hash join 和hash军hash join outer
时间: 2023-07-21 16:48:31 浏览: 70
Hash Join是一种常见的关系型数据库连接操作,它使用哈希表来处理连接操作。具体来说,Hash Join将连接操作拆分为两个步骤:首先,将要连接的两个表中的一个表按照连接键进行哈希分组,然后将另一个表中的记录与哈希分组后的结果进行匹配,最终得到连接的结果。
而Hash Join Outer(也称为Hash Join Full Outer)是Hash Join的一种扩展形式,它可以处理左外连接、右外连接和全外连接。具体来说,Hash Join Outer将连接操作拆分为三个步骤:首先,将左表和右表分别按照连接键进行哈希分组;然后,将左表和右表中的记录与哈希分组后的结果进行匹配,并将匹配成功的结果输出;最后,将左表和右表中未匹配成功的记录输出,同时输出对应的空值。
总的来说,Hash Join和Hash Join Outer都是常见的关系型数据库连接操作,它们可以有效地处理大规模数据集的连接操作,提高查询效率。
相关问题
Oracle的执行计划的hash join和hash join outer 什么情况下会执行
在Oracle数据库中,Hash Join和Hash Join Outer的执行取决于许多因素,包括表大小、连接键的选择、可用内存大小等等。
通常情况下,如果要连接的表很小,那么Oracle可能会选择使用Nested Loop Join(嵌套循环连接)或Sort Merge Join(排序合并连接)等其他连接算法。但是,如果要连接的表非常大,而且内存资源充足,那么Oracle就可能会选择使用Hash Join来处理连接操作。
具体来说,如果Oracle认为Hash Join的执行代价比其他连接算法更低,那么它就会选择Hash Join。而对于Hash Join Outer,则是在处理左外连接、右外连接和全外连接时使用的,如果需要进行这些连接操作,Oracle就会选择Hash Join Outer来执行。
需要注意的是,虽然Hash Join和Hash Join Outer可以提高连接操作的效率,但是它们也需要消耗大量的内存资源,因此在实际使用中需要根据具体情况进行权衡和优化。
hashjoin 源码
hashjoin 是一种常用的关系型数据库的查询算法,用于将两个表中共同的列进行匹配并连接起来。具体实现可以参考 PostgreSQL 数据库中的代码实现。
在 PostgreSQL 中,hashjoin 的实现主要包括三个部分:构建哈希表、扫描哈希表和匹配结果。
构建哈希表:
```c
static HashJoinTable
ExecHashTableCreate(PlanState *parent,
List *hashOperators, /* hash function to use for each join key */
long nbuckets, /* # buckets in hashtable */
Size entrysize, /* size of each entry in hashtable */
bool use_variable_hash_iv)
{
HashJoinTable hashtable;
int nbuckets_est = nbuckets;
int log2_nbuckets;
/* Limit nbuckets to at most INT_MAX; must do this before sizing to power of 2 */
if ((double) nbuckets_est * (double) entrysize > (double) INT_MAX)
nbuckets_est = (int) floor((double) INT_MAX / (double) entrysize);
/* Size hash table to a power of 2 */
log2_nbuckets = my_log2(nbuckets_est);
hashtable = (HashJoinTable) palloc0(HJTUPLE_OVERHEAD +
sizeof(HashJoinTableData) +
(entrysize * (1 << log2_nbuckets)));
hashtable->nbuckets = nbuckets_est;
hashtable->log2_nbuckets = log2_nbuckets;
hashtable->buckets = (HashJoinTuple *)
(((char *) hashtable) + HJTUPLE_OVERHEAD + sizeof(HashJoinTableData));
hashtable->hash_iv = GetPerTupleExprContext(parent)->ecxt_hashjoin_outer;
/* Initialize all hash bucket headers to empty */
MemSet(hashtable->buckets, 0, sizeof(HashJoinTuple) << log2_nbuckets);
/* Set up array containing OIDs of hash operators */
ExecChooseHashFuncs(hashOperators,
hashtable->hashfunctions,
hashtable->nbuckets,
use_variable_hash_iv);
return hashtable;
}
```
扫描哈希表:
```c
static TupleTableSlot *
ExecScanHashBucket(HashJoinState *hjstate,
ExprContext *econtext)
{
HashJoinTable hashtable = hjstate->hj_HashTable;
AttrNumber *hj_OuterHashKeys = hjstate->hj_OuterHashKeys;
TupleTableSlot *innerTupleSlot = hjstate->hj_InnerTupleSlot;
TupleTableSlot *outerTupleSlot = hjstate->hj_OuterTupleSlot;
HashJoinTuple hashTuple;
uint32 hashvalue;
int bucketno;
/* loop until we find a join tuple */
for (;;)
{
hashvalue = ExecHashGetBucket(hjstate, hashtable,
hj_OuterHashKeys,
econtext,
false);
bucketno = ExecHashGetBucketNumber(hashvalue, hashtable->log2_nbuckets);
/*
* Scan the bucket for matching tuples.
*/
for (hashTuple = hashtable->buckets[bucketno];
hashTuple != NULL;
hashTuple = hashTuple->next)
{
if (hashTuple->hashvalue != hashvalue)
continue;
/* Found a match? Then report and save tuple */
if (ExecQualAndReset(hashTuple->hashressupport, econtext))
{
/* save the matching tuple */
ExecStoreMinimalTuple(HJTUPLE_MINTUPLE(hashTuple),
innerTupleSlot,
false);
/* set up for next join tuple, if any */
hjstate->hj_CurHashValue = hashvalue;
hjstate->hj_CurBucketNo = bucketno;
return outerTupleSlot;
}
}
/*
* No match in this bucket; check for additional matches in outer
* batches.
*/
if (!ExecScanHashTableForUnmatched(hjstate, econtext))
return NULL; /* need new outer tuple */
}
}
```
匹配结果:
```c
static TupleTableSlot *
ExecHashJoin(HashJoinState *node)
{
PlanState *outerNode = outerPlanState(node);
HashJoinTable hashtable = node->hj_HashTable;
TupleTableSlot *innerTupleSlot = node->hj_InnerTupleSlot;
TupleTableSlot *outerTupleSlot = node->hj_OuterTupleSlot;
ExprContext *econtext = node->js.ps.ps_ExprContext;
TupleTableSlot *result;
MinimalTuple tuple;
/*
* Reset per-tuple memory context to free any expression evaluation
* storage allocated in the previous tuple cycle.
*/
ResetExprContext(econtext);
/*
* if first time through, read all inner tuples into hashtable
*/
if (!node->hj_CurHashValue)
{
/* Reset hash table to empty */
ExecHashTableReset(hashtable);
/* Load hashtable with inner tuples */
ExecHashJoinNewBatch(node);
/* If inner relation is completely empty, return no rows */
if (hashtable->totalTuples == 0)
return NULL;
}
/*
* We read the outer tuple in the previous iteration, which means that we
* have to check for additional join matches for it before continuing.
*/
if (node->hj_JoinState == HJ_NEED_NEW_OUTER)
{
if (!ExecScanHashTableForUnmatched(node, econtext))
return NULL; /* need new outer tuple */
}
/*
* Now check for any matches
*/
for (;;)
{
/*
* If we've run out of inner tuples, then the current outer tuple
* can't have a match, so we're done with it.
*/
if (node->hj_CurTuple == NULL)
{
if (!ExecScanHashTableForUnmatched(node, econtext))
break; /* need new outer tuple */
continue; /* search next hash bucket */
}
/*
* Check for join match.
*/
if (ExecQual(node->js.ps.qual, econtext))
{
/*
* qualification was satisfied so we project and return the
* slot containing joined tuples, making sure that the slot is
* labeled with the join's rowtype.
*/
ExecProject(node->js.ps.ps_ProjInfo);
result = node->js.ps.ps_ProjInfo->pi_slot;
/*
* We return the first (and only) qualifying join tuple. The
* executor doesn't support the idea of generating multiple
* join rows from one outer tuple when there are multiple
* matching inner tuples (compare the semantics of a nested
* loops join).
*/
if (hashtable->nbatch == 1)
{
/* In single-batch case, just return the result */
return result;
}
else
{
/*
* Before returning the first join tuple, force the
* other tuples in the same join group to be fetched and
* appended to the result list.
*/
tuple = ExecFetchSlotMinimalTuple(innerTupleSlot);
ExecHashTableMarkCurBucket(hjstate);
ExecHashTableGetBucketAndBatch(hashtable,
node->hj_CurHashValue,
&node->hj_CurBucketNo,
&node->hj_CurTuple,
&node->hj_CurBucketBuf);
/*
* Set the next tuple to return, if any. Done in this order
* so that if there is only one tuple in the group, we don't
* advance the pointers at all.
*/
if (node->hj_CurTuple != NULL)
node->hj_NextTuple = node->hj_CurTuple->next;
else
node->hj_NextTuple = NULL;
/* Remember there's a join tuple available */
node->hj_JoinState = HJ_NEED_NEW_OUTER;
/* And return the first tuple */
return result;
}
}
/*
* Didn't match this time. Try next tuple in inner relation.
*/
node->hj_CurTuple = node->hj_CurTuple->next;
}
/*
* no more matches
*/
return NULL;
}
```
以上代码是 PostgreSQL 中 hashjoin 的基本实现,可以作为参考。
相关推荐
最新推荐
hash join 原理和算法
但如果内存不足,Oracle会采取分区策略,即将数据分割成多个不连续的分区(Si和Bi),并分别对每个分区执行Hash Join。如果某个分区的哈希表仍然过大,Oracle会退化为Nested-Loops Hash Join,逐个对剩余的分区构建...
常用Hash算法(C语言的简单实现)
下面小编就为大家带来一篇常用Hash算法(C语言的简单实现)。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧
oracle分区表之hash分区表的使用及扩展
Oracle分区表中的Hash分区是一种基于哈希算法的分区策略,适用于...在实际应用中,创建和扩展Hash分区表时,应结合业务需求和数据特性,综合考虑分区键的选择、分区数的设定以及扩展策略,以实现最佳的性能和管理效果。
Python实现通过文件路径获取文件hash值的方法
首先,我们来看两种常见的哈希函数——MD5(Message-Digest Algorithm 5)和SHA1(Secure Hash Algorithm 1)。MD5是一种广泛使用的哈希函数,产生一个128位的摘要,通常以32个十六进制数字的形式表示。SHA1则产生一...
JAVA实现空间索引编码——GeoHash的示例
GeoHash是一种高效的空间索引编码技术,用于将地理位置(经度和纬度)转换为可排序、可比较的字符串。这种编码方式能够帮助我们在大量位置信息中快速查找最近的位置。在JAVA中实现GeoHash,我们可以按照以下步骤进行...
BSC关键绩效财务与客户指标详解
BSC(Balanced Scorecard,平衡计分卡)是一种战略绩效管理系统,它将企业的绩效评估从传统的财务维度扩展到非财务领域,以提供更全面、深入的业绩衡量。在提供的文档中,BSC绩效考核指标主要分为两大类:财务类和客户类。
1. 财务类指标:
- 部门费用的实际与预算比较:如项目研究开发费用、课题费用、招聘费用、培训费用和新产品研发费用,均通过实际支出与计划预算的百分比来衡量,这反映了部门在成本控制上的效率。
- 经营利润指标:如承保利润、赔付率和理赔统计,这些涉及保险公司的核心盈利能力和风险管理水平。
- 人力成本和保费收益:如人力成本与计划的比例,以及标准保费、附加佣金、续期推动费用等与预算的对比,评估业务运营和盈利能力。
- 财务效率:包括管理费用、销售费用和投资回报率,如净投资收益率、销售目标达成率等,反映公司的财务健康状况和经营效率。
2. 客户类指标:
- 客户满意度:通过包装水平客户满意度调研,了解产品和服务的质量和客户体验。
- 市场表现:通过市场销售月报和市场份额,衡量公司在市场中的竞争地位和销售业绩。
- 服务指标:如新契约标保完成度、续保率和出租率,体现客户服务质量和客户忠诚度。
- 品牌和市场知名度:通过问卷调查、公众媒体反馈和总公司级评价来评估品牌影响力和市场认知度。
BSC绩效考核指标旨在确保企业的战略目标与财务和非财务目标的平衡,通过量化这些关键指标,帮助管理层做出决策,优化资源配置,并驱动组织的整体业绩提升。同时,这份指标汇总文档强调了财务稳健性和客户满意度的重要性,体现了现代企业对多维度绩效管理的重视。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
【实战演练】俄罗斯方块:实现经典的俄罗斯方块游戏,学习方块生成和行消除逻辑。
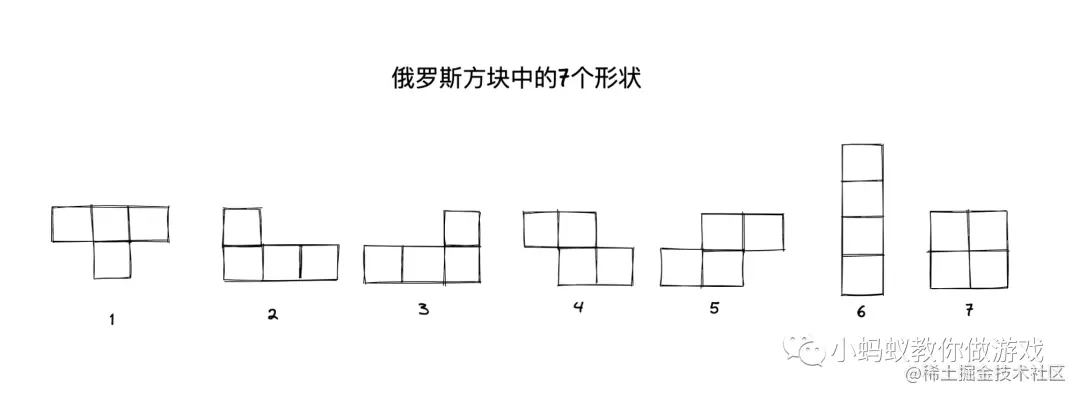
# 1. 俄罗斯方块游戏概述**
俄罗斯方块是一款经典的益智游戏,由阿列克谢·帕基特诺夫于1984年发明。游戏目标是通过控制不断下落的方块,排列成水平线,消除它们并获得分数。俄罗斯方块风靡全球,成为有史以来最受欢迎的视频游戏之一。
# 2.
卷积神经网络实现手势识别程序
卷积神经网络(Convolutional Neural Network, CNN)在手势识别中是一种非常有效的机器学习模型。CNN特别适用于处理图像数据,因为它能够自动提取和学习局部特征,这对于像手势这样的空间模式识别非常重要。以下是使用CNN实现手势识别的基本步骤:
1. **输入数据准备**:首先,你需要收集或获取一组带有标签的手势图像,作为训练和测试数据集。
2. **数据预处理**:对图像进行标准化、裁剪、大小调整等操作,以便于网络输入。
3. **卷积层(Convolutional Layer)**:这是CNN的核心部分,通过一系列可学习的滤波器(卷积核)对输入图像进行卷积,以
绘制企业战略地图:从财务到客户价值的六步法
"BSC资料.pdf"
战略地图是一种战略管理工具,它帮助企业将战略目标可视化,确保所有部门和员工的工作都与公司的整体战略方向保持一致。战略地图的核心内容包括四个相互关联的视角:财务、客户、内部流程和学习与成长。
1. **财务视角**:这是战略地图的最终目标,通常表现为股东价值的提升。例如,股东期望五年后的销售收入达到五亿元,而目前只有一亿元,那么四亿元的差距就是企业的总体目标。
2. **客户视角**:为了实现财务目标,需要明确客户价值主张。企业可以通过提供最低总成本、产品创新、全面解决方案或系统锁定等方式吸引和保留客户,以实现销售额的增长。
3. **内部流程视角**:确定关键流程以支持客户价值主张和财务目标的实现。主要流程可能包括运营管理、客户管理、创新和社会责任等,每个流程都需要有明确的短期、中期和长期目标。
4. **学习与成长视角**:评估和提升企业的人力资本、信息资本和组织资本,确保这些无形资产能够支持内部流程的优化和战略目标的达成。
绘制战略地图的六个步骤:
1. **确定股东价值差距**:识别与股东期望之间的差距。
2. **调整客户价值主张**:分析客户并调整策略以满足他们的需求。
3. **设定价值提升时间表**:规划各阶段的目标以逐步缩小差距。
4. **确定战略主题**:识别关键内部流程并设定目标。
5. **提升战略准备度**:评估并提升无形资产的战略准备度。
6. **制定行动方案**:根据战略地图制定具体行动计划,分配资源和预算。
战略地图的有效性主要取决于两个要素:
1. **KPI的数量及分布比例**:一个有效的战略地图通常包含20个左右的指标,且在四个视角之间有均衡的分布,如财务20%,客户20%,内部流程40%。
2. **KPI的性质比例**:指标应涵盖财务、客户、内部流程和学习与成长等各个方面,以全面反映组织的绩效。
战略地图不仅帮助管理层清晰传达战略意图,也使员工能更好地理解自己的工作如何对公司整体目标产生贡献,从而提高执行力和组织协同性。