ls = jieba.lcut(t)
时间: 2024-04-12 07:27:13 浏览: 152
你好!你的第一个问题是关于 `jieba.lcut(t)` 的用法。`jieba.lcut()` 是结巴分词库的一个函数,用于将文本 `t` 进行中文分词。它会将文本分割成一个词列表,并返回该列表。
`ls` 是接收分词结果的变量名,你可以根据需要自行命名。使用 `jieba.lcut()` 函数需要先安装和导入结巴分词库。你可以通过以下步骤来实现:
1. 在终端或命令行中使用 `pip` 安装结巴分词库:`pip install jieba`
2. 在 Python 代码中导入结巴分词库:`import jieba`
然后,你可以使用 `jieba.lcut(t)` 对文本 `t` 进行分词,将结果存储在 `ls` 变量中。例如:
```python
import jieba
t = "我喜欢自然语言处理"
ls = jieba.lcut(t)
print(ls)
```
输出结果将是 `['我', '喜欢', '自然语言处理']`,即将文本分割成了一个词列表。希望这个回答能对你有所帮助!如果你还有其他问题,请随时提问。
相关问题
ls=jieba.lcut()
这是一个 Python 代码示例,使用了 jieba 库中的 lcut 函数对文本进行分词。lcut 函数将文本作为输入,返回一个列表,其中每个元素是一个分好的词语。具体的代码实现可能类似于下面这样:
```
import jieba
text = "我爱自然语言处理"
word_list = jieba.lcut(text)
print(word_list)
```
输出结果为:
```
['我', '爱', '自然语言处理']
```
这里的 `ls` 可能是一个变量名,用来存储分好词的结果。
ls = jieba.lcut(qq)是什么意思
在Python中,jieba是一种中文分词工具,可以将中文文本按照词语进行分割。其中,lcut()函数是jieba库中的一个分词函数,用于对文本进行分词操作,并返回一个列表,其中每个元素都是一个分好的词语。
具体来说,如果我们有一个中文文本qq,可以使用以下语句将其分词:
```
import jieba
qq = "我爱自然语言处理"
ls = jieba.lcut(qq)
print(ls)
```
输出结果为:
```
['我', '爱', '自然语言处理']
```
在上面的代码中,我们首先导入了jieba库,然后定义了一个中文文本qq。接着,使用jieba.lcut()函数对qq进行分词操作,并将结果存储在变量ls中。最后,我们将ls列表打印出来,可以看到其中的每个元素都是一个分好的词语。
使用分词工具可以方便地对中文文本进行处理和分析,是自然语言处理中的重要步骤之一。分词的结果可以用于文本挖掘、信息检索、语义分析等多个领域。
阅读全文
相关推荐
大家在看
SHIMAX_MAC3&MAC50通讯手册
日本SHIMAX_MAC3&MAC50通讯手册
基于综合评价语义描述的领域本体构建 (2013年)
基于领域综合评价的指标体系分析其所描述的语义概念,并对指标进行预处理,提取评价指标所表述的概念以及指标间的关系.根据这些概念和关系构建基础本体,通过生成概念格对该本体的概念描述进一步丰富,并生成更完善的概念格.最后利用形式概念分析的方法和工具构建领域本体.
ansys workbench 非线性分析
ansys workbench 非线性教程
hw1.rar_C++图像插值_二维插值_二维插值 C++_图像_最近邻插值
图像处理,对源图像进行扭曲,采用最近邻、二维插值和三次样条插值。
Chamber and Station test.pptx
Chamber and Station test.pptx
最新推荐
博途1200恒压供水程序,恒压供水,一拖三,PID控制,3台循环泵,软启动工作,带超压,缺水保护,西门子1200+KTP1000触摸屏
博途1200恒压供水程序,恒压供水,一拖三,PID控制,3台循环泵,软启动工作,带超压,缺水保护,西门子1200+KTP1000触摸屏
基于PLC的立体车库,升降横移立体车库设计,立体车库仿真,三层三列立体车库,基于s7-1200的升降横移式立体停车库的设计,基于西门子博图S7-1200plc与触摸屏HMI的3x3智能立体车库仿真控制
基于PLC的立体车库,升降横移立体车库设计,立体车库仿真,三层三列立体车库,基于s7-1200的升降横移式立体停车库的设计,基于西门子博图S7-1200plc与触摸屏HMI的3x3智能立体车库仿真控制系统设计,此设计为现成设计,模拟PLC与触摸屏HMI联机,博图版本V15或V15V以上
此设计包含PLC程序、触摸屏界面、IO表和PLC原理图
锂电池化成机 姆龙NJ NX程序,NJ501-1400,威伦通触摸屏,搭载GX-JC60分支器进行分布式总线控制,ID262.OD2663等输入输出IO模块ADA801模拟量模块 全自动锂电池化成分容
锂电池化成机 姆龙NJ NX程序,NJ501-1400,威伦通触摸屏,搭载GX-JC60分支器进行分布式总线控制,ID262.OD2663等输入输出IO模块ADA801模拟量模块
全自动锂电池化成分容机,整机采用EtherCAT总线网络节点控制,
埃斯顿总线伺服,埃斯顿机器人动作控制,AD压力模拟量控制伺服电机进行定位运动,雷赛DM3E步进总线控制,触摸屏读写步进电机电流,极性,方向等参数。
触摸屏产量统计。
涵盖人机配方一键型功能,故障记录功能,st+梯形图编写,注释齐全。
西门子Siemens PLC程序,博途V16 V17版,配方程序,RS485通讯控制变频器启停及速度控制,昆仑通态屏与1200通讯S7~1200为cPU为1214,屏采用为mgcS,程序案例
西门子Siemens PLC程序,博途V16 V17版,配方程序,RS485通讯控制变频器启停及速度控制,昆仑通态屏与1200通讯S7~1200为cPU为1214,屏采用为mgcS,程序案例
c3560c405-universalk9-mz.150-2.SE.bin
c3560c405-universalk9-mz.150-2.SE.bin
3dsmax高效建模插件Rappatools3.3发布,附教程
资源摘要信息:"Rappatools3.3.rar是一个与3dsmax软件相关的压缩文件包,包含了该软件的一个插件版本,名为Rappatools 3.3。3dsmax是Autodesk公司开发的一款专业的3D建模、动画和渲染软件,广泛应用于游戏开发、电影制作、建筑可视化和工业设计等领域。Rappatools作为一个插件,为3dsmax提供了额外的功能和工具,旨在提高用户的建模效率和质量。"
知识点详细说明如下:
1. 3dsmax介绍:
3dsmax,又称3D Studio Max,是一款功能强大的3D建模、动画和渲染软件。它支持多种工作流程,包括角色动画、粒子系统、环境效果、渲染等。3dsmax的用户界面灵活,拥有广泛的第三方插件生态系统,这使得它成为3D领域中的一个行业标准工具。
2. Rappatools插件功能:
Rappatools插件专门设计用来增强3dsmax在多边形建模方面的功能。多边形建模是3D建模中的一种技术,通过添加、移动、删除和修改多边形来创建三维模型。Rappatools提供了大量高效的工具和功能,能够帮助用户简化复杂的建模过程,提高模型的质量和完成速度。
3. 提升建模效率:
Rappatools插件中可能包含诸如自动网格平滑、网格优化、拓扑编辑、表面细分、UV展开等高级功能。这些功能可以减少用户进行重复性操作的时间,加快模型的迭代速度,让设计师有更多时间专注于创意和细节的完善。
4. 压缩文件内容解析:
本资源包是一个压缩文件,其中包含了安装和使用Rappatools插件所需的所有文件。具体文件内容包括:
- index.html:可能是插件的安装指南或用户手册,提供安装步骤和使用说明。
- license.txt:说明了Rappatools插件的使用许可信息,包括用户权利、限制和认证过程。
- img文件夹:包含用于文档或界面的图像资源。
- js文件夹:可能包含JavaScript文件,用于网页交互或安装程序。
- css文件夹:可能包含层叠样式表文件,用于定义网页或界面的样式。
5. MAX插件概念:
MAX插件指的是专为3dsmax设计的扩展软件包,它们可以扩展3dsmax的功能,为用户带来更多方便和高效的工作方式。Rappatools属于这类插件,通过在3dsmax软件内嵌入更多专业工具来提升工作效率。
6. Poly插件和3dmax的关系:
在3D建模领域,Poly(多边形)是构建3D模型的主要元素。所谓的Poly插件,就是指那些能够提供额外多边形建模工具和功能的插件。3dsmax本身就支持强大的多边形建模功能,而Poly插件进一步扩展了这些功能,为3dsmax用户提供了更多创建复杂模型的方法。
7. 增强插件的重要性:
在3D建模和设计行业中,增强插件对于提高工作效率和作品质量起着至关重要的作用。随着技术的不断发展和客户对视觉效果要求的提高,插件能够帮助设计师更快地完成项目,同时保持较高的创意和技术水准。
综上所述,Rappatools3.3.rar资源包对于3dsmax用户来说是一个很有价值的工具,它能够帮助用户在进行复杂的3D建模时提升效率并得到更好的模型质量。通过使用这个插件,用户可以在保持工作流程的一致性的同时,利用额外的工具集来优化他们的设计工作。
【R-Studio技术路径】:从RAID 5数据恢复基础到高级操作
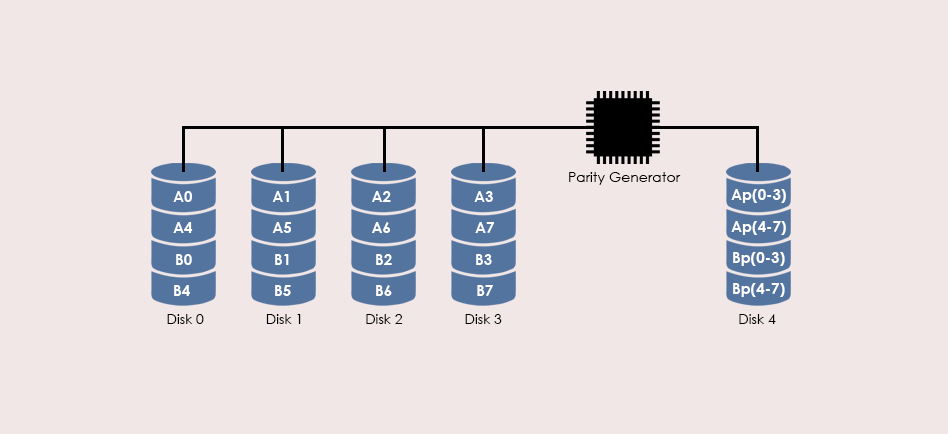
# 摘要
随着信息技术的发展,数据丢失问题日益突出,RAID 5作为常见的数据存储解决方案,其数据恢复技术显得尤为重要。本文首先介绍了RAID 5数据恢复的基础知识,然后详细解析了R-Studio软件的界面和核心功能,重点探讨了其在RAID 5数据恢复中的应用实践,包括磁盘镜像创建、数据提取、数据重组策略及一致性验证。进一步,本文还涉及了R-Studio的进阶技术,如脚本编
``` 定义1个圆类,成员有:1个半径成员变量,1个构造方法给成员变量赋初值,1个求面积方法。```定义1个圆类,成员有:1个半径成员变量,1个构造方法给成员变量赋初值,1个求面积方法。
当然,我们可以定义一个简单的`Circle`类,如下所示:
```java
public class Circle {
// 定义一个私有的半径成员变量
private double radius;
// 构造方法,用于初始化半径
public Circle(double initialRadius) {
this.radius = initialRadius;
}
// 求圆面积的方法
public double getArea() {
return Math.PI * Math.pow(radiu
Ruby实现PointInPolygon算法:判断点是否在多边形内
资源摘要信息:"PointInPolygon算法的Ruby实现是一个用于判断点是否在多边形内部的库。该算法通过计算点与多边形边界交叉线段的交叉次数来判断点是否在多边形内部。如果交叉数为奇数,则点在多边形内部,如果为偶数或零,则点在多边形外部。库中包含Pinp::Point类和Pinp::Polygon类。Pinp::Point类用于表示点,Pinp::Polygon类用于表示多边形。用户可以向Pinp::Polygon中添加点来构造多边形,然后使用contains_point?方法来判断任意一个Pinp::Point对象是否在该多边形内部。"
1. Ruby语言基础:Ruby是一种动态、反射、面向对象、解释型的编程语言。它具有简洁、灵活的语法,使得编写程序变得简单高效。Ruby语言广泛用于Web开发,尤其是Ruby on Rails这一著名的Web开发框架就是基于Ruby语言构建的。
2. 类和对象:在Ruby中,一切皆对象,所有对象都属于某个类,类是对象的蓝图。Ruby支持面向对象编程范式,允许程序设计者定义类以及对象的创建和使用。
3. 算法实现细节:算法基于数学原理,即计算点与多边形边界线段的交叉次数。当点位于多边形内时,从该点出发绘制射线与多边形边界相交的次数为奇数;如果点在多边形外,交叉次数为偶数或零。
4. Pinp::Point类:这是一个表示二维空间中的点的类。类的实例化需要提供两个参数,通常是点的x和y坐标。
5. Pinp::Polygon类:这是一个表示多边形的类,由若干个Pinp::Point类的实例构成。可以使用points方法添加点到多边形中。
6. contains_point?方法:属于Pinp::Polygon类的一个方法,它接受一个Pinp::Point类的实例作为参数,返回一个布尔值,表示传入的点是否在多边形内部。
7. 模块和命名空间:在Ruby中,Pinp是一个模块,模块可以用来将代码组织到不同的命名空间中,从而避免变量名和方法名冲突。
8. 程序示例和测试:Ruby程序通常包含方法调用、实例化对象等操作。示例代码提供了如何使用PointInPolygon算法进行点包含性测试的基本用法。
9. 边缘情况处理:算法描述中提到要添加选项测试点是否位于多边形的任何边缘。这表明算法可能需要处理点恰好位于多边形边界的情况,这类点在数学上可以被认为是既在多边形内部,又在多边形外部。
10. 文件结构和工程管理:提供的信息表明有一个名为"PointInPolygon-master"的压缩包文件,表明这可能是GitHub等平台上的一个开源项目仓库,用于管理PointInPolygon算法的Ruby实现代码。文件名称通常反映了项目的版本管理,"master"通常指的是项目的主分支,代表稳定版本。
11. 扩展和维护:算法库像PointInPolygon这类可能需要不断维护和扩展以适应新的需求或修复发现的错误。开发者会根据实际应用场景不断优化算法,同时也会有社区贡献者参与改进。
12. 社区和开源:Ruby的开源生态非常丰富,Ruby开发者社区非常活跃。开源项目像PointInPolygon这样的算法库在社区中广泛被使用和分享,这促进了知识的传播和代码质量的提高。
以上内容是对给定文件信息中提及的知识点的详细说明。根据描述,该算法库可用于各种需要点定位和多边形空间分析的场景,例如地理信息系统(GIS)、图形用户界面(GUI)交互、游戏开发、计算机图形学等领域。
【R-Studio恢复工具解析】:RAID 5恢复的功能优势与实际应用

# 摘要
RAID 5技术因其高效的数据存储和容错能力被广泛应用。然而,数据丢失问题仍时有发生,R-Studio作为一种功能强大的恢复工具,为解决这一问题提供了有效的技术方案。本文概述了RAID 5的基本概念、R-Studio的理论基础及其数据恢复原理。通过分析R-Studio的主要功能和恢复流程,本文还探讨了该工具