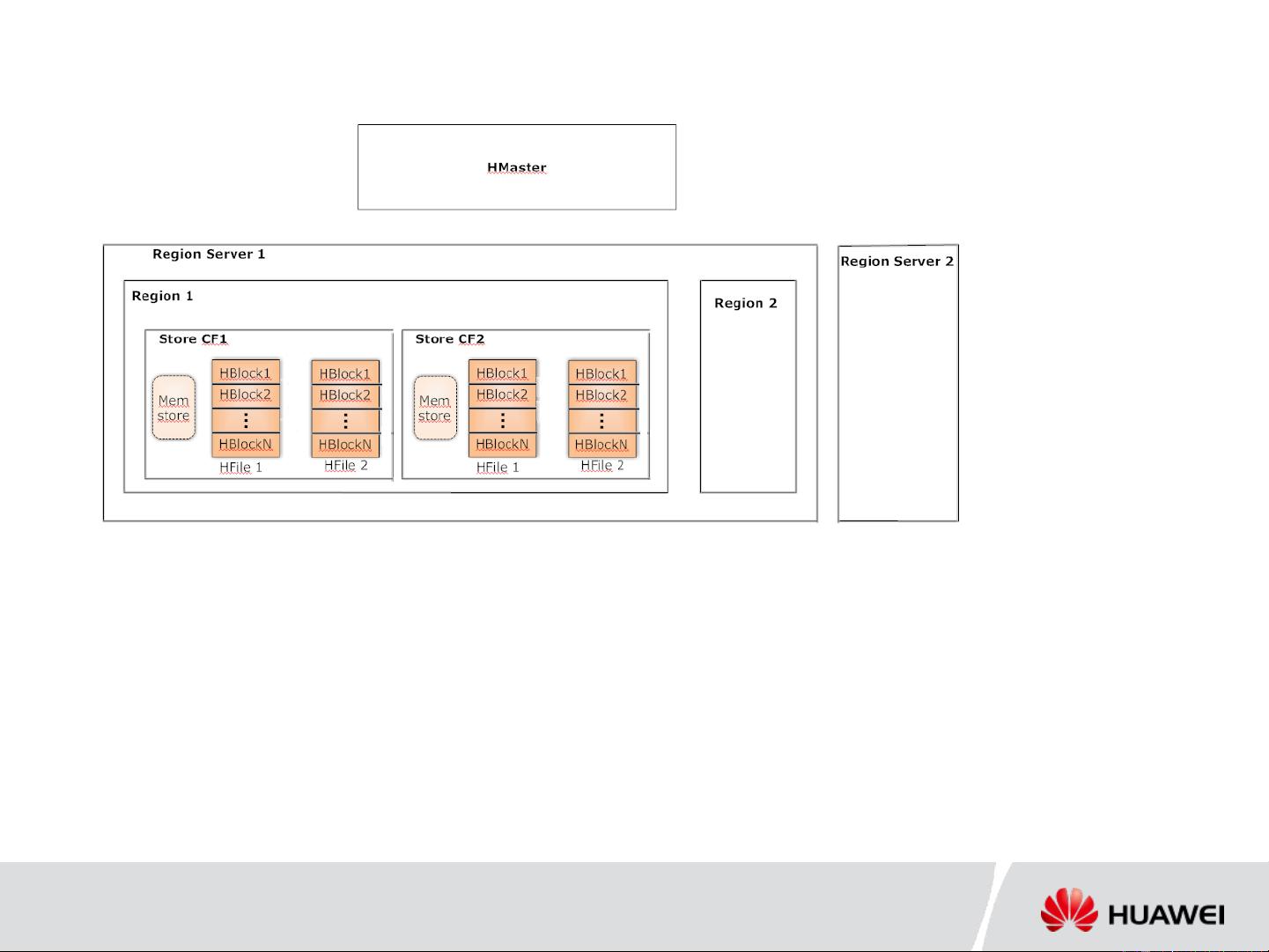
HBase的核心组件包括Master服务器,负责管理整个集群的状态;Region服务器,负责存储和处理数据;以及列式存储结构,其中每个表被分割成多个Region,每个Region由ColumnFamily构成,数据以列族的形式存储在Memstore中。当数据写入或读取时,是以块的形式进行操作的。然而,原始的HBase设计并不支持对数据进行全文索引,这意味着如果需要基于列值进行范围扫描或者条件查询,系统性能可能会受到显著影响。
为了克服这一局限性,华为开发了一套二级索引解决方案。他们将Bookkeeper作为共享存储用于Hadoop的下一代HDFS(Hadoop Distributed File System,HDFS NN HA),这有助于提高数据的一致性和可靠性。此外,他们还在Hadoop 2的YARN(Yet Another Resource Negotiator)架构中实现了MapReduce的高可用性,包括ResourceManager HA和JobTracker HA,以增强整体系统的稳定性和容错性。
Anoop在演讲中分享了华为在HBase开发中的贡献,自2011年以来,他们修复了超过500个缺陷并回馈给了开源社区,对HBase的稳定性和性能优化起到了关键作用。他强调了团队在HBase和Hive等工具上的活跃参与,特别是在用户邮件列表和开发邮件列表中,持续推动着技术的进步。
HBase的二级索引功能允许用户在HBase中创建针对特定列值的索引,极大地提高了查询性能,尤其是在面对大量数据且需要高效过滤和排序时。通过这种方式,华为不仅提升了内部项目的效率,也为其他依赖HBase的开发者提供了实用的工具和参考案例。Anoop Sam John的演讲深入浅出地介绍了华为在HBase二级索引领域的实践和创新,对于理解HBase在大数据场景中的实际应用和优化具有很高的价值。
HUAWEI TECHNOLOGIES CO., LTD.
Slide title :32-35pt
Color: R153 G0 B0
Corporate Font :
FrutigerNext LT Medium
Font to be used by customers
and
partners :
Arial
Slide text :20-22pt
Bullets level 2-5:
18pt
Color:Black
Corporate Font :
FrutigerNext LT Medium
Font to be used by customers
and
partners :
Arial
Top right corner
for field-mark,
customer or partner
logotypes.
----------------
The following nine
groups of colors
are an example of
how our design
colors can be used,
please take note
that you should
only use one
design color group
per slide.
For specific usage
details, refer to the
“Typesetting
Standard”.
Master, Region servers
Table split into regions
Columnar storage, Column family
Memstore, Hfiles in DFS
Hfiles logically split into smaller blocks, data write/read as blocks
HBase Recap
Page 4
剩余17页未读,继续阅读
2019-08-29 上传
2021-04-01 上传
2021-05-18 上传
点击了解资源详情
点击了解资源详情
2021-06-23 上传
2021-05-10 上传
2021-02-15 上传

阿斗
- 粉丝: 28
- 资源: 167
 我的内容管理
展开
我的内容管理
展开







最新资源
- 天池大数据比赛:伪造人脸图像检测技术
- ADS1118数据手册中英文版合集
- Laravel 4/5包增强Eloquent模型本地化功能
- UCOSII 2.91版成功移植至STM8L平台
- 蓝色细线风格的PPT鱼骨图设计
- 基于Python的抖音舆情数据可视化分析系统
- C语言双人版游戏设计:别踩白块儿
- 创新色彩搭配的PPT鱼骨图设计展示
- SPICE公共代码库:综合资源管理
- 大气蓝灰配色PPT鱼骨图设计技巧
- 绿色风格四原因分析PPT鱼骨图设计
- 恺撒密码:古老而经典的替换加密技术解析
- C语言超市管理系统课程设计详细解析
- 深入分析:黑色因素的PPT鱼骨图应用
- 创新彩色圆点PPT鱼骨图制作与分析
- C语言课程设计:吃逗游戏源码分享
