一个建筑物有多层,且每层都测量了多个点的坐标,求出其中心点坐标。建筑的倾斜度是只和建筑最高点有关还是和中心点有关?怎么求?是每层都要求倾斜度还是整个建筑只求一个?
时间: 2024-04-17 22:24:10 浏览: 23
建筑物的倾斜度通常是与整个建筑物有关,而不仅仅与最高点或中心点有关。因此,在计算建筑物的倾斜度时,需要考虑整个建筑物的倾斜情况,而不仅仅是单个点或中心点的坐标。
如果你想求出建筑物的倾斜度,可以使用以下步骤:
1. 首先,对于每一层的测量点坐标,计算出该层的中心点坐标。可以通过计算测量点的平均值得到中心点坐标。
2. 使用中心点坐标来计算每一层的倾斜度。可以使用同样的方法,即使用倾斜仪或水平仪来测量每一层的倾斜角度。
3. 对于整个建筑物的倾斜度,可以将每一层的倾斜度进行综合,例如取平均值或加权平均值。
需要注意的是,在计算建筑物的倾斜度时,还应考虑到建筑物结构、地基等因素的影响。因此,为了获得更准确和可靠的结果,建议咨询专业工程师或使用专业测量设备进行测量和分析。
相关问题
c语言如何封装多层三个点的函数
在C语言中,可以使用嵌套的可变参数列表来封装多层三个点的函数。具体实现方法是,在调用一个封装了三个点的函数时,将可变参数列表作为参数传递给下一层函数。下面是一个示例代码,演示如何封装多层三个点的函数:
```
#include <stdarg.h>
#include <stdio.h>
double average(int num, ...) {
va_list arguments;
double sum = 0;
// 初始化可变参数列表
va_start(arguments, num);
// 读取可变参数列表中的所有参数,并将它们累加起来
for (int i = 0; i < num; i++) {
sum += va_arg(arguments, double);
}
// 结束可变参数列表
va_end(arguments);
// 计算平均值并返回
return sum / num;
}
void print_average(const char* format, int num, ...) {
va_list arguments;
// 初始化可变参数列表
va_start(arguments, num);
// 调用已经封装了三个点的函数,计算平均值
double result = average(num, arguments);
// 输出结果
vprintf(format, arguments);
// 结束可变参数列表
va_end(arguments);
}
void print_averages(int num, ...) {
va_list arguments;
// 初始化可变参数列表
va_start(arguments, num);
// 调用封装了三个点的函数,计算每组数据的平均值并输出
for (int i = 0; i < num; i++) {
int count = va_arg(arguments, int);
const char* format = va_arg(arguments, const char*);
print_average(format, count, arguments);
}
// 结束可变参数列表
va_end(arguments);
}
int main() {
// 调用封装了多层三个点的函数,计算多组数据的平均值并输出
print_averages(2, 3, "Average of three numbers = %f\n", 2.0, 3.0, 4.0, 2, "Average of two numbers = %f\n", 1.0, 2.0);
return 0;
}
```
在上面的代码中,我们定义了一个`print_averages`函数,它接受一个整数`num`和若干个参数。在函数内部,我们首先初始化可变参数列表,然后使用一个循环来遍历每组数据。对于每组数据,我们首先读取参数列表中的两个参数:一个整数`count`表示数据数量,和一个格式化字符串`format`表示输出格式。然后,我们调用`print_average`函数,将可变参数列表传递给它,计算平均值并输出。最后,我们结束可变参数列表。在`main`函数中,我们调用`print_averages`函数,计算多组数据的平均值并输出。
.loc 访问多层索引 依次提取每一个年份对应销售额数据
假设数据集的多层索引是年份(Year)和月份(Month),并且销售额数据存储在 Sales 列中,可以使用以下代码依次提取每一个年份对应的销售额数据:
```
import pandas as pd
# 读取数据集
df = pd.read_csv('sales.csv', index_col=['Year', 'Month'])
# 访问 2018 年的销售额数据
sales_2018 = df.loc[2018]['Sales']
# 访问 2019 年的销售额数据
sales_2019 = df.loc[2019]['Sales']
# 访问 2020 年的销售额数据
sales_2020 = df.loc[2020]['Sales']
```
这里首先使用 `pd.read_csv` 方法读取数据集,并将年份和月份作为多层索引。然后,使用 `.loc` 方法依次访问每一个年份的数据,并提取其中的销售额数据。最终,将每一个年份的销售额数据存储在不同的变量中。
相关推荐
最新推荐
TensorFlow实现MLP多层感知机模型
理论上,一个单一隐藏层的神经网络可以逼近任何连续函数,而增加更多隐藏层则可以进一步提高模型的复杂度和泛化能力。然而,随着层数的增加,可能会遇到过拟合、参数调试和梯度消失等问题。 过拟合是训练过程中常见...
python实现多层感知器MLP(基于双月数据集)
主要为大家详细介绍了python实现多层感知器MLP,基于双月数据集,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
详解Python读取yaml文件多层菜单
主要介绍了Python读取yaml文件多层菜单,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
python读取多层嵌套文件夹中的文件实例
修复这个问题的方法是使用`os.path.isfile()`来检查每个单独的项目,而不仅仅是第一个。 总的来说,读取多层嵌套文件夹的关键在于理解递归的概念。递归函数会不断地对子目录进行同样的操作,直到所有子目录都被遍历...
Android利用Gson解析嵌套多层的Json的简单方法
为了解析这个JSON,我们需要创建一个对应的Java Bean类,如`JsonBean`,并确保其属性与JSON中的键相匹配。这里使用内部类的方式来表示嵌套的JSON对象: ```java public class JsonBean { public String a; public...
图书馆管理系统数据库设计与功能详解
"图书馆管理系统数据库设计.pdf"
图书馆管理系统数据库设计是一项至关重要的任务,它涉及到图书信息、读者信息、图书流通等多个方面。在这个系统中,数据库的设计需要满足各种功能需求,以确保图书馆的日常运营顺畅。
首先,系统的核心是安全性管理。为了保护数据的安全,系统需要设立权限控制,允许管理员通过用户名和密码登录。管理员具有全面的操作权限,包括添加、删除、查询和修改图书信息、读者信息,处理图书的借出、归还、逾期还书和图书注销等事务。而普通读者则只能进行查询操作,查看个人信息和图书信息,但不能进行修改。
读者信息管理模块是另一个关键部分,它包括读者类型设定和读者档案管理。读者类型设定允许管理员定义不同类型的读者,比如学生、教师,设定他们可借阅的册数和续借次数。读者档案管理则存储读者的基本信息,如编号、姓名、性别、联系方式、注册日期、有效期限、违规次数和当前借阅图书的数量。此外,系统还包括了借书证的挂失与恢复功能,以防止丢失后图书的不当借用。
图书管理模块则涉及图书的整个生命周期,从基本信息设置、档案管理到征订、注销和盘点。图书基本信息设置包括了ISBN、书名、版次、类型、作者、出版社、价格、现存量和库存总量等详细信息。图书档案管理记录图书的入库时间,而图书征订用于订购新的图书,需要输入征订编号、ISBN、订购数量和日期。图书注销功能处理不再流通的图书,这些图书的信息会被更新,不再可供借阅。图书查看功能允许用户快速查找特定图书的状态,而图书盘点则是为了定期核对库存,确保数据准确。
图书流通管理模块是系统中最活跃的部分,它处理图书的借出和归还流程,包括借阅、续借、逾期处理等功能。这个模块确保了图书的流通有序,同时通过记录借阅历史,方便读者查询自己的借阅情况和超期还书警告。
图书馆管理系统数据库设计是一个综合性的项目,涵盖了用户认证、信息管理、图书操作和流通跟踪等多个层面,旨在提供高效、安全的图书服务。设计时需要考虑到系统的扩展性、数据的一致性和安全性,以满足不同图书馆的具体需求。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
表锁问题全解析:深度解读,轻松解决
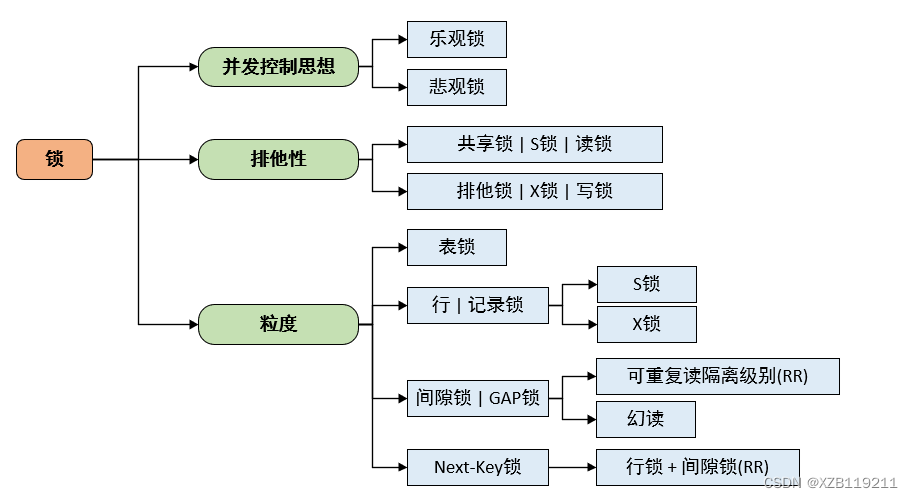
# 1. 表锁基础**
表锁是一种数据库并发控制机制,用于防止多个事务同时修改同一行或表,从而保证数据的一致性和完整性。表锁的工作原理是通过在表或行上设置锁,当一个事务需要访问被锁定的数据时,它必须等待锁被释放。
表锁分为两种类型:行锁和表锁。行锁只锁定被访问的行,而表锁锁定整个表。行锁的粒度更细,可以提高并发性,但开销也更大。表锁的粒度更粗,开销较小,但并发性较低。
表锁还分为共享锁和排他锁。共享锁允许多个事务同时
麻雀搜索算法SSA优化卷积神经网络CNN
麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种生物启发式的优化算法,它模拟了麻雀觅食的行为,用于解决复杂的优化问题,包括在深度学习中调整神经网络参数以提高性能。在卷积神经网络(Convolutional Neural Networks, CNN)中,SSA作为一种全局优化方法,可以应用于网络架构搜索、超参数调优等领域。
在CNN的优化中,SSA通常会:
1. **构建种群**:初始化一组随机的CNN结构或参数作为“麻雀”个体。
2. **评估适应度**:根据每个网络在特定数据集上的性能(如验证集上的精度或损失)来评估其适应度。
3. **觅食行为**:模仿
***物流有限公司仓储配送业务SOP详解
"该文档是***物流有限公司的仓储配送业务SOP管理程序,包含了工作职责、操作流程、各个流程的详细步骤,旨在规范公司的仓储配送管理工作,提高效率和准确性。"
在物流行业中,标准操作程序(SOP)是确保业务流程高效、一致和合规的关键。以下是对文件中涉及的主要知识点的详细解释:
1. **工作职责**:明确各岗位人员的工作职责和责任范围,是确保业务流程顺畅的基础。例如,配送中心主管负责日常业务管理、费用控制、流程监督和改进;发运管理员处理运输调配、计划制定、5S管理;仓管员负责货物的收发存管理、质量控制和5S执行;客户服务员则处理客户指令、运营单据和物流数据管理。
2. **操作流程**:文件详细列出了各项操作流程,包括**入库及出库配送流程**,强调了从接收到发货的完整过程,包括验收、登记、存储、拣选、包装、出库等环节,确保货物的安全和准确性。
3. **仓库装卸作业流程**:详细规定了货物装卸的操作步骤,包括使用设备、安全措施、作业标准,以防止货物损坏并提高作业效率。
4. **货物在途跟踪及异常情况处理流程**:描述了如何监控货物在运输途中的状态,以及遇到异常如延误、丢失或损坏时的应对措施,确保货物安全并及时处理问题。
5. **单据流转及保管流程**:规定了从订单创建到完成的单据处理流程,包括记录、审核、传递和存档,以保持信息的准确性和可追溯性。
6. **存货管理**:涵盖了库存控制策略,如先进先出(FIFO)、定期盘点、库存水平的优化,以避免过度库存或缺货。
7. **仓库标志流程**:明确了仓库内的标识系统,帮助员工快速定位货物,提高作业效率。
8. **仓库5S管理及巡检流程**:5S(整理、整顿、清扫、清洁、素养)是提高仓库环境和工作效率的重要工具,巡检流程则确保了5S的持续实施。
9. **仓库建筑设备设施的维护流程**:强调了设备设施的定期检查、保养和维修,以保证其正常运行,避免因设备故障导致的运营中断。
10. **附件清单**:列出所有相关的附件和表格,便于员工参考和执行。
通过这些详尽的SOP,***物流有限公司能够系统化地管理仓储配送业务,确保服务质量,减少错误,提升客户满意度,并为公司的持续改进提供基础。