File "F:\pythonproject\GRU\GRU2.py", line 29 data_path = 'C:\Users\ASUS\Desktop\江苏扬州道旅\宝应县汽车运输总公司(扬321023000100)F4.xlsx' ^ SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape
时间: 2023-07-21 14:15:32 浏览: 104
这个错误是由于在文件路径中使用了反斜杠“\”,但是这个字符在Python中是有特殊意义的,因此需要将其转义。你可以将路径中的反斜杠改成双反斜杠“\\”,或者在路径前面加上一个“r”来表示这是一个原始字符串,例如:
```python
data_path = r'C:\Users\ASUS\Desktop\江苏扬州道旅\宝应县汽车运输总公司(扬321023000100)F4.xlsx'
```
或者
```python
data_path = 'C:\\Users\\ASUS\\Desktop\\江苏扬州道旅\\宝应县汽车运输总公司(扬321023000100)F4.xlsx'
```
这样就能够避免这个错误了。
相关问题
Traceback (most recent call last): File "F:\pythonproject\GRU\GRU2.py", line 93, in <module> df = pd.read_csv(config.data_path, index_col=0) AttributeError: 'Config' object has no attribute 'data_path'
这个错误的原因是在你的代码中,Config类没有定义名为"data_path"的属性,但是你在代码的某个地方调用了这个属性。你需要检查一下你的Config类定义,确保它包含了一个"data_path"属性,并且这个属性指向你的数据文件。如果你已经定义了这个属性,那么可能是因为你没有正确地实例化Config对象,导致程序无法获取到这个属性的值。你需要仔细检查一下你的代码,并且确保你正确地实例化了Config对象,并且传递了正确的参数。
Traceback (most recent call last): File "F:\pythonproject\GRU\GRU2.py", line 182, in <module> loss_function = nn.functional.ELU() # 定义损失函数 AttributeError: module 'torch.nn.functional' has no attribute 'ELU'
这个错误提示是因为在PyTorch的`nn.functional`模块中没有`ELU`函数。可能你想要使用的是`nn.ELU`函数,因为`nn.ELU`是PyTorch中的一个激活函数。
你可以将`nn.functional.ELU()`替换成`nn.ELU()`即可解决该错误。例如:
```python
import torch.nn as nn
loss_function = nn.ELU() # 使用nn.ELU()定义损失函数
```
相关推荐
最新推荐
常用芯片手册芯片资料MAX260常用芯片手册芯片资料MAX260
常用芯片手册芯片资料MAX260常用芯片手册芯片资料MAX260提取方式是百度网盘分享地址
常用芯片手册芯片资料82530常用芯片手册芯片资料82530
常用芯片手册芯片资料82530常用芯片手册芯片资料82530提取方式是百度网盘分享地址
全国互联网网民数和互联网普及率.xlsx
1、资源内容地址:https://blog.csdn.net/2301_79696294/article/details/141286857
2、代码特点:今年全新,手工精心整理,放心引用,数据来自权威,相对于其他人的控制变量数据准确很多,适合写论文做实证用 ,不会出现数据造假问题
3、适用对象:大学生,本科生,研究生小白可用,容易上手!!!
3、课程引用: 经济学,地理学,城市规划与城市研究,公共政策与管理,社会学,商业与管理
各省、地级市、区县互联网普及率、宽带接入户数和电话用户数等
1、全国互联网网民数和互联网普及率(1997-2020年);
2、各省互联网网民数和互联网普及率(1997-2016年);
3、地级市互联网宽带接入用户(1996-2020年);
4、各区县电话用户数(2004-2019年)
SQLAlchemy-2.0.30-cp37-cp37m-musllinux_1_1_x86_64.whl
SQLAlchemy 是一个 SQL 工具包和对象关系映射(ORM)库,用于 Python 编程语言。它提供了一个高级的 SQL 工具和对象关系映射工具,允许开发者以 Python 类和对象的形式操作数据库,而无需编写大量的 SQL 语句。SQLAlchemy 建立在 DBAPI 之上,支持多种数据库后端,如 SQLite, MySQL, PostgreSQL 等。
SQLAlchemy 的核心功能:
对象关系映射(ORM):
SQLAlchemy 允许开发者使用 Python 类来表示数据库表,使用类的实例表示表中的行。
开发者可以定义类之间的关系(如一对多、多对多),SQLAlchemy 会自动处理这些关系在数据库中的映射。
通过 ORM,开发者可以像操作 Python 对象一样操作数据库,这大大简化了数据库操作的复杂性。
表达式语言:
SQLAlchemy 提供了一个丰富的 SQL 表达式语言,允许开发者以 Python 表达式的方式编写复杂的 SQL 查询。
表达式语言提供了对 SQL 语句的灵活控制,同时保持了代码的可读性和可维护性。
数据库引擎和连接池:
SQLAlchemy 支持多种数据库后端,并且为每种后端提供了对应的数据库引擎。
它还提供了连接池管理功能,以优化数据库连接的创建、使用和释放。
会话管理:
SQLAlchemy 使用会话(Session)来管理对象的持久化状态。
会话提供了一个工作单元(unit of work)和身份映射(identity map)的概念,使得对象的状态管理和查询更加高效。
事件系统:
SQLAlchemy 提供了一个事件系统,允许开发者在 ORM 的各个生命周期阶段插入自定义的钩子函数。
这使得开发者可以在对象加载、修改、删除等操作时执行额外的逻辑。
百度云/百度网盘Python客户端
极简说明
安装: pip install bypy
运行: bypy
这是一个百度云/百度网盘的Python客户端。主要的目的就是在Linux环境下(Windows下应该也可用,但没有仔细测试过)通过命令行来使用百度云盘的2TB的巨大空间。比如,你可以用在Raspberry Pi树莓派上。它提供文件列表、下载、上传、比较、向上同步、向下同步,等操作。
贵州煤矿矿井水分类与处理策略:悬浮物、酸性与非酸性
贵州煤矿区的矿井水水质具有鲜明的特点,主要分为含悬浮物矿井水、酸性含铁锰矿井水和非酸性含铁锰矿井水三类。这些分类基于矿井水的水质特性,如悬浮物含量、酸碱度和铁锰离子浓度等。
含悬浮物矿井水是贵州普遍存在的,主要来源于煤粉和岩粉在开采过程中产生的沉淀。经过井下水仓的自然沉淀,大部分悬浮物会被去除,地面抽上来的水悬浮物浓度较低,但依然可能存在50微米以下的细小颗粒。处理这类水通常采用混凝沉淀加过滤工艺,可以有效去除悬浮物,保证水质。
酸性含铁锰矿井水则表现出较高的铁锰含量,这对水质处理提出了特殊要求。针对这种情况,建议采用中和处理结合混凝沉淀和过滤的方式,使用高锰酸钾溶液(浓度5%)浸泡过的锰砂作为滤料,这样可以减少矿井水处理站的启动时间,并且有助于进一步净化水质。
非酸性含铁锰矿井水的处理相对较简单,通常采用混凝沉淀和锰砂过滤的组合工艺,能够有效地去除铁锰离子,保持水质稳定。
总结来说,矿井水的水质特点决定了其处理工艺的选择,对于贵州地区而言,针对性地选择合适的处理方案至关重要,既能确保矿井水达到排放标准,又能有效降低对环境的负面影响。这方面的研究和实践对于提升矿井水资源利用效率,实现绿色开采具有重要的现实意义。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
人工智能透明度革命:如何构建可解释的AI系统
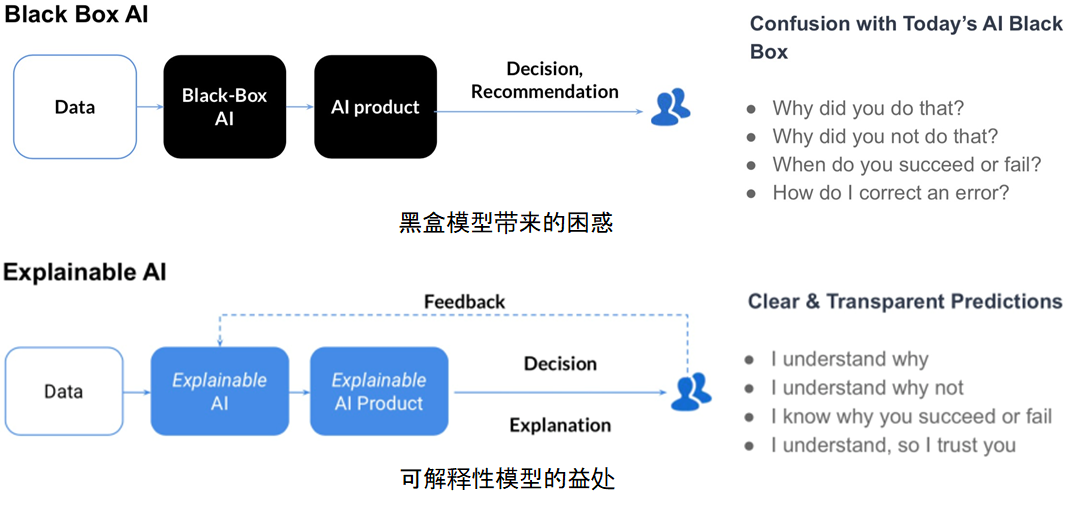
# 1. 人工智能透明度的重要性
随着人工智能(AI)技术在多个领域的广泛应用,AI系统的决策过程和结果的透明度变得至关重要。透明度不仅有助于建立用户信任,还是解决潜在偏见、提升公平性和可解释性的基石。在本章中,我们将探讨透明度对于AI系统的重要性,并分析为什么它对于建立社会对AI技术的信任至关重要。
## 1.1 AI透明度的社会影响
AI透明度指的是能够让用户了解
mig ip核打不开
MIG (Model Interchange for Graphics) 是一种用于图形处理器(GPU)硬件设计的模型交换格式,主要用于描述GPU架构。如果遇到"mig ip核打不开"的问题,可能是以下几个原因:
1. **权限不足**:检查文件路径是否有足够的权限访问该MIG IP核文件。
2. **软件兼容性**:确认使用的工具是否支持当前的MIG版本,旧版工具可能无法打开新版本的IP核。
3. **环境配置**:确保所有依赖的库和开发环境变量已正确设置,尤其是与MIG相关的SDK和编译器。
4. **错误的文件**:确认MIG IP核文件本身没有损坏或者不是针对您的开发平台设计的。
醛固酮增多症肾上腺静脉采样对比:ACTH后LR-CAV的最优评估
本文研究关注于原发性醛固酮增多症(PA)患者的肾上腺静脉采样技术,这是一种在临床诊断中用于评估高血压和肾上腺功能异常的重要手段。研究的目的是确定在进行侧斜度评估前,哪种方法能够提供最精确的诊断信息,以便早期识别单侧PA。
研究采用了回顾性设计,纳入了64例连续的PA患者。研究团队通过将导管置入总干静脉(CTV),并在促肾上腺皮质激素(ACTH)刺激前后的不同时间点进行血液采样。主要评估的指标包括横向比例(LR,即高值侧醛固酮/皮质醇比率与低值侧的比率)、对侧比率(CR,低值侧的ACR与下腔静脉比率的ACR),以及血浆醛固酮浓度(PAC)。
结果显示,ACTH刺激后,LR-CAV(来自中肾上腺静脉的比率)对于单侧肾上腺病变的检测率最高,达到93.3%(14/15),具有良好的灵敏度(0.93)和特异性(0.84),当切点设为2.5时。CR-POST-ACTH的Area Under the Curve(Az值)也表现出较高的性能,检出率为86.7%(13/14),其灵敏度达到0.98,特异性在0.88(当截止值为0.8时)。
这些发现表明,CR在ACTH刺激后和LR-CAV在ACTH刺激后的评估方法对PA的侧向评估具有高度准确性,可以作为临床决策的重要依据。对于原发性醛固酮增多症的患者,选择合适的肾上腺静脉采样技术不仅可以帮助医生更准确地定位病灶,还能提高治疗的针对性和患者预后。
该研究发表在《开放放射学杂志》上,强调了在诊断PA时,尤其是在决定是否需要进行进一步的手术干预前,合理运用这些评估方法的重要性。它为临床实践提供了实用的指导,特别是在处理可能涉及肾上腺功能异常的复杂病例时。