DF-GAN:一阶段高效文本到图像生成网络
PDF格式 | 20.89MB |
更新于2025-01-16
| 67 浏览量 | 举报

16515
0
DF-GAN:一种简单有效的文本到图像合成基准
0
MingTao1HaoTang2FeiWu1XiaoyuanJing3Bing-KunBao1*ChangshengXu4,5,6
0
1南京邮电大学2ETH苏黎世联邦理工学院CVL3武汉大学4彭城实验室5中国科学院大学6
中国科学院自动化研究所NLPR
0
bingkunbao@njupt.edu.cn
0
摘要
0
从文本描述中合成高质量逼真的图像是一项具有挑战性的任
务。现有的文本到图像生成对抗网络通常采用堆叠架构作为
骨干,但仍存在三个缺陷。首先,堆叠架构引入了不同图像
尺度生成器之间的纠缠。其次,现有研究倾向于在对抗学习
中应用和固定额外的网络以实现文本-图像语义一致性,这
限制了这些网络的监督能力。第三,由于计算成本的限制,
先前的工作广泛采用基于跨模态注意力的文本-图像融合仅
限于几个特定的图像尺度。为此,我们提出了一种更简单但
更有效的深度融合生成对抗网络(DF-GAN)。具体而言,
我们提出了:(i)一种新颖的一阶段文本到图像骨干,直接
合成高分辨率图像,而不引入不同生成器之间的纠缠;(ii
)一种新颖的目标感知鉴别器,由匹配感知梯度惩罚和单向
输出组成,增强文本-图像语义一致性,而不引入额外的网
络;(iii)一种新颖的深度文本-图像融合块,通过深化融合
过程实现文本和视觉特征的完全融合。与当前最先进的方法
相比,我们提出的DF-GAN更简单但更高效地合成逼真且与
文本匹配的图像,并在广泛使用的数据集上取得更好的性能
。代码可在https://github.com/tobran/DF-GAN上获得。
0
1.引言
0
在过去的几年中,生成对抗网络(GANs)在各种应用中取
得了巨大的成功[4,27,
48]。其中,文本到图像合成是GANs最重要的应用之一。
0
*通讯作者
0
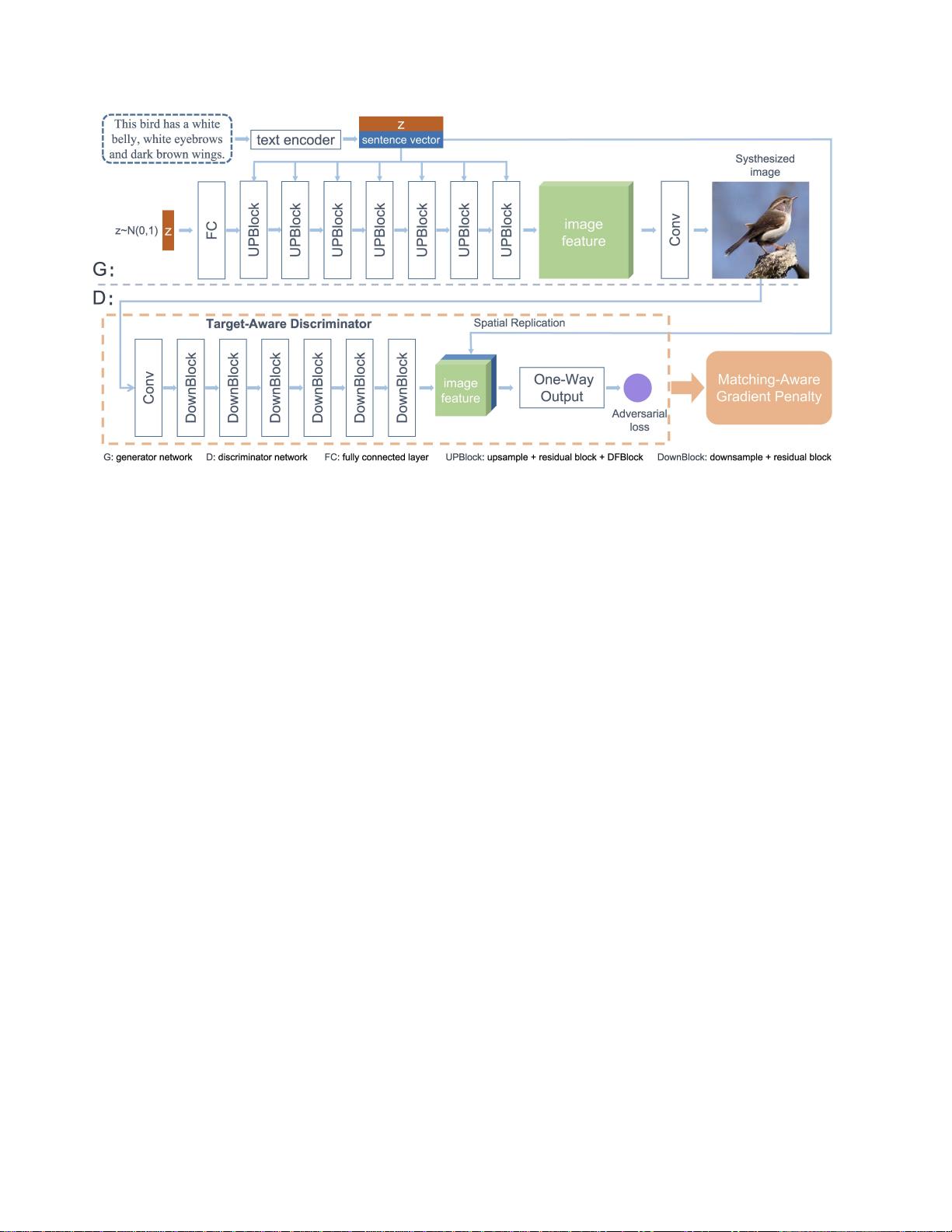
图1.(a)现有的文本到图像模型堆叠多个生成器以生成高分辨率图
像。(b)我们提出的DF-GAN直接生成高质量图像,并通过我们的
深度文本-图像融合块深度融合文本和图像特征。
0
它旨在从给定的自然语言描述中生成逼真且文本一致的图像
。由于其实用价值,文本到图像合成最近已成为一个活跃的
研究领域[3,9,13,19-21,32,33,35,51,53,
60]。文本到图像合成面临的两个主要挑战是生成图像的真
实性以及给定文本和生成图像之间的语义一致性。由于GAN
模型的不稳定性,大多数最近的模型采用堆叠架构[56,
57]作为生成高分辨率图像的骨干。它们使用跨模态注意力
来融合文本和图像特征[37,50,56,57,
60],然后引入DAMSM网络[50]、循环一致性[33]或孪生网
络[51]通过额外的网络来确保文本-图像语义一致性。尽管之
前的研究[9,19,21,32,33,51,
60]已经取得了令人印象深刻的结果,但仍然存在三个问题
。首先,堆叠架构[56]引入了不同生成器之间的纠缠,这使
得最终的精细图像看起来像是模糊形状和一些细节的简单组
合。如图1(a)所示,最终的精细图像由G0合成的模糊形状、
由G0合成的粗糙属性(例如眼睛和喙)组成。

剩余10页未读,继续阅读
相关推荐



60 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网页自动刷新工具 v1.1 - 自定义时间间隔与关机
- pt-1.4协程源码深度解析
- EP4CE6E22C8芯片三相正弦波发生器设计与实现
- 高效处理超大XML文件的查看工具介绍
- 64K极限挑战:国际程序设计大赛优秀3D作品展
- ENVI软件全面应用教程指南
- 学生档案管理系统设计与开发
- 网络伪书:社区驱动的在线音乐制图平台
- Lettuce 5.0.3中文API文档完整包下载指南
- 雅虎通Yahoo! Messenger v0.8.115即时聊天功能详解
- 将Android手机转变为IP监控摄像机
- PLSQL入门教程:变量声明与程序交互
- 掌握.NET三层架构:实例学习与源码解析
- WPF中Devexpress GridControl分组功能实例分析
- H3Viewer: VS2010专用高效帮助文档查看工具
- STM32CubeMX LED与按键初始化及外部中断处理教程
