{"level": 18, "resolution": 2.68220901489258E-06, "scale": 1127.2338812669175}
时间: 2024-02-09 08:05:49 浏览: 73
根据给出的信息,{"level": 18, "resolution": 2.68220901489258E-06, "scale": 1127.2338812669175},可以推断出这是一组地理坐标信息。其中,"level"表示地图的缩放级别,"resolution"表示每个像素代表的实际距离,"scale"表示地图的比例尺。
具体解释如下:
- "level":地图的缩放级别是指地图显示的细节程度。较小的缩放级别表示更大范围的地图,而较大的缩放级别表示更详细的地图。
- "resolution":地图分辨率是指每个像素代表的实际距离。较小的分辨率表示地图显示更详细的细节,而较大的分辨率表示地图显示更广阔的范围。
- "scale":地图比例尺是指地图上距离的度量与实际距离之间的比例关系。较大的比例尺表示地图显示更详细的细节,而较小的比例尺表示地图显示更广阔的范围。
这些信息通常用于地理信息系统(GIS)中,用于确定地图上特定位置的坐标和缩放级别。
相关问题
已知瓦片参数 {"level": 18, "resolution": 2.68220901489258E-06, "scale": 1127.2338812669175},求瓦片实际边长是多少米
已知瓦片参数为{"level": 18, "resolution": 2.68220901489258E-06, "scale": 1127.2338812669175},其中"resolution"表示每个像素对应的地理距离,"scale"表示每个像素对应的地理距离与屏幕上的像素距离的比例。
要求瓦片实际边长,可以使用以下公式计算:
瓦片实际边长 = 瓦片像素边长 * resolution * scale
根据瓦片级别(level)的定义,瓦片像素边长为256像素。将该值代入公式中,可以得到:
瓦片实际边长 = 256 * 2.68220901489258E-06 * 1127.2338812669175
计算结果为:
瓦片实际边长约为 0.077 meters(米)。
Warning: convergence tolerance of 1.000000e-06 not reached
This warning message usually appears in numerical optimization or iterative methods when the desired level of accuracy or convergence has not been achieved. It means that the optimization algorithm or iterative method did not converge to the desired solution within the specified tolerance level.
To address this warning, one can try the following:
1. Increase the convergence tolerance level to allow for more iterations and a higher degree of accuracy.
2. Use a different optimization algorithm or iterative method that is better suited for the specific problem.
3. Check the inputs and parameters of the optimization problem to ensure they are correct and appropriate.
4. Use a different initial guess or starting point for the optimization algorithm.
5. Check for any errors or bugs in the code that may be causing the convergence issue.
It is important to note that this warning does not necessarily mean that the solution obtained is incorrect or unusable. However, it is always a good practice to investigate the reasons for the warning and ensure that the optimization results are reliable and accurate.
相关推荐
最新推荐
Android 出现:java.lang.NoClassDefFoundError...错误解决办法
2. 正确地重写`Activity`的生命周期方法。在上述问题中,开发者可能错误地重写了带有两个参数(`Bundle`和`PersistableBundle`)的`onCreate()`和`onSaveInstanceState()`方法。对于API Level 21以下的设备,应确保...
FPGA_Zynq UltraScale+ MPSoC 数据手册:概述_(Xilinx).pdf
* 1MB 16-way set-associative Level 2 缓存带 ECC(共享于多个 CPU) 双核 Arm Cortex-R5 基于实时处理单元(RPU): * 双核 Arm Cortex-R5 * CPU 频率:高达 533MHz * 可扩展的 Cache 一致性 * Armv7-A 架构: ...
java-high-level-REST-client.pdf
高可用 REST 客户端的坐标在描述中未给出,通常会以类似于 `org.elasticsearch.client:elasticsearch-rest-high-level-client:<version>` 的形式存在,`<version>` 应替换为实际的 Elasticsearch 客户端版本号。...
编译mtk-openwrt-lede-4.2.0.0内核 usb网卡实现huawei_E8372h-155_4G转有线和WIFI
在本文中,我们将深入探讨如何在Ubuntu 16.04环境下编译MTK(MediaTek)OpenWRT LEDE 4.2.0.0内核,以便支持华为E8372h-155 4G LTE模块,将其转换为有线网络和Wi-Fi热点。这一过程涉及对内核进行定制,以及在OpenWRT...
解决出现Incorrect integer value: '' for column 'id' at row 1的问题
except Exception as e: print(e) self.cursor = self.conn.cursor() ``` 在处理数据库异常时,应尽可能捕获具体的异常类型,而不是使用通用的`Exception`,以便更准确地诊断和解决问题。例如,可以捕获`MySQLdb...
最优条件下三次B样条小波边缘检测算子研究
"这篇文档是关于B样条小波在边缘检测中的应用,特别是基于最优条件的三次B样条小波多尺度边缘检测算子的介绍。文档涉及到图像处理、计算机视觉、小波分析和优化理论等多个IT领域的知识点。"
在图像处理中,边缘检测是一项至关重要的任务,因为它能提取出图像的主要特征。Canny算子是一种经典且广泛使用的边缘检测算法,但它并未考虑最优滤波器的概念。本文档提出了一个新的方法,即基于三次B样条小波的边缘提取算子,该算子通过构建目标函数来寻找最优滤波器系数,从而实现更精确的边缘检测。
小波分析是一种强大的数学工具,它能够同时在时域和频域中分析信号,被誉为数学中的"显微镜"。B样条小波是小波家族中的一种,尤其适合于图像处理和信号分析,因为它们具有良好的局部化性质和连续性。三次B样条小波在边缘检测中表现出色,其一阶导数可以用来检测小波变换的局部极大值,这些极大值往往对应于图像的边缘。
文档中提到了Canny算子的三个最优边缘检测准则,包括低虚假响应率、高边缘检测概率以及单像素宽的边缘。作者在此基础上构建了一个目标函数,该函数考虑了这些准则,以找到一组最优的滤波器系数。这些系数与三次B样条函数构成的线性组合形成最优边缘检测算子,能够在不同尺度上有效地检测图像边缘。
实验结果表明,基于最优条件的三次B样条小波边缘检测算子在性能上优于传统的Canny算子,这意味着它可能提供更准确、更稳定的边缘检测结果,这对于计算机视觉、图像分析以及其他依赖边缘信息的领域有着显著的优势。
此外,文档还提到了小波变换的定义,包括尺度函数和小波函数的概念,以及它们如何通过伸缩和平移操作来适应不同的分析需求。稳定性条件和重构小波的概念也得到了讨论,这些都是理解小波分析基础的重要组成部分。
这篇文档深入探讨了如何利用优化理论和三次B样条小波改进边缘检测技术,对于从事图像处理、信号分析和相关研究的IT专业人士来说,是一份极具价值的学习资料。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
递归阶乘速成:从基础到高级的9个优化策略
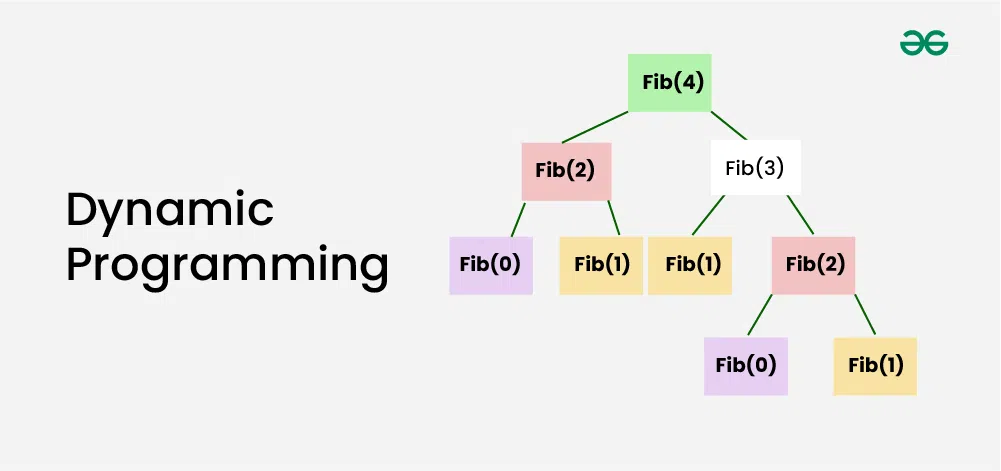
# 1. 递归阶乘算法的基本概念
在计算机科学中,递归是一种常见的编程技巧,用于解决可以分解为相似子问题的问题。阶乘函数是递归应用中的一个典型示例,它计算一个非负整数的阶乘,即该数以下所有正整数的乘积。阶乘通常用符号"!"表示,例如5的阶乘写作5! = 5 * 4 * 3 * 2 * 1。通过递归,我们可以将较大数的阶乘计算简化为更小数的阶乘计算,直到达到基本情况
pcl库在CMakeLists。txt配置
PCL (Point Cloud Library) 是一个用于处理点云数据的开源计算机视觉库,常用于机器人、三维重建等应用。在 CMakeLists.txt 文件中配置 PCL 需要以下步骤:
1. **添加找到包依赖**:
在 CMakeLists.txt 的顶部,你需要找到并包含 PCL 的 CMake 找包模块。例如:
```cmake
find_package(PCL REQUIRED)
```
2. **指定链接目标**:
如果你打算在你的项目中使用 PCL,你需要告诉 CMake 你需要哪些特定组件。例如,如果你需要 PointCloud 和 vi
深入解析:wav文件格式结构
"该文主要深入解析了wav文件格式,详细介绍了其基于RIFF标准的结构以及包含的Chunk组成。"
在多媒体领域,WAV文件格式是一种广泛使用的未压缩音频文件格式,它的基础是Resource Interchange File Format (RIFF) 标准。RIFF是一种块(Chunk)结构的数据存储格式,通过将数据分为不同的部分来组织文件内容。每个WAV文件由几个关键的Chunk组成,这些Chunk共同定义了音频数据的特性。
1. RIFFWAVE Chunk
RIFFWAVE Chunk是文件的起始部分,其前四个字节标识为"RIFF",紧接着的四个字节表示整个Chunk(不包括"RIFF"和Size字段)的大小。接着是'RiffType',在这个情况下是"WAVE",表明这是一个WAV文件。这个Chunk的作用是确认文件的整体类型。
2. Format Chunk
Format Chunk标识为"fmt",是WAV文件中至关重要的部分,因为它包含了音频数据的格式信息。例如,采样率、位深度、通道数等都在这个Chunk中定义。这些参数决定了音频的质量和大小。Format Chunk通常包括以下子字段:
- Audio Format:2字节,表示音频编码格式,如PCM(无损)或压缩格式。
- Num Channels:2字节,表示音频的声道数,如单声道(1)或立体声(2)。
- Sample Rate:4字节,表示每秒的样本数,如44100 Hz。
- Byte Rate:4字节,每秒音频数据的字节数,等于Sample Rate乘以Bits Per Sample和Num Channels。
- Block Align:2字节,每个样本数据的字节数,等于Bits Per Sample除以8乘以Num Channels。
- Bits Per Sample:2字节,每个样本的位深度,影响声音质量和文件大小。
3. Fact Chunk(可选)
Fact Chunk标识为'fact',虽然不是所有WAV文件都包含此Chunk,但它提供了额外的样本信息,如实际的样本数,对于非整数倍采样率的文件尤其有用。
4. Data Chunk
Data Chunk标识为'data',是WAV文件中真正包含音频样本数据的部分。其ID后面是4字节的Size字段,表示数据区域的大小,不包括ID和Size本身。这个Chunk的内容就是连续的音频样本值,根据Format Chunk定义的格式进行编码。
所有Chunk的大小字段都是以低字节在前,高字节在后的顺序存储,这是遵循了RIFF格式的规定。理解这些Chunk的结构和内容对于处理和分析WAV文件至关重要,无论是编程处理音频数据还是进行音频文件的转换和编辑。