如何增加gpu专用内存
时间: 2024-08-17 20:00:59 浏览: 252
增加GPU(Graphics Processing Unit)专用内存,通常称为显存或Video Memory,对于提升图形处理性能至关重要。在一些情况下,如服务器、工作站或者特殊的GPU扩展卡,你可以采取以下几个步骤来增加GPU的显存:
1. 升级硬件:如果你的GPU支持更换显存模块(例如,某些NVIDIA和AMD的独立显卡),你可以考虑购买额外的显存条并安装到相应插槽上。确保新买的显存与原卡兼容且总容量不超过显卡的最大支持。
2. 卡内集成:部分高端GPU可能本身就设计有可扩展的HBM(High Bandwidth Memory)、HMC(Hierarchical Memory Cube)等新型存储技术,这些通常是封闭在GPU内部无法直接升级的。
3. 内存整合:如果GPU支持ECC(Error Correcting Code)内存,你可以选择提供更大容量但默认不支持ECC的普通显存,并用软件设置将它们整合在一起,但这可能会牺牲一部分稳定性。
4. PCIe带宽:对于通过PCIe接口连接的GPU,带宽本身可能限制了可用显存大小。确保你的主板PCIe通道足够强大,能够满足大容量显存的需求。
5. 检查系统限制:检查系统的BIOS设置,确认是否允许调整GPU的显存分配。有些主板会设置固定值,不允许用户自定义。
6. 软件优化:在一些平台上,你可以利用厂商提供的控制面板进行显存管理,比如NVIDIA的NVSMI工具或AMD的Radeon Software,通过软件手段动态调整显存分配策略。
相关问题
如何调整GPU专用内存大喜小
要调整GPU的专用内存大小,可以尝试以下方法:
1. 使用CUDA_VISIBLE_DEVICES环境变量:可以使用CUDA_VISIBLE_DEVICES环境变量来限制可见的GPU设备数量。通过设置该环境变量,您可以指定只使用特定的GPU设备,从而限制了可见的GPU内存大小。
例如,设置CUDA_VISIBLE_DEVICES=0将只使用第一个GPU设备,并相应地调整了可见的GPU内存大小。
2. 使用TensorFlow的GPU配置:如果您使用TensorFlow作为深度学习框架,可以使用tf.config来配置GPU内存的使用。
```python
import tensorflow as tf
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
# 设置仅在需要时申请显存
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e:
print(e)
```
通过设置`tf.config.experimental.set_memory_growth`为True,TensorFlow将仅在需要时申请显存,从而灵活地管理GPU内存。
3. 使用显存分配器:某些深度学习框架(如PyTorch)提供了显存分配器(memory allocator)的选项,您可以通过设置显存分配器来控制GPU内存的使用。
例如,在PyTorch中,可以通过以下方式更改显存分配器:
```python
import torch
torch.cuda.set_allocator(torch.cuda.allocator.PyCudaAllocator)
```
这将使用PyTorch的PyCudaAllocator作为显存分配器,可以灵活地控制GPU内存的使用。
请注意,这些方法可能因深度学习框架和GPU驱动程序的不同而有所不同。建议根据您使用的具体环境和需求,选择最适合您的方法来调整GPU的专用内存大小。
专用gpu和共享gpu内存
专用GPU是一种独立的显卡,它被设计成为一台计算机的独立组件,只能由一个用户或任务使用。与之相反,共享GPU内存是一种共享计算资源的方式,多个用户或任务可以同时使用同一块GPU,但是它们必须共享GPU内存。通常情况下,专用GPU比共享GPU内存更适合需要大量计算资源的任务,因为它们可以提供更高的计算性能和更快的数据处理能力。但是,共享GPU内存可以更有效地利用计算资源,因为它可以同时处理多个任务,从而更好地满足资源共享的需求。
相关推荐
最新推荐
解决tensorflow训练时内存持续增加并占满的问题
3. 如果可能,尝试使用GPU进行训练,因为GPU通常拥有更大的内存,并且更擅长处理大量并行计算。 4. 调整TensorFlow的内存分配策略,例如通过`tf.config.experimental.set_memory_growth`启用内存增长策略,让...
KVM虚拟机GPU透传.docx
"KVM虚拟机GPU透传" KVM虚拟机GPU透传是指在Linux操作系统下,使用KVM虚拟机来实现GPU设备的透传,以便在虚拟机中使用GPU设备。以下是KVM虚拟机GPU透传的详细操作说明。 KVM虚拟机GPU透传的准备工作 在开始KVM...
pytorch 指定gpu训练与多gpu并行训练示例
本文将详细介绍如何在PyTorch中指定单个GPU进行训练以及如何实现多GPU并行训练。 一、指定一个GPU训练 在PyTorch中,有两种方法可以指定使用哪个GPU进行训练: 1. **代码中指定**: 使用 `torch.cuda.set_device...
免费使用阿里天池GPU深度学习.pdf
用户需要注意分配合理的显存给各个计算任务,避免内存溢出,同时利用并行计算提高训练效率。 总的来说,阿里天池GPU深度学习教程是一个极好的资源,它不仅提供了免费的GPU资源,还简化了使用流程,使得初学者也能...
检测tensorflow是否使用gpu进行计算的方式
如果在运行TensorFlow代码后,`nvidia-smi`显示GPU的显存占用增加或者GPU的利用率上升,那就说明TensorFlow正在使用GPU进行计算。 为了确保TensorFlow能正确使用GPU,还需要在系统中正确安装和配置CUDA和cuDNN库,...
ExtJS 2.0 入门教程与开发指南
"EXTJS开发指南,适用于初学者,涵盖Ext组件和核心技术,可用于.Net、Java、PHP等后端开发的前端Ajax框架。教程包括入门、组件结构、控件使用等,基于ExtJS2.0。提供有配套的单用户Blog系统源码以供实践学习。作者还编写了更详细的《ExtJS实用开发指南》,包含控件配置、服务器集成等,面向进阶学习者。"
EXTJS是一个强大的JavaScript库,专门用于构建富客户端的Web应用程序。它以其丰富的组件和直观的API而闻名,能够创建具有桌面应用般用户体验的Web界面。在本文档中,我们将深入探讨EXTJS的核心技术和组件,帮助初学者快速上手。
首先,EXTJS的组件模型是其强大功能的基础。它包括各种各样的控件,如窗口(Window)、面板(Panel)、表格(Grid)、表单(Form)、菜单(Menu)等,这些组件可以灵活组合,构建出复杂的用户界面。通过理解这些组件的属性、方法和事件,开发者可以定制化界面以满足特定需求。
入门EXTJS,你需要了解基本的HTML和JavaScript知识。EXTJS的API文档是学习的重要资源,它详细解释了每个组件的功能和用法。此外,通过实际操作和编写代码,你会更快地掌握EXTJS的精髓。本教程中,作者提供了新手入门指导,包括如何设置开发环境,创建第一个EXTJS应用等。
EXTJS的组件体系结构是基于MVC(Model-View-Controller)模式的,这使得代码组织清晰,易于维护。学习如何构建和组织这些组件,对于理解EXTJS的工作原理至关重要。同时,EXTJS提供了数据绑定机制,可以方便地将视图组件与数据源连接,实现数据的实时更新。
在EXTJS中,控件的使用是关键。例如,表格控件(GridPanel)可以显示大量数据,支持排序、过滤和分页;表单控件(FormPanel)用于用户输入,可以验证数据并发送到服务器。每个控件都有详细的配置选项,通过调整这些选项,可以实现各种自定义效果。
此外,EXTJS与服务器端的集成是另一个重要话题。无论你的后端是.NET、Java还是PHP,EXTJS都能通过Ajax通信进行数据交换。了解如何使用Store和Proxy来处理数据请求和响应,是构建交互式应用的关键。
为了深化EXTJS的学习,你可以参考作者编写的《ExtJS实用开发指南》。这本书更深入地讲解了EXTJS框架,包括控件的详细配置、服务器集成示例以及一个完整应用系统的构建过程,适合已经掌握了EXTJS基础并希望进一步提升技能的开发者。
EXTJS是一个强大的工具,能够帮助开发者构建功能丰富、用户体验优秀的Web应用。通过本文档提供的教程和配套资源,初学者可以逐步掌握EXTJS,从而踏入这个充满可能的世界。在实践中不断学习和探索,你将能驾驭EXTJS,创造出自己的富客户端应用。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
【Java字符串不可变性深度剖析】:影响与应用场景分析
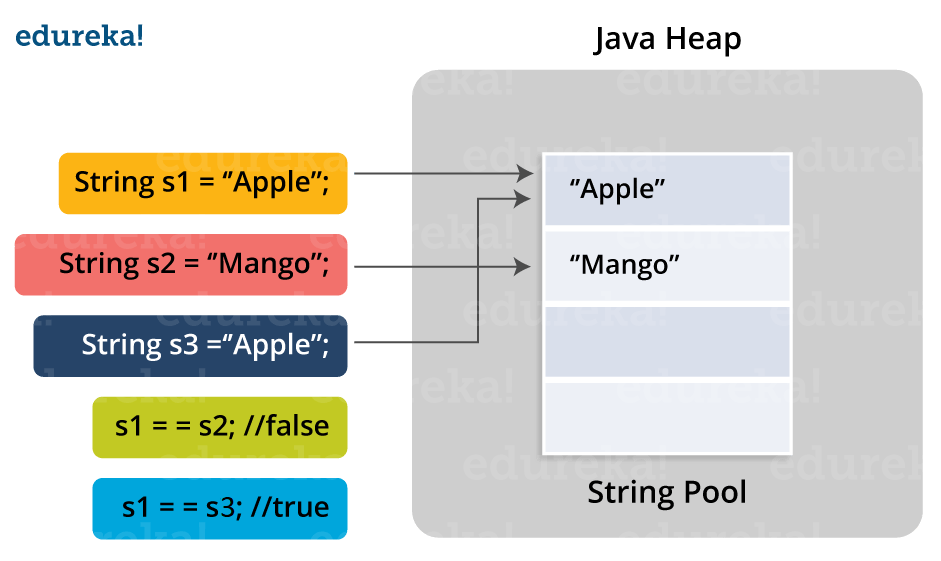
# 1. Java字符串不可变性的基本概念
Java字符串的不可变性指的是一个字符串对象一旦被创建,其内部的字符序列就不能被改变。这意味着任何对字符串的修改操作,如更改字符、拼接、截取等,都不会影响原始字符串对象,而是会生成一个新的字符串对象。不可变性是Java中String类的一个核心特性,它为Java语言带来了多方面的积极影响,比如线程安全、高效的字符串池管理等。然而,这一特性也并
如何让一个字符串等于一个字符数组
要让一个字符串等于一个字符数组,你可以直接赋值,假设我们有一个字符数组`char strArray[]`和一个字符串`char* myString`,你可以这样做:
```c
// 字符数组初始化
char strArray[] = "Hello, World!";
// 将字符串字面量赋给myString
char* myString = strArray;
// 或者如果你想要创建动态分配的字符串并且需要手动添加终止符'\0',
// 可以使用strcpy()函数
size_t len = strlen(strArray); // 获取字符串长度
myString = (char*)
基于TMS320F2812的能量回馈调速系统设计
"基于TMS320F2812的能量回馈调速系统的研发,涉及硬件电路设计、软件设计及Matlab仿真,是理解能量回馈技术的重要资料。"
本文详细探讨了基于TI公司的TMS320F2812 DSP芯片实现的能量回馈调速系统。TMS320F2812是一款高性能的数字信号处理器,适用于实时控制应用,其内置的双事件管理器功能使得双PWM控制得以高效实现,降低了硬件成本并支持复杂控制算法。
在能量回馈的基本原理上,传统的能耗制动方法在变频调速中存在能源浪费、电阻过热以及无法在四象限运行等问题。能量回馈技术则解决了这些问题,它允许变频器在所有四个象限运行,并通过控制整流器和逆变器之间的功率平衡,减小直流储能电容的需求。此外,制动能量被送回电网,提高了系统的整体效率,同时不会对电网质量造成负面影响。
文章首先介绍了能量回馈调速系统的硬件电路设计。主电路采用了两电平电压型双PWM变换器架构,包含网侧电抗器、PWM整流器、直流环节和PWM逆变器。PWM整流器在电机减速时将电机产生的机械能转化为电能,并通过逆变器将其反馈到电网。直流母线电压检测、电流检测、同步电路和温度检测电路等辅助电路确保了系统稳定运行和安全。
接下来,文章阐述了系统的控制策略和软件设计。通过DSP芯片,可以执行实时的控制算法,实现精确的电压和电流控制,确保能量有效回馈。软件设计包括了对电机状态的监控、PWM信号的生成以及各种保护机制的编程。
最后,作者进行了Matlab仿真实验,通过仿真波形验证了设计的有效性。实验结果表明,基于TMS320F2812的系统能够实现能量回馈,且动态性能良好。尽管国际上已有类似的四象限运行变频器和再生装置,但考虑到价格和电网适应性,本设计提供了更经济、更适合中国国情的解决方案。
这篇文章为读者提供了一个深入理解能量回馈技术以及如何利用TMS320F2812 DSP实现这一技术的实例,对于从事相关领域的工程师和技术人员来说,是一份有价值的参考资料。