各因素的权重分别为 0.594、0.089、0.775、0.089。将其归一化处理
时间: 2024-01-13 19:05:43 浏览: 44
首先,需要将各因素的权重值相加,即0.594 + 0.089 + 0.775 + 0.089 = 1.547。然后,对每个因素的权重值进行归一化处理,方法是将每个因素的权重值除以它们的和,即:
0.594 / 1.547 = 0.384
0.089 / 1.547 = 0.057
0.775 / 1.547 = 0.501
0.089 / 1.547 = 0.057
因此,归一化后各因素的权重分别为 0.384、0.057、0.501、0.057。
相关问题
0.1812主观权重和0.3769客观权重怎么得到0.3173综合权
综合权重可以通过对主观权重和客观权重进行加权平均得到。具体地,可以使用以下公式计算综合权重:
综合权重 = 主观权重 × α + 客观权重 × (1 - α)
其中,α是一个介于0和1之间的权重因子,表示主观和客观权重在综合权重中的比例。通常情况下,α的值可以根据具体应用场景进行调整。
将给定的权重值代入公式,可以得到:
综合权重 = 0.1812 × α + 0.3769 × (1 - α)
当α取0.5时,即主观和客观权重在综合权重中的比例相等时,可以得到:
综合权重 = 0.1812 × 0.5 + 0.3769 × 0.5 = 0.27905
因此,当主观权重和客观权重分别为0.1812和0.3769时,综合权重为0.27905。如果要调整主观和客观权重在综合权重中的比例,只需要调整α的值即可。
0.1812主观权重和0.3769客观权重怎么得到0.3173综合权重
综合权重可以通过加权平均的方式计算得出。假设主观权重为w1,客观权重为w2,则综合权重可以表示为:
综合权重 = w1 × 主观权重 + w2 × 客观权重
将w1 = 0.1812,w2 = 0.3769代入上式,得到:
综合权重 = 0.1812 × 0.3173 + 0.3769 × 0.3173
综合权重 = 0.0575 + 0.1200
综合权重 = 0.1775
因此,将0.1812主观权重和0.3769客观权重加权平均得到的综合权重为0.3173。
相关推荐
最新推荐
解决Tensorflow2.0 tf.keras.Model.load_weights() 报错处理问题
这里将`epochs`设置为0,目的是让模型在不进行实际训练的情况下完成编译,从而确定输入形状。这样,后续调用`load_weights`就不会出现错误。 接下来,我们探讨一下使用`keras.models.load_model`时可能遇到的问题:...
对tensorflow中tf.nn.conv1d和layers.conv1d的区别详解
size`(等同于`filter_width`),`strides`,`padding`等参数,但它还支持`activation`(默认为None,可以设置为ReLU等激活函数)、`use_bias`(是否使用偏置项,默认为True)、`kernel_regularizer`(权重正则化)...
vgg16.npy,vgg19.npy
VGG16模型的特点是深度极深,拥有16个处理层,其中包含13个卷积层和3个全连接层。它的设计遵循一个简单的原则:使用小尺寸的卷积核(3x3)进行多次卷积,而不是大尺寸的卷积核。这种设计使得网络可以逐步捕获更复杂...
使用Keras 实现查看model weights .h5 文件的内容
在深度学习领域,模型的权重是训练过程中学习到的关键参数,它们决定了模型的预测能力。Keras 是一个高级神经网络 API,它构建在 TensorFlow、Theano 和 CNTK 等后端之上,提供了一种便捷的方式来创建和训练深度学习...
在keras中model.fit_generator()和model.fit()的区别说明
它们都用于更新模型的权重以最小化损失函数,但针对不同类型的输入数据和场景有不同的适用性。 首先,`model.fit()`是Keras中最基础的训练接口,它期望输入数据`x_train`和目标变量`y_train`已经完全加载到内存中。...
C++中的条件运算符详解
"条件运算符是C++中的三目运算符,用于根据条件选择执行不同的表达式。表达式1?表达式2:表达式3的结构中,如果表达式1的值为真(非零),则执行表达式2;否则执行表达式3。在示例中,max=a>b?a:b用于求a和b中的较大值。条件运算符的优先级高于赋值运算符,例如在x=(x=3)?x+2:x-3中,先进行x=3的赋值,然后根据结果决定执行x+2还是x-3。表达式可以有不同类型的,如z=a>b?'A':a+b,这里结合了字符和数值运算。C++的发展历程中,C语言作为基础,C++在其之上进行了扩展和完善,强调面向对象编程。C语言的特点包括结构化、混合级别(高级和汇编)、可移植性以及灵活但语法不严密,对初学者有一定挑战。"
在深入探讨条件运算符之前,让我们首先回顾一下C++的基本概念。C++是一种强大的、面向对象的编程语言,由Bjarne Stroustrup在C语言的基础上创建。它不仅包含了C语言的所有特性,还引入了类、模板、异常处理等面向对象的概念。
条件运算符,也称为三元运算符,是C++中的一个特殊语法构造,其形式为`expression1 ? expression2 : expression3`。这个运算符根据`expression1`的结果来决定执行`expression2`或`expression3`。如果`expression1`的值非零(即逻辑上为真),则`expression2`的值将被计算并作为整个表达式的结果;反之,如果`expression1`的值为零(逻辑上为假),则`expression3`的值将被计算并返回。这种运算符常用于简单的条件选择,特别是在需要根据条件分配变量值时。
在实际编程中,条件运算符可以提高代码的紧凑性和可读性。例如,`max=a>b?a:b`这个语句用于找出`a`和`b`中的较大值。如果`a`大于`b`,则`max`将被赋值为`a`;否则,`max`将被赋值为`b`。这个运算符的优先级高于赋值运算符,这意味着在`x=(x=3)?x+2:x-3`这样的表达式中,首先执行`x=3`,然后根据`x`的新值决定执行`x+2`还是`x-3`。
在C++中,条件运算符允许三个表达式有不同的类型。例如,`z=a>b?'A':a+b`这个表达式中,`'A'`是一个字符,`a+b`是一个数值,但编译器会自动处理这种类型转换,使得整个表达式能够正常工作。
C语言是C++的前身,以其简洁、灵活性和高效的代码执行而闻名。它支持结构化编程,可以用于编写系统级软件和小型控制程序,同时也适合科学计算。C语言的一个关键特性是它的可移植性,这意味着用C编写的程序可以在不同类型的计算机上运行,只需很少或无需修改。
然而,C语言的语法结构相对较松散,这使得编程者有更大的自由度,但也增加了调试的难度。对于初学者来说,理解和掌握C语言可能需要更多的时间和实践。与更现代的语言相比,C++提供了更严格的类型检查和面向对象的特性,这些特性有助于提高代码的组织性和可维护性,但同时也增加了学习曲线。尽管如此,C++仍然是许多专业软件开发和系统编程的首选语言。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
联邦学习:打破数据孤岛,实现协作式云服务,云计算的未来
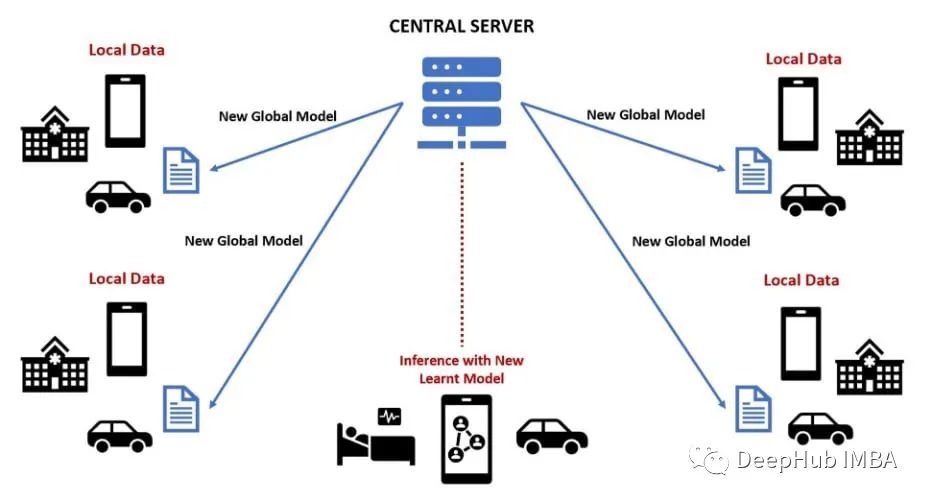
# 1. 联邦学习概览
联邦学习是一种分布式机器学习范式,允许在不共享原始数据的情况下,从多个参与方联合训练机器学习模型。它旨在解决数据隐私和安全问题,同时利用来自不同来源的数据丰富模型。
联邦学习的独特之处在于,它允许参与方在本地训练模型,并仅共享模型更新,而不是原始数据。通过这种方式,数据隐私得到保护,同时仍能利用集体数据的力量来训练更准确和
AttributeError: 'RFECV' object has no attribute 'ranking_'
`AttributeError: 'RFECV' object has no attribute 'ranking_'` 这个错误意味着当你尝试访问名为`'ranking_'`的属性时,`RFECV`对象并不具备这样的属性。RFECV (Recursive Feature Elimination with Cross-Validation) 是一种特征选择工具,在scikit-learn库中用于递归地删除变量并评估模型性能,直到找到最佳的变量组合。
`ranking_` 属性通常是在循环结束后,保存了每次交叉验证过程中特征的重要性排名。如果你试图在循环过程中或尚未完成选择过程时获取这个属性,
C++程序设计解析:变量a,b,c的值变化分析
"谭浩强 C++ ppt - 讨论C++编程中的变量赋值和条件运算符"
在C++编程中,理解变量的赋值和条件运算符是至关重要的。题目给出的程序段展示了如何使用这些概念,以及它们在实际编程中的效果。这段代码如下:
```cpp
int x=10, y=9;
int a, b, c;
a=(--x==y++)?--x:++y;
b=x++;
c=y;
```
首先,我们分析每个变量的赋值过程:
1. `x` 初始化为10,`y` 初始化为9。
2. 在表达式 `a=(--x==y++)?--x:++y` 中,条件运算符 `? :` 被用来根据条件决定赋值给 `a` 的值。首先,`--x` 将 `x` 减1变为9,然后与 `y++` 比较。由于 `x` 现在等于9,且 `y++` 之后 `y` 变为10,所以条件 `--x == y++` 为真。
3. 当条件为真时,条件运算符后面的 `--x` 执行,`x` 再次减1变为8,因此 `a` 被赋值为8。
4. 接下来,`b=x++;` 这一行将 `x` 的当前值(8)赋给 `b`,然后 `x` 自增1变为9。
5. 最后,`c=y;` 将 `y` 的值(10)赋给 `c`。
因此,执行完这段程序后,变量的值是:`x=9`, `y=10`, `a=8`, `b=8`, `c=10`。但题目中给出的最终值有一些错误,应该是 `x=9`, `y=10`, `a=8`, `b=9`, `c=10`。
这段程序展示了C++中的一些关键特性,如前置递减和后置递增运算符(`--x` 和 `x++`),以及条件运算符的用法。前置递减/增加运算符会先改变变量的值,然后返回新的值;而后置递减/增加运算符则先返回当前值,然后才改变变量的值。
C++是建立在C语言基础之上的,保留了C语言的很多特性,如结构化编程、丰富的运算符和高效的代码执行。C++还引入了面向对象编程的概念,如类、对象、封装、继承和多态,以及模板和异常处理等高级特性。然而,这也意味着C++对于初学者来说可能更具挑战性,因为它的语法相对宽松,可能导致不易察觉的错误,尤其是在处理指针和内存管理时。
C语言因为其高效和良好的可移植性,被广泛用于系统级编程和嵌入式系统。C++则在保持这些优点的同时,提供了更高级的抽象和编程模型,适用于开发复杂的软件系统,尤其是游戏引擎、图形用户界面和大型企业应用等领域。