(1) 任何两个b都不相邻的由a、b、c组成的串的正则表达式
时间: 2023-05-26 21:05:34 浏览: 98
a*(b(a|c)*b)*a*
解释:
- a*:任意数量的a
- (b(a|c)*b)*:0个或多个“b后跟0个或多个a或c,再跟一个b”的组合
- a*:任意数量的a
可以通过以下几个步骤来确认这个正则表达式的正确性:
1. 是否包含了a、b、c这三个字符?是的,因为它们都在正则表达式中出现了。
2. 是否没有连续两个b?是的,因为在正则表达式中b后面必须跟着一个a或c,才能再跟一个b。
3. 是否包含所有由a、b、c组成的字符串?是的,因为a*和a*中间夹着的就是“(b(a|c)*b)*”,它可以匹配所有由a、b、c组成、且不包含连续两个b的字符串。
相关问题
vBA 用正则表达式分列
根据提供的两个VBA代码,可以看出这两个代码都是使用正则表达式来处理Excel中的数据。第一个代码是用来提取数字运算符的,第二个代码是用来提取品名和型号的。如果你想要使用正则表达式来分列,可以参考以下步骤:
1.首先,你需要打开Excel文件并按下Alt+F11打开VBA编辑器。
2.在VBA编辑器中,你需要插入一个新的模块。可以通过点击“插入”菜单,然后选择“模块”来完成这个操作。
3.在新的模块中,你需要编写一个新的VBA代码。这个代码需要使用正则表达式来分列。以下是一个简单的例子:
```VBA
Sub SplitColumns()
Dim regex As Object
Set regex = CreateObject("VBScript.RegExp")
regex.Pattern = "(\d+)\s+(\w+)"
Dim cell As Range
For Each cell In Selection
If regex.Test(cell.Value) Then
Dim matches As Object
Set matches = regex.Execute(cell.Value)
cell.Offset(0, 1).Value = matches(0).SubMatches(0)
cell.Offset(0, 2).Value = matches(0).SubMatches(1)
End If
Next
End Sub
```
4.在这个代码中,我们使用了VBScript.RegExp对象来创建一个正则表达式对象。然后,我们设置了正则表达式的模式,这个模式可以匹配一个数字和一个单词。接下来,我们遍历了选定的单元格,并对每个单元格进行了测试。如果单元格的值与正则表达式匹配,我们就使用Execute方法来获取匹配项。最后,我们将匹配项的子匹配项分别放入单元格的相邻列中。
5.最后,你只需要在Excel中选择你想要分列的单元格,然后运行这个VBA代码即可。
2. 检查word文档的连续重复字,例如“用户的的资料”或“需要需要用户输入”之类的情况.(使用两种方法,其中一种为正则表达式)
方法一:使用Python的正则表达式模块re来检查重复字。
```python
import re
def check_duplicate_words(file_path):
# 读取Word文档内容
with open(file_path, 'rb') as f:
content = f.read()
# 将二进制内容转换为字符串
content = content.decode('utf-8', 'ignore')
# 使用正则表达式检查重复字
pattern = re.compile(r'\b(\w+)\s+\1\b')
duplicates = pattern.findall(content)
return duplicates
```
在上述代码中,我们首先打开Word文档文件,并读取其中的内容。然后,我们将二进制内容转换为字符串,并使用正则表达式`\b(\w+)\s+\1\b`来检查重复字。这个正则表达式的意思是:匹配两个相同的单词,这两个单词之间可能有一个或多个空格。如果检查到了重复字,则将其保存在一个列表中并返回。
使用方法如下:
```python
duplicates = check_duplicate_words('example.docx')
if duplicates:
print('文档中存在重复字:', duplicates)
else:
print('文档中不存在重复字')
```
方法二:使用Python的字符串操作来检查重复字。
```python
def check_duplicate_words(file_path):
# 读取Word文档内容
with open(file_path, 'rb') as f:
content = f.read()
# 将二进制内容转换为字符串
content = content.decode('utf-8', 'ignore')
# 使用字符串操作检查重复字
duplicates = []
words = content.split()
for i in range(len(words) - 1):
if words[i] == words[i + 1]:
duplicates.append(words[i])
return duplicates
```
在上述代码中,我们先使用与方法一相同的方式读取文档内容并转换为字符串。然后,我们使用字符串操作将文档中的所有单词分割出来,并逐个比较相邻的两个单词是否相同。如果相同,则将其保存在一个列表中并返回。
使用方法与方法一相同。
相关推荐
最新推荐
Python_ChatGLM3 series Open Bilingual Chat LLMs 开源双语对话语言模型.zip
Python_ChatGLM3 series Open Bilingual Chat LLMs 开源双语对话语言模型
附件1:1名男大学生的一日食谱.xlsx
附件1:1名男大学生的一日食谱.xlsx
用“假定成功”思路做爆品.pdf
用“假定成功”思路做爆品
STC89C51单片机读取DS18B20的64位序列码并显示在1602液晶上KEIL工程文件+开发板硬件原理图.zip
STC89C51单片机读取DS18B20的64位序列码并显示在1602液晶上KEIL工程文件+开发板硬件原理图
/*读取DS18B20的64位序列码并显示在1602液晶上,如果读取正确结果,则在
液晶第一行显示DS18B20 OK,第二行显示序列码,如果读取失败,则在液晶上
显示DS18B20 ERR0R PLEASE CHECK ,用户可通过更改18B20接口自己外接。 */
#include <reg51.h>
#include <intrins.h>
#define uchar unsigned char
#define uint unsigned int
sbit DQ = P2^2; //定义DS18B20端口DQ
sbit BEEP=P2^3 ; //蜂鸣器驱动线
bit presence ;
sbit LCD_RS = P3^5;
sbit LCD_RW = P3^6;
sbit LCD_EN = P3^4;
uchar code cdis1[ ] = {" DS18B20 OK "};
uchar code c
实验五 进程间通信.docx
实验五 进程间通信.docx
zigbee-cluster-library-specification
最新的zigbee-cluster-library-specification说明文档。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
MySQL数据库性能提升秘籍:揭秘性能下降幕后真凶及解决策略
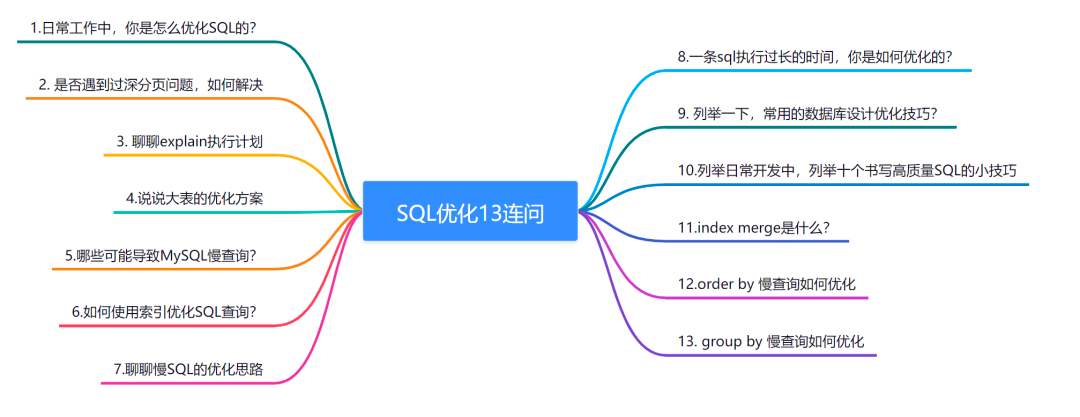
# 1. MySQL数据库性能优化概述**
MySQL数据库性能优化是一项至关重要的任务,可以显著提高应用程序的响应时间和整体用户体验。优化涉及识别和解决影响数据库性能的因素,包括硬件资源瓶颈、软件配置不当和数据库设计缺陷。通过采取适当的优化策略,可以显著提升数据库性能,满足业务需求并提高用户满意度。
# 2. MySQL数据库性能下降的幕后真凶
### 2.1 硬件资源瓶颈
#### 2.1.1 CPU利用率过高
**症状:
如何在unity创建按钮
在 Unity 中创建按钮的步骤如下:
1. 在 Unity 中创建一个 UI Canvas,选择 GameObject -> UI -> Canvas。
2. 在 Canvas 中创建一个按钮,选择 GameObject -> UI -> Button。
3. 在场景视图中调整按钮的位置和大小。
4. 在 Inspector 中设置按钮的文本、颜色、字体等属性。
5. 添加按钮的响应事件,选择按钮,在 Inspector 的 On Click () 中添加相应的方法。
这样就可以创建一个按钮了,你可以在游戏中使用它来触发相应的操作。
JSBSim Reference Manual
JSBSim参考手册,其中包含JSBSim简介,JSBSim配置文件xml的编写语法,编程手册以及一些应用实例等。其中有部分内容还没有写完,估计有生之年很难看到完整版了,但是内容还是很有参考价值的。