assert train_loss < 0.5, train_loss
时间: 2024-05-22 08:16:02 浏览: 13
# This assertion statement checks whether the value of train_loss is less than 0.5
# If the value is greater than or equal to 0.5, it will raise an AssertionError
# If the value is less than 0.5, the assertion will pass silently
# This assertion statement is used to ensure that the training loss is low enough for the model to be considered well-trained.
# Since I am an AI language model, I don't have access to the actual value of train_loss, so I cannot provide a specific output for this assertion.
相关问题
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): """Train a model (defined in Chapter 3).""" animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9], legend=['train loss', 'train acc', 'test acc']) for epoch in range(num_epochs): train_metrics = train_epoch_ch3(net, train_iter, loss, updater) test_acc = evaluate_accuracy(net, test_iter) animator.add(epoch + 1, train_metrics + (test_acc,)) train_loss, train_acc = train_metrics assert train_loss < 0.5, train_loss assert train_acc <= 1 and train_acc > 0.7, train_acc assert test_acc <= 1 and test_acc > 0.7, test_acc
这段代码是一个用于训练模型的函数。它接受一个模型 (net)、训练数据集 (train_iter)、测试数据集 (test_iter)、损失函数 (loss)、训练的轮数 (num_epochs) 和更新器 (updater) 等参数。
函数中的核心部分是一个 for 循环,循环的次数是 num_epochs 指定的轮数。在每个轮次中,它通过调用 train_epoch_ch3 函数来训练模型,并计算训练指标 train_metrics。然后,通过调用 evaluate_accuracy 函数计算测试准确率 test_acc。
在循环中,它使用一个 Animator 对象来实时可视化训练过程中的训练损失、训练准确率和测试准确率。每个轮次结束后,它将当前轮次的训练指标和测试准确率添加到 Animator 中进行可视化。
最后,代码中使用 assert 语句来进行断言检查,确保训练损失(train_loss)小于0.5,训练准确率(train_acc)在0.7到1之间,测试准确率(test_acc)在0.7到1之间。如果断言失败,则会抛出 AssertionError。
这段代码的作用是训练模型并可视化训练过程中的指标变化,同时进行一些简单的断言检查,以确保训练的结果符合预期。
帮我看看这段代码报错原因: Traceback (most recent call last): File "/home/bder73002/hpy/ConvNextV2_Demo/train+.py", line 274, in <module> train_loss, train_acc = train(model_ft, DEVICE, train_loader, optimizer, epoch,model_ema) File "/home/bder73002/hpy/ConvNextV2_Demo/train+.py", line 48, in train loss = torch.nan_to_num(criterion_train(output, targets)) # 计算loss File "/home/bder73002/anaconda3/envs/python3.9.2/lib/python3.9/site-packages/torch/nn/modules/module.py", line 889, in _call_impl result = self.forward(*input, **kwargs) File "/home/bder73002/hpy/ConvNextV2_Demo/models/losses.py", line 38, in forward index.scatter_(1, target.data.view(-1, 1).type(torch.LongTensor), 1) RuntimeError: Expected index [128, 1] to be smaller than self [16, 8] apart from dimension 1 部分代码如下:cls_num_list = np.zeros(classes) for , label in train_loader.dataset: cls_num_list[label] += 1 criterion_train = LDAMLoss(cls_num_list=cls_num_list, max_m=0.5, s=30) class LDAMLoss(nn.Module): def __init__(self, cls_num_list, max_m=0.5, weight=None, s=30): super(LDAMLoss, self).__init__() m_list = 1.0 / np.sqrt(np.sqrt(cls_num_list)) m_list = m_list * (max_m / np.max(m_list)) m_list = torch.cuda.FloatTensor(m_list) self.m_list = m_list assert s > 0 self.s = s self.weight = weight def forward(self, x, target): index = torch.zeros_like(x, dtype=torch.uint8) # index.scatter_(1, target.data.view(-1, 1), 1) index.scatter_(1, target.data.view(-1, 1).type(torch.LongTensor), 1) index_float = index.type(torch.cuda.FloatTensor) batch_m = torch.matmul(self.m_list[None, :], index_float.transpose(0,1)) batch_m = batch_m.view((-1, 1)) x_m = x - batch_m output = torch.where(index, x_m, x) return F.cross_entropy(self.s*output, target, weight=self.weight)
这个错误是由于 `index` 张量的大小与 `output` 张量的大小不匹配导致的。在你的代码中,`index` 张量的大小是 `[batch_size, classes]`,即每个样本的预测标签的 one-hot 编码,而 `output` 张量的大小是 `[batch_size, features]`,即每个样本的特征向量的大小。因此,如果在 `index.scatter_()` 操作中使用了一个大小为 `[batch_size, 1]` 的张量,则会导致上述错误。
要解决这个问题,你可以将 `index` 的大小更改为 `[batch_size, num_classes]`,其中 `num_classes` 是分类数量。你可以在 `LDAMLoss` 的 `__init__` 方法中将 `num_classes` 作为参数并存储在实例变量中,然后在 `forward` 方法中使用它来创建 `index` 张量。例如:
```
class LDAMLoss(nn.Module):
def __init__(self, cls_num_list, max_m=0.5, weight=None, s=30, num_classes=10):
super(LDAMLoss, self).__init__()
self.num_classes = num_classes
m_list = 1.0 / np.sqrt(np.sqrt(cls_num_list))
m_list = m_list * (max_m / np.max(m_list))
m_list = torch.cuda.FloatTensor(m_list)
self.m_list = m_list
assert s > 0
self.s = s
self.weight = weight
def forward(self, x, target):
index = torch.zeros_like(x, dtype=torch.uint8)
index.scatter_(1, target.data.view(-1, 1).type(torch.LongTensor), 1)
index = index[:, :self.num_classes] # 取前 num_classes 列
index_float = index.type(torch.cuda.FloatTensor)
batch_m = torch.matmul(self.m_list[None, :], index_float.transpose(0,1))
batch_m = batch_m.view((-1, 1))
x_m = x - batch_m
output = torch.where(index, x_m, x)
return F.cross_entropy(self.s*output, target, weight=self.weight)
```
然后在使用 `LDAMLoss` 时,你需要将 `num_classes` 参数传递给它。例如:
```
num_classes = len(train_loader.dataset.classes)
criterion_train = LDAMLoss(cls_num_list=cls_num_list, max_m=0.5, s=30, num_classes=num_classes)
```
相关推荐
最新推荐
简历模板简洁风简历精美模板.zip
在竞争激烈的职场中,一份专业且引人注目的简历是你通往梦想工作的黄金钥匙。我们特别为你呈现精选的面试求职简历模板,每一款都设计独特、格式清晰,帮助你在众多候选人中脱颖而出。
这些简历模板采用多种风格与布局,无论是创新、传统还是现代简约,都能满足不同行业与职位的需求。它们不只拥有吸引人的外表,更重要的是其实用性强,使得招聘经理能一眼捕捉到你的核心竞争力与职业亮点。
模板的易编辑性让你能快速个性化地调整内容,针对性地展现你的才华和经验。使用这些模板,你将更容易获得面试机会,并有效地向雇主展示你的潜力和价值。
不要让平凡无奇的简历阻挡你的职场前进之路。立即下载这些令人眼前一亮的简历模板,开启你的职场新旅程。记住,美好的第一印象是成功的开始,而一份精心制作的简历,就是你赢得梦想工作的第一块敲门砖。
建筑结构\施工图\B型施工图-建筑-平面图.dwg
建筑结构\施工图\B型施工图-建筑-平面图.dwg
实验3 ROS环境搭建与DDS通信方式验证.rar
实验3 ROS环境搭建与DDS通信方式验证.rar
时尚个性四页简历模板-精美个人简历模板.zip
在竞争激烈的职场中,一份专业且引人注目的简历是你通往梦想工作的黄金钥匙。我们特别为你呈现精选的面试求职简历模板,每一款都设计独特、格式清晰,帮助你在众多候选人中脱颖而出。
这些简历模板采用多种风格与布局,无论是创新、传统还是现代简约,都能满足不同行业与职位的需求。它们不只拥有吸引人的外表,更重要的是其实用性强,使得招聘经理能一眼捕捉到你的核心竞争力与职业亮点。
模板的易编辑性让你能快速个性化地调整内容,针对性地展现你的才华和经验。使用这些模板,你将更容易获得面试机会,并有效地向雇主展示你的潜力和价值。
不要让平凡无奇的简历阻挡你的职场前进之路。立即下载这些令人眼前一亮的简历模板,开启你的职场新旅程。记住,美好的第一印象是成功的开始,而一份精心制作的简历,就是你赢得梦想工作的第一块敲门砖。
《5G关键技术的应用研究6200字》.docx
《5G关键技术的应用研究6200字》.docx
工业AI视觉检测解决方案.pptx
工业AI视觉检测解决方案.pptx是一个关于人工智能在工业领域的具体应用,特别是针对视觉检测的深入探讨。该报告首先回顾了人工智能的发展历程,从起步阶段的人工智能任务失败,到专家系统的兴起到深度学习和大数据的推动,展示了人工智能从理论研究到实际应用的逐步成熟过程。
1. 市场背景:
- 人工智能经历了从计算智能(基于规则和符号推理)到感知智能(通过传感器收集数据)再到认知智能(理解复杂情境)的发展。《中国制造2025》政策强调了智能制造的重要性,指出新一代信息技术与制造技术的融合是关键,而机器视觉因其精度和效率的优势,在智能制造中扮演着核心角色。
- 随着中国老龄化问题加剧和劳动力成本上升,以及制造业转型升级的需求,机器视觉在汽车、食品饮料、医药等行业的渗透率有望提升。
2. 行业分布与应用:
- 国内市场中,电子行业是机器视觉的主要应用领域,而汽车、食品饮料等其他行业的渗透率仍有增长空间。海外市场则以汽车和电子行业为主。
- 然而,实际的工业制造环境中,由于产品种类繁多、生产线场景各异、生产周期不一,以及标准化和个性化需求的矛盾,工业AI视觉检测的落地面临挑战。缺乏统一的标准和模型定义,使得定制化的解决方案成为必要。
3. 工业化前提条件:
- 要实现工业AI视觉的广泛应用,必须克服标准缺失、场景多样性、设备技术不统一等问题。理想情况下,应有明确的需求定义、稳定的场景设置、统一的检测标准和安装方式,但现实中这些条件往往难以满足,需要通过技术创新来适应不断变化的需求。
4. 行业案例分析:
- 如金属制造业、汽车制造业、PCB制造业和消费电子等行业,每个行业的检测需求和设备技术选择都有所不同,因此,解决方案需要具备跨行业的灵活性,同时兼顾个性化需求。
总结来说,工业AI视觉检测解决方案.pptx着重于阐述了人工智能如何在工业制造中找到应用场景,面临的挑战,以及如何通过标准化和技术创新来推进其在实际生产中的落地。理解这个解决方案,企业可以更好地规划AI投入,优化生产流程,提升产品质量和效率。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
MySQL运维最佳实践:经验总结与建议
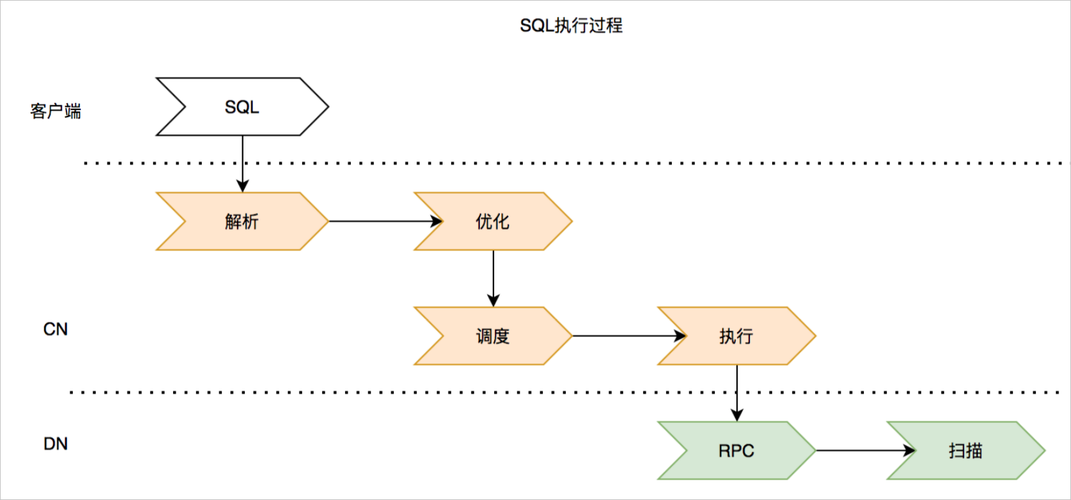
# 1. MySQL运维基础**
MySQL运维是一项复杂而重要的任务,需要深入了解数据库技术和最佳实践。本章将介绍MySQL运维的基础知识,包括:
- **MySQL架构和组件:**了解MySQL的架构和主要组件,包括服务器、客户端和存储引擎。
- **MySQL安装和配置:**涵盖MySQL的安装过
stata面板数据画图
Stata是一个统计分析软件,可以用来进行数据分析、数据可视化等工作。在Stata中,面板数据是一种特殊类型的数据,它包含了多个时间段和多个个体的数据。面板数据画图可以用来展示数据的趋势和变化,同时也可以用来比较不同个体之间的差异。
在Stata中,面板数据画图有很多种方法。以下是其中一些常见的方法
智慧医院信息化建设规划及愿景解决方案.pptx
"智慧医院信息化建设规划及愿景解决方案.pptx"
在当今信息化时代,智慧医院的建设已经成为提升医疗服务质量和效率的重要途径。本方案旨在探讨智慧医院信息化建设的背景、规划与愿景,以满足"健康中国2030"的战略目标。其中,"健康中国2030"规划纲要强调了人民健康的重要性,提出了一系列举措,如普及健康生活、优化健康服务、完善健康保障等,旨在打造以人民健康为中心的卫生与健康工作体系。
在建设背景方面,智慧医院的发展受到诸如分级诊疗制度、家庭医生签约服务、慢性病防治和远程医疗服务等政策的驱动。分级诊疗政策旨在优化医疗资源配置,提高基层医疗服务能力,通过家庭医生签约服务,确保每个家庭都能获得及时有效的医疗服务。同时,慢性病防治体系的建立和远程医疗服务的推广,有助于减少疾病发生,实现疾病的早诊早治。
在规划与愿景部分,智慧医院的信息化建设包括构建完善的电子健康档案系统、健康卡服务、远程医疗平台以及优化的分级诊疗流程。电子健康档案将记录每位居民的动态健康状况,便于医生进行个性化诊疗;健康卡则集成了各类医疗服务功能,方便患者就医;远程医疗技术可以跨越地域限制,使优质医疗资源下沉到基层;分级诊疗制度通过优化医疗结构,使得患者能在合适的层级医疗机构得到恰当的治疗。
在建设内容与预算方面,可能涉及硬件设施升级(如医疗设备智能化)、软件系统开发(如电子病历系统、预约挂号平台)、网络基础设施建设(如高速互联网接入)、数据安全与隐私保护措施、人员培训与技术支持等多个方面。预算应考虑项目周期、技术复杂性、维护成本等因素,以确保项目的可持续性和效益最大化。
此外,"互联网+医疗健康"的政策支持鼓励创新,智慧医院信息化建设还需要结合移动互联网、大数据、人工智能等先进技术,提升医疗服务的便捷性和精准度。例如,利用AI辅助诊断、物联网技术监控患者健康状态、区块链技术保障医疗数据的安全共享等。
智慧医院信息化建设是一项系统工程,需要政府、医疗机构、技术供应商和社会各方共同参与,以实现医疗服务质量的提升、医疗资源的优化配置,以及全民健康水平的提高。在2023年的背景下,这一进程将进一步加速,为我国的医疗健康事业带来深远影响。