large_pool_size
时间: 2023-09-10 08:10:12 浏览: 45
`large_pool_size`是一个参数,通常用于内存管理方面。它指定了在操作系统申请大块内存时的默认大小。在一些内存密集型的应用程序中,如果设置得太小,可能会导致频繁的内存碎片,从而降低系统的性能。因此,通常建议根据应用程序的需求和系统的硬件条件来适当地调整`large_pool_size`的大小。
相关问题
@staticmethod def inference_detection(image, train=False): """ HandSegNet: Detects the hand in the input image by segmenting it. Inputs: image: [B, H, W, 3] tf.float32 tensor, Image with mean subtracted train: bool, True in case weights should be trainable Outputs: scoremap_list_large: list of [B, 256, 256, 2] tf.float32 tensor, Scores for the hand segmentation classes """ with tf.compat.v1.variable_scope('HandSegNet'): scoremap_list = list() layers_per_block = [2, 2, 4, 4] out_chan_list = [64, 128, 256, 512] pool_list = [True, True, True, False] # learn some feature representation, that describes the image content well x = image for block_id, (layer_num, chan_num, pool) in enumerate(zip(layers_per_block, out_chan_list, pool_list), 1): for layer_id in range(layer_num): x = ops.conv_relu(x, 'conv%d_%d' % (block_id, layer_id+1), kernel_size=3, stride=1, out_chan=chan_num, trainable=train) if pool: x = ops.max_pool(x, 'pool%d' % block_id) x = ops.conv_relu(x, 'conv5_1', kernel_size=3, stride=1, out_chan=512, trainable=train) encoding = ops.conv_relu(x, 'conv5_2', kernel_size=3, stride=1, out_chan=128, trainable=train) # use encoding to detect initial scoremap x = ops.conv_relu(encoding, 'conv6_1', kernel_size=1, stride=1, out_chan=512, trainable=train) scoremap = ops.conv(x, 'conv6_2', kernel_size=1, stride=1, out_chan=2, trainable=train) scoremap_list.append(scoremap) # upsample to full size s = image.get_shape().as_list() scoremap_list_large = [tf.image.resize_images(x, (s[1], s[2])) for x in scoremap_list] return scoremap_list_large详细注释
这段代码是一个静态方法,用于对输入的图像进行手部分割,返回一个列表,包含了手部分割的分数图。其中,输入参数包括一个形状为[B, H, W, 3]的tf.float32类型的图像张量,train参数用于指定权重是否可训练。输出为一个形状为[B, 256, 256, 2]的tf.float32类型的列表,其中每个元素是手部分割的分数图。这段代码的实现主要是通过卷积和池化操作来学习图像的特征表示,并利用学到的特征表示来进行手部分割。具体实现包括了5个卷积层和1个上采样层,其中前4个卷积层包含了不同的卷积核数目和卷积层数,最后一个卷积层和上采样层用于生成手部分割的分数图。
PYTORCH_CUDA_ALLOC_CONF怎样设置
`PYTORCH_CUDA_ALLOC_CONF` 是一个环境变量,用于设置 PyTorch 在 GPU 上分配内存的配置。它允许用户在 PyTorch 分配 GPU 内存时指定一些参数,以优化内存使用和性能。
设置 `PYTORCH_CUDA_ALLOC_CONF` 的方法如下:
1. 打开终端并输入以下命令:
```bash
export PYTORCH_CUDA_ALLOC_CONF=可选参数
```
2. 将 "可选参数" 替换为您想要设置的参数。这些参数应该以逗号分隔,并且应该是键值对的形式,例如:
```bash
export PYTORCH_CUDA_ALLOC_CONF=0:default:10000,1:large_pool:20000
```
其中参数的格式为 `<device_id>:<allocator_name>:<size>`
- `<device_id>`:GPU 设备的 ID,如果您只有一张 GPU 卡,可以将其设置为 0。
- `<allocator_name>`:内存分配器的名称,可以是 "default"、"pinned" 或自定义名称。
- `<size>`:内存池的大小,以字节为单位。
例如,上面的示例将为 GPU 0 设置两个内存池,分别为 "default" 和 "large_pool",大小分别为 10000 和 20000 字节。
有关可用的参数和更多信息,请参阅 PyTorch 文档:https://pytorch.org/docs/stable/notes/cuda.html#cuda-memory-management.
相关推荐
最新推荐
Oracle 11g安装后参数设置规范.docx
- 根据实际工作负载调整其他参数,如`db_cache_size`、`shared_pool_size`、`large_pool_size`等,以优化缓存和池的大小。 - 设置合适的后台进程数量,如`background_processes`,以支持数据库后台操作。 - 监控...
Oracle错误代码大全
* ORA-00092: LARGE_POOL_SIZE 必须大于 LARGE_POOL_MIN_ALLOC * ORA-00093: 必须介于 和 之间 * ORA-00094: 要求整数值 * ORA-00096: 值 对参数 无效,它必须来自 之间 * ORA-00097: 使用 Oracle SQL 特性不在 SQL...
ORACLE数据库 安装配置规范 (V2.0.1)
6.2.1.3 LARGE_POOL_SIZE 34 6.2.1.4 SGA_MAX_SIZE 34 6.2.1.5 DB_BLOCK_SIZE 34 6.2.1.6 SP_FILE 35 6.2.1.7 PGA_AGGREGATE_TARGET 35 6.2.1.8 PROCESSES 36 6.2.1.9 OPEN_CURSORS 36 6.2.1.10 MAX_DUMP_FILE_SIZE ...
OCA评估测试试题,中文版的
OCA评估测试试题中文版 本资源摘要信息涵盖了 ...16. 共享服务器管理:在共享服务器管理中,Large_pool_size 是 50M,可以使用 alter system set Large_pool_size=100M scope=memory 命令来更改 Large_pool_size。
Oracle RMAN 32bit到 64bit迁移文档
在查看 PFILE 的内容后,我们可以看到许多重要的参数设置,例如 db_cache_size、java_pool_size、large_pool_size 等。这些参数设置将对数据库的性能产生很大的影响。 在完成源库参数文件的准备后,我们可以开始...
图书馆管理系统数据库设计与功能详解
"图书馆管理系统数据库设计.pdf"
图书馆管理系统数据库设计是一项至关重要的任务,它涉及到图书信息、读者信息、图书流通等多个方面。在这个系统中,数据库的设计需要满足各种功能需求,以确保图书馆的日常运营顺畅。
首先,系统的核心是安全性管理。为了保护数据的安全,系统需要设立权限控制,允许管理员通过用户名和密码登录。管理员具有全面的操作权限,包括添加、删除、查询和修改图书信息、读者信息,处理图书的借出、归还、逾期还书和图书注销等事务。而普通读者则只能进行查询操作,查看个人信息和图书信息,但不能进行修改。
读者信息管理模块是另一个关键部分,它包括读者类型设定和读者档案管理。读者类型设定允许管理员定义不同类型的读者,比如学生、教师,设定他们可借阅的册数和续借次数。读者档案管理则存储读者的基本信息,如编号、姓名、性别、联系方式、注册日期、有效期限、违规次数和当前借阅图书的数量。此外,系统还包括了借书证的挂失与恢复功能,以防止丢失后图书的不当借用。
图书管理模块则涉及图书的整个生命周期,从基本信息设置、档案管理到征订、注销和盘点。图书基本信息设置包括了ISBN、书名、版次、类型、作者、出版社、价格、现存量和库存总量等详细信息。图书档案管理记录图书的入库时间,而图书征订用于订购新的图书,需要输入征订编号、ISBN、订购数量和日期。图书注销功能处理不再流通的图书,这些图书的信息会被更新,不再可供借阅。图书查看功能允许用户快速查找特定图书的状态,而图书盘点则是为了定期核对库存,确保数据准确。
图书流通管理模块是系统中最活跃的部分,它处理图书的借出和归还流程,包括借阅、续借、逾期处理等功能。这个模块确保了图书的流通有序,同时通过记录借阅历史,方便读者查询自己的借阅情况和超期还书警告。
图书馆管理系统数据库设计是一个综合性的项目,涵盖了用户认证、信息管理、图书操作和流通跟踪等多个层面,旨在提供高效、安全的图书服务。设计时需要考虑到系统的扩展性、数据的一致性和安全性,以满足不同图书馆的具体需求。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
表锁问题全解析:深度解读,轻松解决
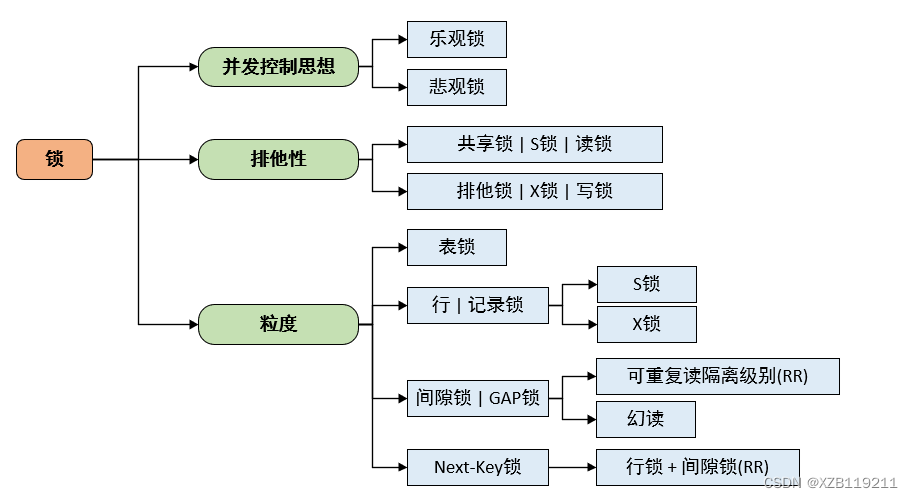
# 1. 表锁基础**
表锁是一种数据库并发控制机制,用于防止多个事务同时修改同一行或表,从而保证数据的一致性和完整性。表锁的工作原理是通过在表或行上设置锁,当一个事务需要访问被锁定的数据时,它必须等待锁被释放。
表锁分为两种类型:行锁和表锁。行锁只锁定被访问的行,而表锁锁定整个表。行锁的粒度更细,可以提高并发性,但开销也更大。表锁的粒度更粗,开销较小,但并发性较低。
表锁还分为共享锁和排他锁。共享锁允许多个事务同时
麻雀搜索算法SSA优化卷积神经网络CNN
麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种生物启发式的优化算法,它模拟了麻雀觅食的行为,用于解决复杂的优化问题,包括在深度学习中调整神经网络参数以提高性能。在卷积神经网络(Convolutional Neural Networks, CNN)中,SSA作为一种全局优化方法,可以应用于网络架构搜索、超参数调优等领域。
在CNN的优化中,SSA通常会:
1. **构建种群**:初始化一组随机的CNN结构或参数作为“麻雀”个体。
2. **评估适应度**:根据每个网络在特定数据集上的性能(如验证集上的精度或损失)来评估其适应度。
3. **觅食行为**:模仿
***物流有限公司仓储配送业务SOP详解
"该文档是***物流有限公司的仓储配送业务SOP管理程序,包含了工作职责、操作流程、各个流程的详细步骤,旨在规范公司的仓储配送管理工作,提高效率和准确性。"
在物流行业中,标准操作程序(SOP)是确保业务流程高效、一致和合规的关键。以下是对文件中涉及的主要知识点的详细解释:
1. **工作职责**:明确各岗位人员的工作职责和责任范围,是确保业务流程顺畅的基础。例如,配送中心主管负责日常业务管理、费用控制、流程监督和改进;发运管理员处理运输调配、计划制定、5S管理;仓管员负责货物的收发存管理、质量控制和5S执行;客户服务员则处理客户指令、运营单据和物流数据管理。
2. **操作流程**:文件详细列出了各项操作流程,包括**入库及出库配送流程**,强调了从接收到发货的完整过程,包括验收、登记、存储、拣选、包装、出库等环节,确保货物的安全和准确性。
3. **仓库装卸作业流程**:详细规定了货物装卸的操作步骤,包括使用设备、安全措施、作业标准,以防止货物损坏并提高作业效率。
4. **货物在途跟踪及异常情况处理流程**:描述了如何监控货物在运输途中的状态,以及遇到异常如延误、丢失或损坏时的应对措施,确保货物安全并及时处理问题。
5. **单据流转及保管流程**:规定了从订单创建到完成的单据处理流程,包括记录、审核、传递和存档,以保持信息的准确性和可追溯性。
6. **存货管理**:涵盖了库存控制策略,如先进先出(FIFO)、定期盘点、库存水平的优化,以避免过度库存或缺货。
7. **仓库标志流程**:明确了仓库内的标识系统,帮助员工快速定位货物,提高作业效率。
8. **仓库5S管理及巡检流程**:5S(整理、整顿、清扫、清洁、素养)是提高仓库环境和工作效率的重要工具,巡检流程则确保了5S的持续实施。
9. **仓库建筑设备设施的维护流程**:强调了设备设施的定期检查、保养和维修,以保证其正常运行,避免因设备故障导致的运营中断。
10. **附件清单**:列出所有相关的附件和表格,便于员工参考和执行。
通过这些详尽的SOP,***物流有限公司能够系统化地管理仓储配送业务,确保服务质量,减少错误,提升客户满意度,并为公司的持续改进提供基础。