Python中improve
时间: 2024-05-13 13:11:32 浏览: 52
在Python中,improve是一个高阶函数,它的作用是接受一个函数作为参数,并返回一个新的函数。这个新函数可以在调用原函数之前或之后执行一些额外的代码。improve可以用来装饰函数,增强其功能。使用improve可以简化代码,提高代码的可读性和可维护性。
例如,我们可以使用improve函数来实现函数的日志记录:
```
def log(func):
def wrapper(*args, **kwargs):
print("调用函数:", func.__name__)
return func(*args, **kwargs)
return wrapper
@log
def add(a, b):
return a + b
result = add(1, 2)
print(result)
```
在这个例子中,我们定义了一个log函数,它接受一个函数作为参数,并返回一个新的函数wrapper。这个wrapper函数在调用原函数之前打印一条日志,然后调用原函数,最后返回原函数的返回值。
我们使用@log语法糖来装饰add函数,这样每次调用add函数时都会自动执行log函数,增强了add函数的功能。
相关问题
bagging python
Bagging (Bootstrap Aggregating) is a machine learning ensemble technique that combines multiple models to improve prediction accuracy. In Python, you can use the scikit-learn library to implement bagging.
To perform bagging in Python, you can follow these steps:
1. Import the necessary libraries:
```python
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
```
2. Create an instance of the base model (e.g., Decision Tree):
```python
base_model = DecisionTreeClassifier()
```
3. Create an instance of the BaggingClassifier and specify the number of base models (n_estimators) and other parameters:
```python
bagging_model = BaggingClassifier(base_model, n_estimators=10, max_samples=0.5, max_features=0.5)
```
Here, `n_estimators` represents the number of base models to use, `max_samples` specifies the fraction of samples to draw from the training set for each base model, and `max_features` represents the fraction of features to consider for each base model.
4. Fit the bagging model to your training data:
```python
bagging_model.fit(X_train, y_train)
```
Here, `X_train` represents the training features and `y_train` represents the corresponding labels.
5. Use the bagging model to make predictions:
```python
y_pred = bagging_model.predict(X_test)
```
Here, `X_test` represents the test features, and `y_pred` will contain the predicted labels for the test data.
This is a basic example of how to implement bagging in Python using scikit-learn. Keep in mind that you can also use bagging with other types of models, not just decision trees.
python scripting for klayout
Python scripting for KLayout is a powerful tool that allows you to automate tasks and customize the functionality of KLayout, which is a popular open-source layout viewer and editor for integrated circuit designs. With Python scripting, you can manipulate layouts, extract information, perform analysis, and generate reports.
To get started with Python scripting for KLayout, you need to have KLayout installed on your system. Once installed, you can use the Python API provided by KLayout to interact with the software.
Here are some key points about Python scripting for KLayout:
1. Accessing Layout Data: You can use Python to load layout files, access layers, geometries, properties, and manipulate them as needed. This allows you to automate repetitive tasks or perform complex operations on layouts.
2. Modifying Layouts: Python scripting enables you to modify layouts by adding or removing geometries, changing properties, merging or splitting layers, and performing various transformations.
3. Design Rule Checking (DRC): You can use Python scripting to perform DRC checks on layouts. This involves writing scripts that define design rules and check for violations, helping you ensure the design meets the required specifications.
4. Customizing User Interface: Python scripting allows you to customize the KLayout user interface by adding custom menus, toolbars, dialogs, and shortcuts. This can enhance your workflow and make specific functionalities easily accessible.
5. Scripting Automation: With Python scripting, you can automate repetitive tasks by writing scripts that perform a series of actions in KLayout. This can save time and improve productivity.
相关推荐
最新推荐
028 酒店管理ssm.zip
该毕业设计将深入探讨如何通过Java语言构建一个完整且高效的《028 酒店管理ssm》。毕业设计的架构涵盖了从基础框架搭建到关键功能实现的每一个环节,并采用了模块化设计,使整个系统易于理解、扩展和维护。
无论是数据处理、用户交互还是后台管理,我们都为您提供了详细的代码示例和设计文档。
这个毕业设计的独特之处在于其高度的实用性和灵活性。
我们提供了全面的资源包,帮助您快速入门,并支持您在此基础上进行个性化的功能扩展。
无论您是正在寻找灵感的学生,还是需要现成解决方案的开发者,下载该资源将助您事半功倍。
大学生创业计划书(46)-两份资料.doc
大学生创业计划书(46)-两份资料.doc
试验揭示电磁兼容技术:电晕放电与火花效应对比
电磁兼容技术是一项重要的工程领域,旨在确保电子和电气设备在各种电磁环境下能够正常运行,同时避免对其他设备造成干扰或损害。本文将通过一个实验来探讨这一主题。
实验中的关键点包括两个具有不同曲率的电极,它们之间存在一定的间隙。当施加电压逐渐升高时,电极尖端附近的场强增大,会首先经历电晕放电现象。电晕放电是电流通过气体介质时产生的放电过程,通常在高电场强度下发生。接着,如果电极曲率较小,场强不足以引发电晕放电,电极直接过渡到火花放电和弧光放电阶段。这两种放电形式的区别反映了电极形状和场强对电磁干扰行为的影响。
电磁兼容原理涉及电磁干扰源的控制、传播途径的管理和接收设备的保护。它涉及到电磁干扰的来源分析(如无线电频率干扰、电源噪声等)、设备的电磁敏感性评估以及相应的防护措施,如滤波器、屏蔽和接地等。此外,还涵盖了电磁兼容测试方法,如传导骚扰测试、辐射骚扰测试等,以验证设备在实际环境中的兼容性。
文章列举了电磁能广泛应用于多个领域的例子,包括通信、广播电视、家用电器、生物医学、工业和农业应用、电磁检测、雷达、军事应用以及射电天文学。这些应用不仅推动科技进步,但也带来电磁辐射问题,可能导致信号干扰、设备故障、安全风险和人体健康影响。
针对电磁辐射的危害,文章强调了电磁干扰的严重性,尤其是在人口密集和电磁设备密集的区域。为了降低这些影响,需要遵循严格的电磁兼容设计规范,并采取有效的抗干扰策略。例如,B1轰炸机的研发过程中,就面临了电子设备间的电磁干扰挑战,这凸显了在现代复杂系统中电磁兼容技术的重要性。
电磁兼容技术的研究和实践对于确保电子设备的可靠性和安全性至关重要,它涉及到理论基础、实验验证、标准制定和实际应用等多个层面。理解和掌握这一技术,对于电子工程师、系统设计师和相关行业从业者来说,是提高产品质量和用户满意度的关键。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
超参数调优实战:解锁机器学习模型性能提升的秘诀
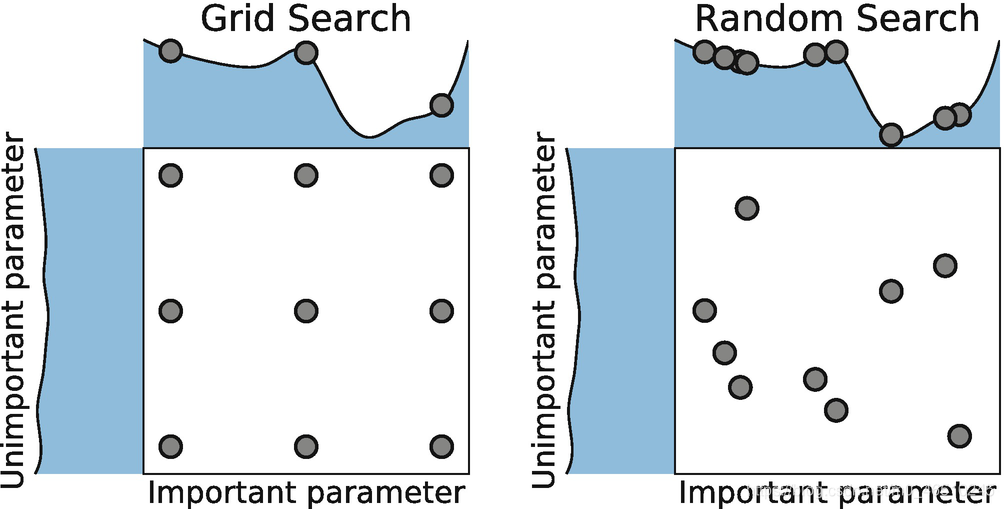
# 1. 超参数调优简介**
超参数调优是机器学习模型训练过程中至关重要的一步,它可以显著提升模型性能。超参数是模型训练过程中不可学习的参数,需要手动设置。它们
kali怎么修改密码
在Kali Linux系统中,修改用户账户密码有几种常见方法,这里以命令行方式为例:
1. **通过终端修改**:
如果你想修改当前用户的密码,可以在终端输入以下命令:
```sh
sudo passwd [username]
```
其中 `[username]` 替换为你想要修改密码的用户名。按照提示,你会被要求确认新密码两次。
2. **图形化工具**(对于LXDE或XFCE等轻量级桌面环境):
- 右击桌面左上角任务栏,选择 "System Settings" 或 "Preferences",然后找到 "User Accounts" -> "Lo
电磁兼容技术:线路反射骚扰与电磁干扰解析
"线路上的反射骚扰-电磁兼容技术"
在电磁兼容领域,线路上的反射骚扰是一个关键问题,它涉及到信号传输的效率和系统稳定性。当线路中的负载阻抗与传输线的特性阻抗不匹配时,就会发生反射现象。反射系数是衡量这种不匹配程度的参数,它是由负载阻抗ZL与传输线特性阻抗Z0的比值决定的。如果反射系数不为零,那么入射到负载的信号会部分反射回传输线,与入射波形成干涉,导致信号质量下降和潜在的干扰。
电磁兼容(EMC)是指设备或系统在其电磁环境中能够正常工作,并且不会对其环境中的其他设备产生不可接受的电磁干扰的能力。EMC技术包括理解和控制电磁干扰的来源,以及设计出能抵御这些干扰的设备。邹澎的《电磁兼容原理、技术和应用》一书详细介绍了这一领域的各个方面,由清华大学出版社出版,主讲人为马力。
书中从第一章绪论开始,讲述了电磁能的广泛应用,涉及通信、广播电视、家用电器、生物医学等多个领域,强调了电磁干扰的问题及其对现代社会的影响。随着电磁能量的逐年增加,电磁兼容问题变得日益重要。电磁辐射的危害不仅干扰信号接收,还可能导致电子设备故障、安全隐患,甚至影响人体健康。
第二章至第十章分别深入探讨了电磁干扰、电磁敏感性、电磁兼容测量、抗干扰技术、电磁兼容设计、通信系统和计算机系统的电磁兼容、雷电及防雷技术。这些章节详细阐述了如何通过各种方法来管理和减少电磁干扰,包括设计优化、滤波、屏蔽、接地等措施,以确保设备之间的互不干扰。
例如,书中可能会提到,对于线路上的反射骚扰,可以通过使用阻抗匹配网络来解决,如串联或并联的匹配元件,以使负载阻抗与传输线特性阻抗相等,从而减少反射。同时,良好的布线设计和电缆选择也是降低反射骚扰的重要手段。
电磁兼容技术是现代电子系统设计中不可或缺的一部分,它涵盖了从理论研究到实际应用的广泛知识,对于确保设备的稳定运行和整个电磁环境的和谐至关重要。理解并掌握这些知识点对于电子工程师和相关专业人士来说至关重要。
"互动学习:行动中的多样性与论文攻读经历"
多样性她- 事实上SCI NCES你的时间表ECOLEDO C Tora SC和NCESPOUR l’Ingén学习互动,互动学习以行动为中心的强化学习学会互动,互动学习,以行动为中心的强化学习计算机科学博士论文于2021年9月28日在Villeneuve d'Asq公开支持马修·瑟林评审团主席法布里斯·勒菲弗尔阿维尼翁大学教授论文指导奥利维尔·皮耶昆谷歌研究教授:智囊团论文联合主任菲利普·普雷教授,大学。里尔/CRISTAL/因里亚报告员奥利维耶·西格德索邦大学报告员卢多维奇·德诺耶教授,Facebook /索邦大学审查员越南圣迈IMT Atlantic高级讲师邀请弗洛里安·斯特鲁布博士,Deepmind对于那些及时看到自己错误的人...3谢谢你首先,我要感谢我的两位博士生导师Olivier和Philippe。奥利维尔,"站在巨人的肩膀上"这句话对你来说完全有意义了。从科学上讲,你知道在这篇论文的(许多)错误中,你是我可以依
揭秘超参数调优:掌握机器学习模型调优的艺术,性能提升50%!

# 1. 机器学习模型调优概述
机器学习模型调优是一个至关重要的过程,旨在提升模型的性能和泛化能力。通过优化模型的超参数,我们可以显著提高模型在实际应用中的表现。本章将概述机器学习模型调优的概念,包括其重要性、调优的目标以及调优过程中涉及的关键步骤。
# 2. 超参数调优的基础
### 2.1 超参数的概念和作用
超参数是机器学习模型训练过程中,需要手动设置的模型参数。与模型参数不同,超参数不会随着训练过
java QueryWrapper 小于 和 大于等于
Java的QueryWrapper类是MyBatis-Plus中的一个类,用于构建SQL查询条件。在QueryWrapper类中,小于和大于等于的操作符可以通过使用特定的方法来实现。
要使用QueryWrapper类中的小于和大于等于操作符,可以使用以下方法之一:
1. 使用小于操作符:可以使用QueryWrapper类的lt方法来构建小于条件。例如,可以使用以下代码构建一个查询条件,查找年龄小于30岁的用户:
```java
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.lt("age", 30);
List<U