shuffle shell
时间: 2024-05-01 22:15:43 浏览: 12
Shuffle Shell是一种用于打乱文本行顺序的命令行工具。它可以随机重新排列输入文件或标准输入中的行,并将结果输出到标准输出。Shuffle Shell可以在Linux、Unix和类似系统上使用。
使用Shuffle Shell非常简单,只需在命令行中输入"shuffle"命令,然后通过管道将输入传递给它。例如,可以使用以下命令将文件中的行进行随机排序:
```
cat file.txt | shuffle
```
Shuffle Shell还支持一些选项,例如可以指定随机种子、设置输出行数限制等。你可以通过运行"shuffle --help"命令来查看更多详细的用法和选项。
相关问题
spark shell 初始化为sqlcontext
Spark shell是一个交互式的命令行工具,可以用来开发Spark应用程序。通过Spark shell,用户可以交互式地探索数据,测试Spark API,并快速地开发和测试Spark应用。
在Spark shell初始化为sqlcontext,意味着在Spark shell中可以使用SQL API进行分析和处理数据。SQLContext是Spark SQL的主要入口点,它可以用来与结构化数据进行交互,并执行SQL查询。
要初始化Spark shell为sqlcontext,可以在shell中输入以下命令:
```
$ spark-shell --packages com.databricks:spark-csv_2.10:1.5.0 --conf spark.sql.shuffle.partitions=8 --conf spark.default.parallelism=480 --driver-memory 1g --executor-memory 2g --executor-cores 2 --num-executors 20 --master yarn --deploy-mode client --queue xxx --name test-spark
```
其中,--packages参数指定导入的包,这里导入的是Databricks提供的spark-csv包,用于处理CSV格式的数据。--conf参数用于设置配置信息,例如我们可以设置spark.sql.shuffle.partitions参数来控制shuffle操作的并行度,从而提高Spark SQL的性能。其他参数则是通用的Spark参数,可以根据具体需求进行设置。
初始化完成后,我们就可以使用Spark SQL来处理数据了。例如,可以使用以下代码读取CSV格式的数据:
```scala
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val df = sqlContext.read.format("com.databricks.spark.csv").option("header", "true").option("inferSchema", "true").load("path/to/csv")
```
通过以上代码,我们使用Spark SQL提供的read方法读取CSV格式的数据,并通过option方法设置读取参数。最后,我们将数据加载到DataFrame中。
总之,Spark shell初始化为sqlcontext,可以让我们使用Spark SQL来处理数据,从而更方便地进行数据分析和管理。
shell脚本方式执行sparksql
Shell脚本可以用来执行SparkSQL,以下是一个示例:
```shell
#!/bin/bash
# 设置Spark相关环境变量
export SPARK_HOME=/path/to/spark
export PATH=$PATH:$SPARK_HOME/bin
# 定义变量
app_name="spark_sql_demo"
master="local[*]"
input_file="/path/to/input_file.csv"
output_dir="/path/to/output_dir"
# 执行SparkSQL脚本
spark-submit \
--class com.example.SparkSQLDemo \
--master $master \
--name $app_name \
--executor-memory 2g \
--driver-memory 2g \
--num-executors 4 \
--executor-cores 2 \
--conf "spark.sql.shuffle.partitions=4" \
--conf "spark.default.parallelism=8" \
--conf "spark.sql.catalogImplementation=hive" \
--conf "spark.eventLog.enabled=true" \
--conf "spark.eventLog.dir=/path/to/event_log_dir" \
/path/to/your/spark_sql_demo.jar \
$input_file \
$output_dir
```
上述脚本首先设置了相应的Spark环境变量。然后,定义了一些变量,如应用程序名称、master节点地址、输入文件路径和输出目录。
最后,使用`spark-submit`命令来执行SparkSQL脚本。在命令中,指定了SparkSQL脚本的入口类、master节点地址、应用程序名称以及其他一些Spark相关的配置参数。最后,指定了要执行的SparkSQL脚本的jar包、输入文件路径和输出目录。
通过运行上述脚本,Spark将会执行指定的SparkSQL脚本并将结果保存到指定的输出目录中。
相关推荐
最新推荐
计算机专业毕业设计范例845篇jsp2118基于Web停车场管理系统的设计与实现_Servlet_MySql演示录像.rar
博主给大家详细整理了计算机毕业设计最新项目,对项目有任何疑问(部署跟文档),都可以问博主哦~ 一、JavaWeb管理系统毕设项目【计算机毕设选题】计算机毕业设计选题,500个热门选题推荐,更多作品展示 计算机毕业设计|PHP毕业设计|JSP毕业程序设计|Android毕业设计|Python设计论文|微信小程序设计
Windows 10 平台 FFmpeg 开发环境搭建 博客资源
【FFmpeg】Windows 10 平台 FFmpeg 开发环境搭建 ④ ( FFmpeg 开发库内容说明 | 创建并配置 FFmpeg 项目 | 拷贝 DLL 动态库到 SysWOW64 目录 )
https://hanshuliang.blog.csdn.net/article/details/139172564
博客资源
一、FFmpeg 开发库
1、FFmpeg 开发库编译
2、FFmpeg 开发库内容说明
二、创建并配置 FFmpeg 项目
1、拷贝 dll 动态库到 C:\Windows\SysWOW64 目录 - 必须操作 特别关注
2、创建 Qt 项目 - C 语言程序
3、配置 FFmpeg 开发库 - C 语言项目
4、创建并配置 FFmpeg 开发库 - C++ 项目
基于 Spring Cloud 、Spring Boot、 OAuth2 的 RBAC 企业快速开发平台
基于 Spring Cloud 、Spring Boot、 OAuth2 的 RBAC 企业快速开发平台, 同时支持微服务架构和单体架构。提供对 Spring Authorization Server 生产级实践,支持多种安全授权模式。提供对常见容器化方案支持 Kubernetes、Rancher2 、Kubesphere、EDAS、SAE 支持
我赚100万的商业模式.pdf
我赚100万的商业模式
Python_编译器学习资源收集.zip
Python_编译器学习资源收集
zigbee-cluster-library-specification
最新的zigbee-cluster-library-specification说明文档。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
MySQL数据库性能提升秘籍:揭秘性能下降幕后真凶及解决策略
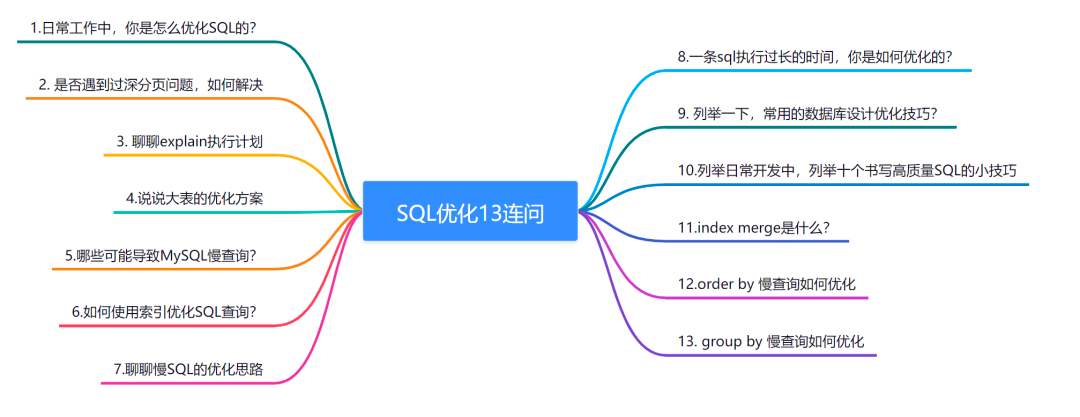
# 1. MySQL数据库性能优化概述**
MySQL数据库性能优化是一项至关重要的任务,可以显著提高应用程序的响应时间和整体用户体验。优化涉及识别和解决影响数据库性能的因素,包括硬件资源瓶颈、软件配置不当和数据库设计缺陷。通过采取适当的优化策略,可以显著提升数据库性能,满足业务需求并提高用户满意度。
# 2. MySQL数据库性能下降的幕后真凶
### 2.1 硬件资源瓶颈
#### 2.1.1 CPU利用率过高
**症状:
如何在unity创建按钮
在 Unity 中创建按钮的步骤如下:
1. 在 Unity 中创建一个 UI Canvas,选择 GameObject -> UI -> Canvas。
2. 在 Canvas 中创建一个按钮,选择 GameObject -> UI -> Button。
3. 在场景视图中调整按钮的位置和大小。
4. 在 Inspector 中设置按钮的文本、颜色、字体等属性。
5. 添加按钮的响应事件,选择按钮,在 Inspector 的 On Click () 中添加相应的方法。
这样就可以创建一个按钮了,你可以在游戏中使用它来触发相应的操作。
JSBSim Reference Manual
JSBSim参考手册,其中包含JSBSim简介,JSBSim配置文件xml的编写语法,编程手册以及一些应用实例等。其中有部分内容还没有写完,估计有生之年很难看到完整版了,但是内容还是很有参考价值的。