如果dataframe['critical_temp']的某一行的值为0,就返回0所在的行。帮我用python生成代码
时间: 2024-06-10 16:07:48 浏览: 14
当然,这是一个关于数据处理的问题,我可以为您提供一些代码片段来实现这个功能:
```python
import pandas as pd
# 创建一个 DataFrame
df = pd.DataFrame({
'name': ['John', 'Jack', 'Mary', 'Emily'],
'age': [22, 19, 25, 21],
'critical_temp': [0, 10, 15, 0]
})
# 使用 loc 方法定位 critical_temp 的值为 0 的行
result = df.loc[df['critical_temp'] == 0]
# 输出结果
print(result)
```
这段代码可以输出 DataFrame 中符合条件的所有行,如果您只需要返回第一行或某一特定行,可以适当修改其中的代码。希望能对您有所帮助!
相关问题
python怎么删除DataFrame中某列值为0对应行
可以使用 Pandas 库中的 drop() 函数来删除 DataFrame 中某列值为0对应的行。具体方法如下:
假设要删除 DataFrame 中名为 column_name 的列中值为0的行,可以按如下方式操作:
```python
import pandas as pd
# 创建示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3, 4], 'B': [0, 5, 6, 0], 'C': [7, 0, 9, 10]})
# 输出原始 DataFrame
print("原始 DataFrame:")
print(df)
# 删除列中值为0的行
df = df.drop(df[df["column_name"] == 0].index)
# 输出删除后的 DataFrame
print("删除后的 DataFrame:")
print(df)
```
在上面的代码中,首先创建了一个示例的 DataFrame,然后使用 drop() 函数删除了列中值为0的行。其中,代码 `df[df["column_name"] == 0]` 用于选取列中值为0的行,再使用 drop() 函数删除这些行。
需要注意的是,代码中的 "column_name" 需要替换为实际的列名。
帮我写一段python代码获取dataframe某一列最后一个值
当然可以。以下是一段示例代码,仅供参考:
```python
import pandas as pd
# 假设我们有一个名为 df 的 DataFrame,包含了一列名为 'column_name' 的数据
df = pd.DataFrame({'column_name': [1, 2, 3, 4, 5]})
# 通过 iloc 方法获取最后一行数据,再通过 loc 方法获取对应的 'column_name' 列数据
last_value = df.iloc[-1].loc['column_name']
print(last_value)
```
这段代码可以获取 DataFrame 中 'column_name' 列的最后一个值,并将其输出到控制台。其中,我们先通过 iloc 方法获取最后一行数据,再通过 loc 方法获取对应的 'column_name' 列数据。
相关推荐
最新推荐
python实现在pandas.DataFrame添加一行
当使用`loc`为不存在的行标签赋值时,`pandas`会自动在DataFrame中插入新的一行,并用给定的行标签和数据填充。因此,`df.loc[i] = ...`会在`df`的第`i`行插入数据。 4. **打印DataFrame**: 为了查看添加数据后...
对Python中DataFrame按照行遍历的方法
在提供的代码片段中,作者使用了第四个方法,即通过`.loc`访问器按照索引遍历DataFrame的每一行。这在需要获取特定行的列值时非常有用,特别是在进行数据预处理或模型训练时,需要根据行索引提取数据。 需要注意的...
python 使用pandas的dataframe一维数组和二维数组分别按行写入csv或excel
在这个例子中,我们使用列表推导式`[[r[i] for r in dat] for i in range(len(cr))]`将二维数组转换为一个列表的列表,然后用这个新格式的列表创建DataFrame,并定义了列名。最后,同样使用`to_csv`和`to_excel`方法...
Python中实现一行拆多行和多行并一行的示例代码
在Python编程中,有时我们需要处理数据时,可能会遇到一行数据需要拆分为多行,或者多行数据需要合并为一行的情况。本文将详细讲解如何在Python中实现这两种操作,特别是使用Pandas库进行处理。 首先,我们来看如何...
使用Python向DataFrame中指定位置添加一列或多列的方法
在Python的数据分析领域,pandas库的DataFrame对象是处理表格数据的核心工具。向DataFrame中添加新列是一项常见的操作,尤其在数据预处理和特征工程中。这篇文章将详细讲解如何在DataFrame中指定位置添加一列或多列...
贵州煤矿矿井水分类与处理策略:悬浮物、酸性与非酸性
贵州煤矿区的矿井水水质具有鲜明的特点,主要分为含悬浮物矿井水、酸性含铁锰矿井水和非酸性含铁锰矿井水三类。这些分类基于矿井水的水质特性,如悬浮物含量、酸碱度和铁锰离子浓度等。
含悬浮物矿井水是贵州普遍存在的,主要来源于煤粉和岩粉在开采过程中产生的沉淀。经过井下水仓的自然沉淀,大部分悬浮物会被去除,地面抽上来的水悬浮物浓度较低,但依然可能存在50微米以下的细小颗粒。处理这类水通常采用混凝沉淀加过滤工艺,可以有效去除悬浮物,保证水质。
酸性含铁锰矿井水则表现出较高的铁锰含量,这对水质处理提出了特殊要求。针对这种情况,建议采用中和处理结合混凝沉淀和过滤的方式,使用高锰酸钾溶液(浓度5%)浸泡过的锰砂作为滤料,这样可以减少矿井水处理站的启动时间,并且有助于进一步净化水质。
非酸性含铁锰矿井水的处理相对较简单,通常采用混凝沉淀和锰砂过滤的组合工艺,能够有效地去除铁锰离子,保持水质稳定。
总结来说,矿井水的水质特点决定了其处理工艺的选择,对于贵州地区而言,针对性地选择合适的处理方案至关重要,既能确保矿井水达到排放标准,又能有效降低对环境的负面影响。这方面的研究和实践对于提升矿井水资源利用效率,实现绿色开采具有重要的现实意义。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
人工智能透明度革命:如何构建可解释的AI系统
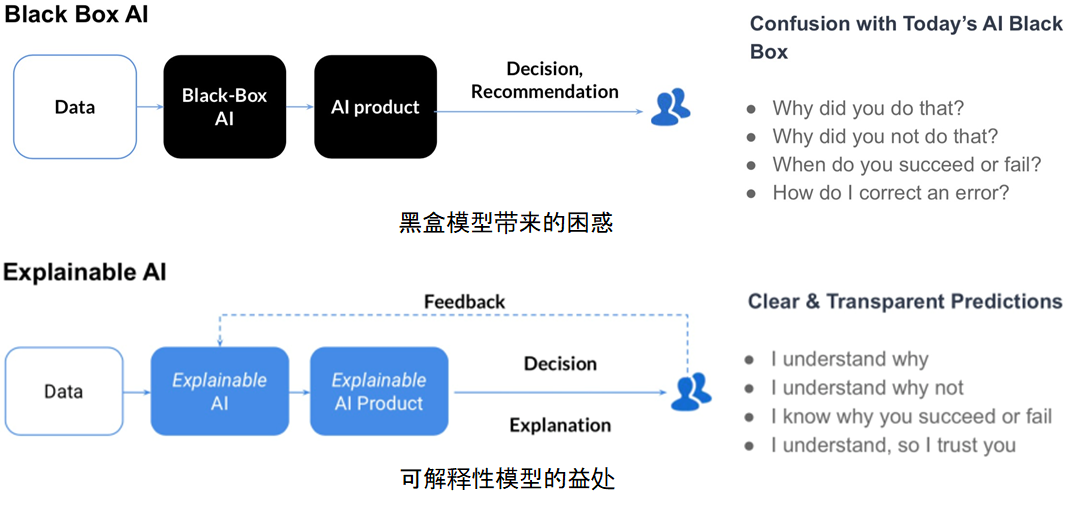
# 1. 人工智能透明度的重要性
随着人工智能(AI)技术在多个领域的广泛应用,AI系统的决策过程和结果的透明度变得至关重要。透明度不仅有助于建立用户信任,还是解决潜在偏见、提升公平性和可解释性的基石。在本章中,我们将探讨透明度对于AI系统的重要性,并分析为什么它对于建立社会对AI技术的信任至关重要。
## 1.1 AI透明度的社会影响
AI透明度指的是能够让用户了解
mig ip核打不开
MIG (Model Interchange for Graphics) 是一种用于图形处理器(GPU)硬件设计的模型交换格式,主要用于描述GPU架构。如果遇到"mig ip核打不开"的问题,可能是以下几个原因:
1. **权限不足**:检查文件路径是否有足够的权限访问该MIG IP核文件。
2. **软件兼容性**:确认使用的工具是否支持当前的MIG版本,旧版工具可能无法打开新版本的IP核。
3. **环境配置**:确保所有依赖的库和开发环境变量已正确设置,尤其是与MIG相关的SDK和编译器。
4. **错误的文件**:确认MIG IP核文件本身没有损坏或者不是针对您的开发平台设计的。
醛固酮增多症肾上腺静脉采样对比:ACTH后LR-CAV的最优评估
本文研究关注于原发性醛固酮增多症(PA)患者的肾上腺静脉采样技术,这是一种在临床诊断中用于评估高血压和肾上腺功能异常的重要手段。研究的目的是确定在进行侧斜度评估前,哪种方法能够提供最精确的诊断信息,以便早期识别单侧PA。
研究采用了回顾性设计,纳入了64例连续的PA患者。研究团队通过将导管置入总干静脉(CTV),并在促肾上腺皮质激素(ACTH)刺激前后的不同时间点进行血液采样。主要评估的指标包括横向比例(LR,即高值侧醛固酮/皮质醇比率与低值侧的比率)、对侧比率(CR,低值侧的ACR与下腔静脉比率的ACR),以及血浆醛固酮浓度(PAC)。
结果显示,ACTH刺激后,LR-CAV(来自中肾上腺静脉的比率)对于单侧肾上腺病变的检测率最高,达到93.3%(14/15),具有良好的灵敏度(0.93)和特异性(0.84),当切点设为2.5时。CR-POST-ACTH的Area Under the Curve(Az值)也表现出较高的性能,检出率为86.7%(13/14),其灵敏度达到0.98,特异性在0.88(当截止值为0.8时)。
这些发现表明,CR在ACTH刺激后和LR-CAV在ACTH刺激后的评估方法对PA的侧向评估具有高度准确性,可以作为临床决策的重要依据。对于原发性醛固酮增多症的患者,选择合适的肾上腺静脉采样技术不仅可以帮助医生更准确地定位病灶,还能提高治疗的针对性和患者预后。
该研究发表在《开放放射学杂志》上,强调了在诊断PA时,尤其是在决定是否需要进行进一步的手术干预前,合理运用这些评估方法的重要性。它为临床实践提供了实用的指导,特别是在处理可能涉及肾上腺功能异常的复杂病例时。