深入剖析SQLAlchemy架构:构建高效ORM解决方案的5大策略
发布时间: 2024-10-17 16:11:16 阅读量: 41 订阅数: 48 

Python 进阶(三):Python使用ORM框架SQLAlchemy操作Oracle数据库

# 1. SQLAlchemy基础介绍
SQLAlchemy 是 Python 中的一款强大的 SQL 工具包和对象关系映射器 (ORM)。它为用户提供了一种使用 Pythonic 方式与数据库交互的方法。SQLAlchemy 旨在提供一种清晰、高级的 API,用于关系数据库的高级功能,并通过一个可扩展的架构来支持所有底层数据库引擎。
## SQLAlchemy 的核心组件
### 1.1 引擎和连接池
SQLAlchemy 的引擎(Engine)是数据库交互的核心,负责管理数据库连接,并提供了一个连接池(Connection Pool)来优化性能。引擎可以通过数据库 URL 创建,例如:
```python
from sqlalchemy import create_engine
engine = create_engine('sqlite:///example.db')
```
### 1.2 会话(Session)
会话(Session)是 ORM 的核心概念,用于管理数据库的交互。它控制着 ORM 的生命周期和事务处理。创建会话的代码如下:
```python
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session()
```
### 1.3 声明式映射(Declarative Mapping)
声明式映射允许开发者通过 Python 类的方式来定义数据库表结构,并自动处理 ORM 映射。下面是一个简单的例子:
```python
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
fullname = Column(String)
nickname = Column(String)
```
通过这些核心组件,SQLAlchemy 为开发者提供了一个高效、灵活且功能强大的数据库操作工具集。接下来的章节将深入探讨 ORM 映射机制和更多高级特性。
# 2. SQLAlchemy核心组件解析
## 2.1 ORM映射机制
### 2.1.1 模型定义与映射基础
在ORM(Object-Relational Mapping,对象关系映射)的世界里,数据模型是核心概念之一。SQLAlchemy通过声明式基类(Declarative Base)来定义模型,这使得开发者能够以面向对象的方式操作数据库。
```python
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
fullname = Column(String)
nickname = Column(String)
```
在上述代码中,我们首先导入了`declarative_base`,它是一个基类工厂,用于创建映射类。然后定义了一个`User`类,继承自`Base`。`__tablename__`属性定义了映射到数据库中的表名,而`id`、`name`、`fullname`和`nickname`则是映射到表中的列名。每个`Column`对象定义了一个属性,并且可以指定数据类型以及是否为主键等信息。
ORM模型的映射过程,本质上是在运行时动态地生成对应的表结构和类之间的关联。这意味着,开发者只需要关注Python类的定义,而不需要编写繁琐的SQL语句。
### 2.1.2 关系映射和操作
关系映射是ORM的关键特性之一,它允许我们将模型类之间的关系以对象的形式表现出来。例如,一个用户(User)可以有多个订单(Order),我们可以这样定义这种一对多的关系:
```python
from sqlalchemy.orm import relationship
class Order(Base):
__tablename__ = 'orders'
id = Column(Integer, primary_key=True)
user_id = Column(Integer, ForeignKey('users.id'))
description = Column(String)
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
orders = relationship("Order", backref="user")
```
在这个例子中,我们定义了一个`Order`类,它有一个`user_id`字段,用来表示订单所属的用户。在`User`类中,我们通过`relationship`函数定义了`orders`属性,它表示一个用户可以有多个订单。`backref`参数则在`Order`类中自动创建了一个`user`属性,用来反向引用用户。
这种关系映射使得我们可以通过属性访问关联的对象,例如:
```python
user = session.query(User).filter_by(name='John Doe').first()
for order in user.orders:
print(order.description)
```
通过这段代码,我们查询到名为'John Doe'的用户,并遍历了该用户的所有订单,打印出订单描述。这种操作在原生SQL中需要复杂的连接查询,而在ORM中则变得直观和简洁。
## 2.2 查询构建器和表达式语言
### 2.2.1 查询构建器的基本用法
SQLAlchemy的查询构建器(Query Builder)提供了一种面向对象的方式来构建和执行SQL查询。它在SQLAlchemy的会话(Session)对象中提供了一个`query`方法,可以用来构建查询对象。
```python
from sqlalchemy.orm import Session
session = Session()
query = session.query(User).filter(User.name == 'John Doe').order_by(User.id.desc())
for user in query:
print(user.id, user.name)
```
在这个例子中,我们首先创建了一个`Session`对象。通过调用`query`方法并传入`User`模型,我们得到了一个查询对象。然后通过链式调用`filter`和`order_by`方法来添加过滤条件和排序规则。最后,我们遍历查询结果,打印出用户的ID和名字。
SQLAlchemy的查询构建器隐藏了底层的SQL细节,使得开发者可以专注于逻辑层面的查询需求,而不必担心具体的SQL语法。
### 2.2.2 表达式语言详解
除了查询构建器,SQLAlchemy还提供了一套表达式语言(Expression Language),它允许开发者以编程的方式构建SQL表达式。
```python
from sqlalchemy import and_, or_
query = session.query(User).filter(and_(User.name == 'John Doe', User.fullname == 'Johnathan Doe'))
for user in query:
print(user.id, user.name)
```
在这个例子中,我们使用了`and_`函数来构建一个包含多个条件的过滤表达式。`or_`函数也可以用来构建包含逻辑或关系的表达式。这些表达式最终会被转换成对应的SQL语句执行。
SQLAlchemy的表达式语言提供了非常丰富的功能,包括但不限于比较运算、逻辑运算、算术运算等,使得开发者可以灵活地构建各种复杂的查询。
## 2.3 SQL表达式和原生SQL支持
### 2.3.1 SQL表达式树的使用
SQLAlchemy允许开发者使用SQL表达式树(SQL Expression Tree)来构建复杂的查询。表达式树由各种表达式节点组成,每个节点代表了SQL查询中的一个元素。
```python
from sqlalchemy.sql import select
stmt = select([User]).where(User.name == 'John Doe')
query = session.execute(stmt)
for user in query:
print(user.id, user.name)
```
在这个例子中,我们首先使用`select`函数创建了一个表达式树,它表示了一个选择查询。然后我们通过`where`方法添加了一个过滤条件,指定了要选择的用户名字。最后,我们通过`session.execute`方法执行了这个查询,并打印了结果。
SQLAlchemy的表达式语言构建的查询,最终会被转换成原生的SQL语句执行。这种方式在需要精确控制SQL语句的场景下非常有用。
### 2.3.2 混合使用原生SQL与ORM
在某些情况下,开发者可能需要直接使用原生SQL语句,例如执行一些特定的数据库操作或者复杂的查询。SQLAlchemy提供了灵活的接口来支持这一点。
```python
from sqlalchemy.sql import text
stmt = text("SELECT * FROM users WHERE name = 'John Doe'")
query = session.execute(stmt)
for user in query:
print(user.id, user.name)
```
在这个例子中,我们使用`text`函数创建了一个原生SQL语句,并通过`session.execute`方法执行了它。这种方式使得开发者可以在ORM的基础上,灵活地使用原生SQL语句进行操作。
总结来说,SQLAlchemy通过声明式基类、关系映射、查询构建器、表达式语言以及原生SQL支持,提供了一个强大且灵活的ORM框架。开发者可以利用这些核心组件,以面向对象的方式高效地操作数据库。
# 3. SQLAlchemy的高级特性
SQLAlchemy是一个强大的ORM工具,它不仅仅提供了基础的数据模型映射和查询功能,还包含了许多高级特性,这些特性可以帮助开发者更高效地管理和优化数据库交互。在本章节中,我们将深入探讨SQLAlchemy的高级特性,包括会话(Session)管理、高级查询技巧以及事件监听与钩子。
## 3.1 会话(Session)管理
### 3.1.1 会话的生命周期控制
在SQLAlchemy中,会话(Session)是一个非常核心的概念。它提供了一种持久化对象到数据库的方式,并且管理着对象的状态以及数据库事务。了解会话的生命周期是掌握SQLAlchemy的关键之一。
会话的生命周期通常包括以下几个阶段:
1. 创建会话:通常在应用程序启动时,通过`sessionmaker(bind=engine)`创建一个会话工厂,然后在需要时创建会话实例。
2. 提交事务:通过`***mit()`提交会话中所有挂起的事务。
3. 回滚事务:如果出现错误,可以通过`session.rollback()`回滚会话中的事务。
4. 关闭会话:在操作完成后,通过`session.close()`关闭会话实例。
在会话的生命周期中,事务的管理尤为重要。SQLAlchemy使用事务来保证数据的一致性和完整性。每个会话默认会创建一个事务,在提交或回滚时结束。开发者可以通过配置来控制事务的自动提交行为。
### 3.1.2 事务处理和隔离级别
事务处理是数据库操作的基本要素之一。在SQLAlchemy中,事务可以通过会话来管理。会话提供了一个隐式的事务上下文,在该上下文中执行的所有数据库操作都会被视为同一个事务。
SQLAlchemy支持以下几种事务隔离级别:
1. `READ UNCOMMITTED`:读未提交,最低的隔离级别,可能导致脏读、不可重复读和幻读。
2. `READ COMMITTED`:读已提交,可以防止脏读。
3. `REPEATABLE READ`:可重复读,可以防止脏读和不可重复读。
4. `SERIALIZABLE`:可串行化,最高级别的隔离,可以防止所有并发问题。
下面是一个示例代码,展示了如何在SQLAlchemy中设置事务隔离级别:
```python
from sqlalchemy import create_engine, Table, Column, Integer, String, MetaData
from sqlalchemy.orm import sessionmaker, Session
from sqlalchemy.pool import QueuePool
engine = create_engine('sqlite:///example.db', poolclass=QueuePool, pool_size=5)
Session = sessionmaker(bind=engine)
session = Session()
# 设置事务隔离级别为SERIALIZABLE
session.execute("SET TRANSACTION ISOLATION LEVEL SERIALIZABLE")
# 使用会话操作数据库
try:
# 创建表结构
metadata = MetaData()
users = Table('users', metadata,
Column('id', Integer, primary_key=True),
Column('name', String))
metadata.create_all(engine)
# 插入数据
session.execute(users.insert().values(name='Alice'))
session.execute(users.insert().values(name='Bob'))
# 提交事务
***mit()
except Exception as e:
# 回滚事务
session.rollback()
finally:
# 关闭会话
session.close()
```
在本章节中,我们介绍了SQLAlchemy中的会话(Session)管理,包括会话的生命周期控制以及事务处理和隔离级别。通过这些高级特性,开发者可以更灵活地管理数据库事务,确保数据操作的安全性和一致性。
## 3.2 高级查询技巧
### 3.2.1 多表联接和子查询
在处理复杂的数据关系时,多表联接和子查询是非常有用的工具。SQLAlchemy提供了丰富的API来支持这些高级查询操作。
#### 多表联接
SQLAlchemy的`join()`函数可以用来执行多表联接查询。它接受一个或多个表对象作为参数,并返回一个`Join`对象,该对象可以进一步用于执行查询操作。
下面是一个示例代码,展示了如何使用SQLAlchemy进行多表联接:
```python
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, join
engine = create_engine('sqlite:///example.db')
metadata = MetaData()
# 定义表结构
users = Table('users', metadata,
Column('id', Integer, primary_key=True),
Column('name', String))
posts = Table('posts', metadata,
Column('id', Integer, primary_key=True),
Column('user_id', Integer, Column('user_id')),
Column('content', String))
# 创建Join对象
user_post_join = join(users, posts, users.c.id == posts.c.user_id)
# 创建会话
session = Session(bind=engine)
# 执行查询
try:
query = session.query(users, posts).select_from(user_post_join).filter(posts.c.content.like('%SQLAlchemy%'))
result = session.execute(query).fetchall()
for row in result:
print(row.users.name, row.posts.content)
except Exception as e:
print("Error occurred:", e)
finally:
session.close()
```
#### 子查询
子查询通常用于从一个表中选择数据,该数据基于对另一个表的查询结果。SQLAlchemy提供了`select()`函数来构建子查询。
下面是一个示例代码,展示了如何使用SQLAlchemy进行子查询:
```python
from sqlalchemy import create_engine, select
engine = create_engine('sqlite:///example.db')
# 创建会话
session = Session(bind=engine)
# 创建子查询
subq = select([users.c.id]).where(users.c.name.like('%SQL%'))
# 创建主查询
query = select([posts.c.content]).where(posts.c.user_id == subq)
# 执行查询
try:
result = session.execute(query).fetchall()
for content in result:
print(content.posts.content)
except Exception as e:
print("Error occurred:", e)
finally:
session.close()
```
在本章节中,我们介绍了SQLAlchemy的高级查询技巧,包括多表联接和子查询。通过这些技巧,开发者可以更灵活地处理复杂的数据关系,执行高效的查询操作。
## 3.3 事件监听与钩子
### 3.3.1 事件监听器的配置与使用
SQLAlchemy允许开发者监听和响应SQLAlchemy内部事件,例如会话的创建、提交、回滚等。事件监听器可以用来执行自定义逻辑,例如记录日志、验证数据等。
在SQLAlchemy中,事件监听器通过装饰器来注册。下面是一个示例代码,展示了如何注册和使用事件监听器:
```python
from sqlalchemy import event
from sqlalchemy.orm import Session
from sqlalchemy.engine import Engine
# 定义一个事件监听函数
def before_insert_listener(mapper, connection, target):
print("Before insert:", target)
# 注册事件监听器
@event.listens_for(Session, "before_insert")
def before_insert(session, target):
print("Before insert:", target)
# 注册事件监听器
@event.listens_for(Engine, "before_execute", named=True)
def before_execute(session, statement, parameters, context, executemany):
print("Before execute:", statement)
# 创建会话
session = Session()
# 创建一个新对象
new_user = User(name='Alice')
# 插入数据
session.add(new_user)
***mit()
# 关闭会话
session.close()
```
在本章节中,我们介绍了SQLAlchemy的事件监听与钩子。通过这些高级特性,开发者可以更灵活地扩展SQLAlchemy的功能,执行自定义逻辑。
在本章节的介绍中,我们深入探讨了SQLAlchemy的高级特性,包括会话(Session)管理、高级查询技巧以及事件监听与钩子。这些特性可以帮助开发者更高效地管理和优化数据库交互。通过本章节的介绍,我们可以看到SQLAlchemy不仅仅是一个ORM工具,它还提供了强大的扩展性和灵活性,使得开发者可以应对各种复杂的数据库操作需求。
在接下来的章节中,我们将继续深入探讨SQLAlchemy的架构设计模式,包括代码生成器和迁移工具、插件和扩展机制以及架构模式的最佳实践。通过这些内容,我们将进一步了解SQLAlchemy的强大功能和应用场景。
# 4. SQLAlchemy架构设计模式
## 4.1 代码生成器和迁移工具
### 4.1.1 Alembic迁移工具介绍
在数据库开发过程中,版本控制和迁移是保证数据库结构一致性的关键。Alembic是一个轻量级的数据库迁移工具,专为SQLAlchemy设计,它提供了一套迁移指令,可以帮助开发者生成和管理数据库的版本控制。Alembic通过跟踪数据库模型的变更来生成迁移脚本,使得数据库可以安全地进行版本升级和降级。
**安装Alembic**
首先,我们需要安装Alembic。通过pip安装Alembic的命令如下:
```bash
pip install alembic
```
安装完成后,我们需要创建一个Alembic的配置文件,通常这个文件位于项目的顶级目录下,名为`alembic.ini`。创建该文件后,需要在文件中指定数据库的URL和Alembic脚本的位置。
**初始化Alembic**
在项目的根目录下执行以下命令,初始化Alembic:
```bash
alembic init alembic
```
这将在项目目录下创建一个`alembic`的文件夹,其中包含了一些基础的迁移脚本和配置文件。
**配置数据库URL**
编辑`alembic.ini`文件,修改`sqlalchemy.url`配置项,以连接到你的数据库。例如,如果你使用的是PostgreSQL数据库,配置项可能如下所示:
```ini
sqlalchemy.url = postgresql://user:password@localhost/mydatabase
```
**生成迁移脚本**
当我们更改了SQLAlchemy定义的模型后,我们需要生成迁移脚本来更新数据库结构。使用以下命令生成迁移脚本:
```bash
alembic revision --autogenerate -m "Initial migration"
```
这个命令会创建一个新的迁移脚本,其中包含了自动生成的变更操作,如`upgrade`和`downgrade`函数。
**应用迁移**
生成迁移脚本后,我们需要将其应用到数据库中。这可以通过以下命令完成:
```bash
alembic upgrade head
```
这个命令会将数据库迁移到最新的迁移版本。
### 4.1.2 从SQL脚本生成代码
除了使用Alembic进行版本控制外,有时候我们可能需要直接从现有的SQL脚本生成SQLAlchemy模型。这可以通过SQLAlchemy的反射机制来实现。反射是一种动态加载数据库元数据的方式,它可以让我们基于现有的数据库结构生成模型代码。
**反射数据库结构**
要使用反射机制,我们需要先导入`Table`类和`create_engine`函数,然后创建一个数据库引擎,并指定目标数据库。例如,对于PostgreSQL数据库,我们可以这样做:
```python
from sqlalchemy import Table, create_engine
# 创建数据库引擎
engine = create_engine('postgresql://user:password@localhost/mydatabase')
# 反射表结构
metadata = MetaData()
metadata.reflect(engine)
# 获取表对象
users_table = metadata.tables['users']
```
在这个例子中,我们反射了名为`users`的表,并获取了一个`Table`对象。这个对象包含了表的元数据,包括列名、数据类型等信息。
**生成模型类**
获取到表的`Table`对象后,我们可以使用`Table`对象来生成一个SQLAlchemy模型类。例如:
```python
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
Base = declarative_base()
class User(Base):
__table__ = users_table
id = Column(Integer, primary_key=True)
name = Column(String)
```
在这个例子中,我们创建了一个名为`User`的模型类,它映射了`users`表。我们通过添加属性来定义模型的字段,这些属性与`Table`对象中的列相对应。
**使用反射的注意事项**
使用反射机制时,需要注意以下几点:
- 反射机制只适用于已存在的表结构,不支持自动生成数据库不存在的表。
- 反射生成的模型类仅包含表结构信息,不包含关联关系、继承等ORM特性。
- 在生产环境中使用反射时,需要确保数据库结构的一致性和代码的安全性。
通过以上步骤,我们可以从SQL脚本生成基本的SQLAlchemy模型,这在处理遗留数据库或迁移旧项目时尤其有用。
## 4.2 插件和扩展机制
### 4.2.1 官方插件的介绍和使用
SQLAlchemy官方提供了一系列插件,这些插件可以扩展核心功能,为不同的应用场景提供支持。例如,SQLAlchemy-Utils包提供了多种工具,如类型扩展、复合主键支持等。
**安装SQLAlchemy-Utils**
首先,我们需要安装SQLAlchemy-Utils包:
```bash
pip install sqlalchemy-utils
```
安装完成后,我们可以开始使用它提供的功能。
**类型扩展**
SQLAlchemy-Utils提供了多种类型扩展,例如,`PhoneNumber`类型可以用于存储和验证电话号码:
```python
from sqlalchemy_utils import PhoneNumberType
from sqlalchemy import Column, Integer
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Contact(Base):
__tablename__ = 'contact'
id = Column(Integer, primary_key=True)
phone_number = Column(PhoneNumberType)
```
在这个例子中,我们使用了`PhoneNumberType`来定义一个电话号码字段。
**复合主键**
SQLAlchemy-Utils还支持复合主键,这意味着我们可以将多个列组合成一个主键:
```python
from sqlalchemy_utils import CompositeKey, CompositeIdx
from sqlalchemy import Column, String, Integer
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class User(Base):
__tablename__ = 'user'
first_name = Column(String)
last_name = Column(String)
email = Column(String)
__composite_key__ = CompositeKey('first_name', 'last_name')
__table_args__ = (
CompositeIdx('email', 'first_name'),
)
```
在这个例子中,我们定义了一个复合主键,由`first_name`和`last_name`组成,同时定义了一个复合索引,由`email`和`first_name`组成。
**使用官方插件的注意事项**
使用官方插件时,需要注意以下几点:
- 确保插件的版本与SQLAlchemy核心库的版本兼容。
- 阅读插件的文档,了解其提供的功能和使用方法。
- 在生产环境中使用插件前,进行充分的测试,确保其稳定性。
通过使用官方插件,我们可以扩展SQLAlchemy的功能,满足更复杂的应用需求。
### 4.2.2 开发自定义扩展
除了使用官方提供的插件外,我们还可以根据自己的需求开发自定义扩展。自定义扩展可以提供额外的功能,或者对现有功能进行定制。
**创建自定义扩展**
创建自定义扩展的第一步是定义一个类,并继承`SQLAlchemy`类:
```python
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, Column, Integer
Base = declarative_base()
class CustomSQLAlchemy(SQLAlchemy):
def __init__(self, *args, **kwargs):
super(CustomSQLAlchemy, self).__init__(*args, **kwargs)
self.custom_method()
def custom_method(self):
# 自定义方法
pass
```
在这个例子中,我们创建了一个名为`CustomSQLAlchemy`的类,它继承自`SQLAlchemy`。我们在构造函数中调用了`custom_method`方法,这是一个自定义方法。
**使用自定义扩展**
创建自定义扩展后,我们可以在应用程序中使用它:
```python
engine = create_engine('sqlite:///example.db')
db = CustomSQLAlchemy(engine)
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
name = Column(String)
```
在这个例子中,我们使用`CustomSQLAlchemy`类来创建一个数据库引擎,并定义了一个模型类。
**开发自定义扩展的注意事项**
开发自定义扩展时,需要注意以下几点:
- 确保扩展的代码清晰、可维护。
- 避免在扩展中引入不必要的复杂性。
- 对扩展进行充分的测试,确保其与核心库的兼容性。
通过开发自定义扩展,我们可以对SQLAlchemy进行定制,以适应特定的业务需求。
## 4.3 架构模式的最佳实践
### 4.3.1 分层架构的设计
在大型应用中,采用分层架构是一种常见且有效的设计模式。分层架构可以帮助我们更好地组织代码,提高代码的可维护性和可测试性。
**分层架构的概念**
分层架构通常将应用分为多个层次,每个层次负责不同的职责。常见的层次包括表示层、业务逻辑层、数据访问层等。
- 表示层:处理用户界面和用户输入。
- 业务逻辑层:实现业务规则和决策逻辑。
- 数据访问层:负责数据的持久化和访问。
**在SQLAlchemy中实现分层架构**
在SQLAlchemy中,我们可以利用其ORM特性来实现分层架构。例如:
```python
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.orm import sessionmaker, scoped_session
Base = declarative_base()
# 定义数据访问层
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
name = Column(String)
# 定义业务逻辑层
class UserManager(object):
def __init__(self, session):
self.session = session
def add_user(self, name):
user = User(name=name)
self.session.add(user)
***mit()
# 定义表示层
def main():
engine = create_engine('sqlite:///example.db')
Session = scoped_session(sessionmaker(bind=engine))
session = Session()
user_manager = UserManager(session)
user_manager.add_user('John Doe')
session.close()
if __name__ == '__main__':
main()
```
在这个例子中,我们定义了三个层次:
- 数据访问层:定义了`User`模型。
- 业务逻辑层:定义了`UserManager`类,负责添加用户。
- 表示层:定义了`main`函数,用于演示添加用户的流程。
**分层架构的优点**
使用分层架构有以下几个优点:
- **清晰的职责划分**:每个层次都有明确的职责,便于理解和维护。
- **提高代码复用性**:可以重用业务逻辑层和数据访问层的代码。
- **方便单元测试**:可以单独测试每个层次,提高测试覆盖率。
### 4.3.2 高可用架构的考量
在设计高可用的系统时,我们需要考虑多个方面,包括数据复制、负载均衡、故障转移等。
**数据复制**
为了提高数据的可用性和容错能力,我们可以使用数据复制技术。SQLAlchemy提供了一些工具来支持数据复制。
**负载均衡**
通过负载均衡,我们可以分配请求到多个服务器,提高系统的处理能力。
**故障转移**
在系统出现故障时,故障转移机制可以确保服务的连续性。
**使用SQLAlchemy实现高可用架构**
SQLAlchemy本身不提供高可用架构的实现,但它可以通过ORM的特性来支持这些架构的设计。
例如,我们可以使用多数据库连接来实现负载均衡:
```python
from sqlalchemy import create_engine
# 创建主数据库连接
engine_main = create_engine('sqlite:///main.db')
# 创建备数据库连接
engine_secondary = create_engine('sqlite:///secondary.db')
# 定义模型
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
name = Column(String)
```
在这个例子中,我们定义了两个数据库连接,分别对应主数据库和备数据库。
**高可用架构的挑战**
实现高可用架构时,我们需要考虑以下挑战:
- 数据一致性:在多个数据库之间保持数据一致性的挑战。
- 负载均衡:如何有效分配请求到不同的服务器。
- 故障转移:如何快速切换到备用服务器。
通过综合考虑这些因素,我们可以设计出既健壮又高效的高可用架构。
# 5. SQLAlchemy实践应用案例
在本章节中,我们将深入探讨SQLAlchemy在不同环境下的实践应用案例,包括Web应用、大数据环境以及云服务。这些案例不仅展示了SQLAlchemy的强大功能,也揭示了它如何适应不同的应用场景,从而帮助开发者构建高效、可扩展的应用程序。
## 5.1 Web应用中的ORM实践
SQLAlchemy作为Python中最流行的ORM工具之一,在Web开发中有着广泛的应用。它不仅能够简化数据库操作,还能够帮助开发者更好地组织和维护代码。
### 5.1.1 Flask与SQLAlchemy的整合
Flask是一个轻量级的Web框架,它简洁、灵活,非常适合快速开发小型项目。结合SQLAlchemy,可以更加方便地管理数据库模型和会话。以下是Flask与SQLAlchemy整合的基本步骤:
1. 安装Flask和SQLAlchemy库:
```bash
pip install Flask
pip install Flask-SQLAlchemy
```
2. 创建一个简单的Flask应用,并配置SQLAlchemy:
```python
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///example.db'
db = SQLAlchemy(app)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True, nullable=False)
email = db.Column(db.String(120), unique=True, nullable=False)
@app.route('/')
def index():
users = User.query.all()
return 'List of users: {}'.format([user.username for user in users])
if __name__ == '__main__':
db.create_all()
app.run(debug=True)
```
3. 创建数据库模型并进行操作:
在上述代码中,我们定义了一个`User`模型,并在`index`视图函数中查询所有用户。
### 5.1.2 Django与SQLAlchemy的对比分析
Django是一个全栈的Web框架,它自带了一个名为Django ORM的ORM工具。虽然Django ORM非常强大,但在某些场景下,SQLAlchemy提供了更多的灵活性和控制力。以下是Django ORM与SQLAlchemy的一些对比点:
| 特性 | Django ORM | SQLAlchemy |
| --- | --- | --- |
| 数据库抽象 | 高度抽象,自动处理很多细节 | 更多控制,可以精细调整SQL语句 |
| 移植性 | 只能在Django项目中使用 | 可以在任何Python项目中使用 |
| 性能 | 优化良好,但在复杂查询时可能受限 | 可以优化性能,特别是在复杂查询时 |
| 社区支持 | 强大的社区支持,大量文档和教程 | 社区支持也很强大,但可能在Web应用方面的资源较少 |
在本章节介绍中,我们通过对比分析,展示了SQLAlchemy在某些特定场景下的优势。它不仅适用于Django项目,还能够在其他类型的Python项目中提供强大的数据库操作能力。
## 5.2 大数据环境下的应用
随着数据量的增长,传统的数据库操作可能会变得非常缓慢。SQLAlchemy提供了处理大规模数据集的策略,使得开发者能够有效地管理和分析数据。
### 5.2.1 处理大规模数据集的策略
SQLAlchemy提供了多种策略来处理大规模数据集,包括分批处理、使用批处理API以及利用SQLAlchemy Core进行底层SQL操作。
#### 分批处理
分批处理是一种常见的策略,通过逐批次读取数据,可以有效地减少内存的使用,并提高处理速度。
```python
from sqlalchemy import create_engine, Table, MetaData
engine = create_engine('sqlite:///example.db')
metadata = MetaData(bind=engine)
users = Table('users', metadata, autoload=True)
batch_size = 1000
offset = 0
while True:
session = Session(engine)
results = session.query(users).offset(offset).limit(batch_size).all()
if not results:
break
for user in results:
# 处理每个用户的数据
offset += batch_size
```
#### 使用批处理API
SQLAlchemy的`BatchProcessing` API可以进一步优化批量插入操作。
```python
from sqlalchemy import create_engine
from sqlalchemy.sql import insert
engine = create_engine('sqlite:///example.db')
insert_stmt = insert(users).values(name='New User')
with engine.connect() as conn:
batch_size = 100
batch = conn.begin()
conn.exec_driver_sql(insert_stmt)
***mit()
```
在本章节中,我们介绍了SQLAlchemy处理大规模数据集的几种策略,并提供了相应的代码示例。这些策略可以帮助开发者在大数据环境下高效地操作数据。
## 5.3 云服务与SQLAlchemy
云计算平台为数据库服务提供了新的可能性。SQLAlchemy不仅可以在传统环境中使用,还可以在云服务中发挥作用。
### 5.3.1 云计算平台的数据库服务
云计算平台如Amazon RDS、Google Cloud SQL等提供了托管的数据库服务。这些服务通常会提供多种数据库引擎,SQLAlchemy可以无缝地与这些服务进行整合。
```python
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://user:password@host/db_name')
```
在上述代码中,我们创建了一个连接到RDS MySQL数据库的引擎。SQLAlchemy抽象了数据库的细节,使得开发者可以专注于业务逻辑。
### 5.3.2 SQLAlchmey在云原生环境中的应用
云原生环境中,应用程序通常需要快速启动和停止,并且具有弹性。SQLAlchemy可以支持这些特性,使得应用程序能够在云环境中高效运行。
```python
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
Session = sessionmaker(bind=create_engine('sqlite:///example.db'))
Base.metadata.create_all(engine)
```
在上述代码中,我们展示了如何使用SQLAlchemy在云环境中创建和管理数据库模型。由于SQLAlchemy的灵活性,它非常适合在云环境中使用。
在本章节中,我们探讨了SQLAlchemy在云服务中的应用,包括与云计算平台的数据库服务的整合,以及在云原生环境中的使用。这些讨论展示了SQLAlchemy在现代云环境中的应用潜力。
通过本章节的介绍,我们展示了SQLAlchemy在不同应用场景中的实践案例,包括Web应用、大数据环境以及云服务。这些案例不仅体现了SQLAlchemy的灵活性和强大功能,也为开发者提供了宝贵的经验和参考。
# 6. 性能优化与常见问题解决
## 6.1 性能优化策略
在使用SQLAlchemy进行数据库操作时,性能优化是一个不可忽视的环节。合理的优化策略不仅可以提高查询效率,还能减少系统资源的消耗。
### 6.1.1 查询优化和索引构建
查询优化通常是性能优化的首要步骤。在SQLAlchemy中,可以通过分析查询语句和数据库的执行计划来找出潜在的性能瓶颈。索引的合理使用是查询优化的关键。例如,如果一个字段经常用于WHERE子句的条件过滤,那么为该字段创建索引可以显著提高查询速度。
```python
from sqlalchemy import create_engine, Column, Integer, String, Index
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
fullname = Column(String)
nickname = Column(String)
# 创建索引
__table_args__ = (
Index('idx_user_fullname', fullname),
)
engine = create_engine('sqlite:///test.db')
Session = sessionmaker(bind=engine)
session = Session()
```
在这个例子中,`fullname`字段被添加了一个索引,这将有助于提高包含该字段过滤条件的查询性能。
### 6.1.2 异步编程与性能提升
异步编程是另一种提升性能的手段,尤其是在I/O密集型的应用中。SQLAlchemy支持通过Twisted和asyncio等库实现异步数据库访问。以下是一个使用SQLAlchemy结合asyncio的简单示例:
```python
import asyncio
from sqlalchemy.ext.asyncio import create_async_engine, AsyncSession
from sqlalchemy.orm import sessionmaker
engine = create_async_engine('sqlite+aiosqlite:///async_test.db')
AsyncSessionLocal = sessionmaker(
bind=engine, expire_on_commit=False, class_=AsyncSession
)
async def create_db_and_tables():
async with engine.begin() as conn:
await conn.run_sync(Base.metadata.drop_all)
await conn.run_sync(Base.metadata.create_all)
async def async_main():
await create_db_and_tables()
async with AsyncSessionLocal() as session:
# 异步操作数据库
pass
asyncio.run(async_main())
```
通过这种方式,SQLAlchemy可以在异步环境中高效地执行数据库操作,从而提升整体性能。
## 6.2 常见问题诊断与解决
在使用SQLAlchemy的过程中,开发者可能会遇到各种错误和异常。正确地诊断和解决问题是保证应用稳定运行的关键。
### 6.2.1 常见错误和异常处理
SQLAlchemy在运行时可能会抛出多种异常。例如,如果尝试访问一个不存在的数据库表,将会抛出`sqlalchemy.exc.NoSuchTableError`。处理这些异常的基本方法是使用`try...except`语句块:
```python
from sqlalchemy.exc import NoSuchTableError
try:
# 尝试查询不存在的表
session.query(SomeNonExistentTable).all()
except NoSuchTableError as e:
print(f"Table does not exist: {e}")
```
通过捕获和处理这些异常,开发者可以更好地控制应用的错误处理流程,并提供更加友好的用户反馈。
### 6.2.2 调试技巧和性能瓶颈分析
性能瓶颈分析通常需要结合日志记录和分析工具来进行。SQLAlchemy提供了丰富的事件监听和日志记录机制,可以帮助开发者追踪性能问题的根源。
```python
import logging
from sqlalchemy import event
# 设置日志记录
logging.basicConfig(level=***)
logger = logging.getLogger(__name__)
# 日志事件监听器
@event.listens_for(Base, "column_info")
def receive_column_info(target, column_info):
***(f"Column Info: {column_info}")
# 定义模型
class Example(Base):
__tablename__ = 'example'
id = Column(Integer, primary_key=True)
name = Column(String)
# 创建引擎
engine = create_engine('sqlite:///test.db')
Base.metadata.create_all(engine)
```
在这个例子中,我们设置了一个事件监听器来记录列信息的日志,这有助于在开发过程中进行调试。
## 6.3 维护和测试
数据库的维护和测试是确保应用长期稳定运行的重要环节。SQLAlchemy提供了多种工具和方法来支持这些任务。
### 6.3.1 数据库迁移和维护计划
数据库迁移通常涉及到数据结构的变更,SQLAlchemy通过Alembic这样的工具来支持数据库迁移。
```python
from alembic import command
from alembic.config import Config
# 设置Alembic配置
alembic_cfg = Config('alembic.ini')
# 运行迁移命令
command.upgrade(alembic_cfg, "head")
```
在这个例子中,我们使用Alembic的`upgrade`命令来更新数据库架构。
### 6.3.* 单元测试和代码覆盖率
单元测试是确保代码质量的关键。SQLAlchemy与pytest等测试框架配合使用,可以有效地进行单元测试。
```python
import pytest
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
engine = create_engine('sqlite:///:memory:')
Base.metadata.create_all(engine)
# 测试查询
@pytest.mark.parametrize("name", ["Alice", "Bob"])
def test_user_query(session, name):
new_user = User(name=name)
session.add(new_user)
***mit()
assert session.query(User).filter(User.name == name).first() is not None
```
在这个例子中,我们使用pytest框架来编写一个简单的单元测试,确保`User`模型的查询功能正常工作。
以上章节介绍了SQLAlchemy在性能优化和常见问题解决方面的策略和技巧,以及如何通过维护和测试来确保数据库的稳定性和应用的质量。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“SQLAlchemy 库文件学习”专栏,我们将深入探索这个强大的 Python ORM 库。从入门到精通,我们提供实用技巧和策略,帮助您构建高效的 ORM 解决方案。深入了解 SQLAlchemy 架构、插件开发、异常管理、事务管理、多数据库支持、会话管理和查询构建。此外,我们还探讨了 SQLAlchemy 与数据库元数据的交互、与其他 ORM 的比较、在 Web 应用中的应用、缓存机制、连接池管理、与 Django ORM 的集成、自定义 SQL 表达式以及与 PostgreSQL 特有功能的集成。通过本专栏,您将掌握 SQLAlchemy 的各个方面,并将其应用到您的项目中,以创建可靠、高效和可扩展的数据库解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
紧急揭秘!防止Canvas转换中透明区域变色的5大技巧

# 摘要
Canvas作为Web图形API,广泛应用于现代网页设计与交互中。本文从Canvas转换技术的基本概念入手,深入探讨了在渲染过程中透明区域变色的理论基础和实践解决方案。文章详细解析了透明度和颜色模型,渲染流程以及浏览器渲染差异,并针对性地提供了预防透明区域变色的技巧。通过对Canvas上下文优化
超越MFCC:BFCC在声学特征提取中的崛起

# 摘要
声学特征提取是语音和音频处理领域的核心,对于提升识别准确率和系统的鲁棒性至关重要。本文首先介绍了声学特征提取的原理及应用,着重探讨
Flutter自定义验证码输入框实战:提升用户体验的开发与优化

# 摘要
本文详细介绍了在Flutter框架中实现验证码输入框的设计与开发流程。首先,文章探讨了验证码输入框在移动应用中的基本实现,随后深入到前端设计理论,强调了用户体验的重
光盘刻录软件大PK:10个最佳工具,找到你的专属刻录伙伴
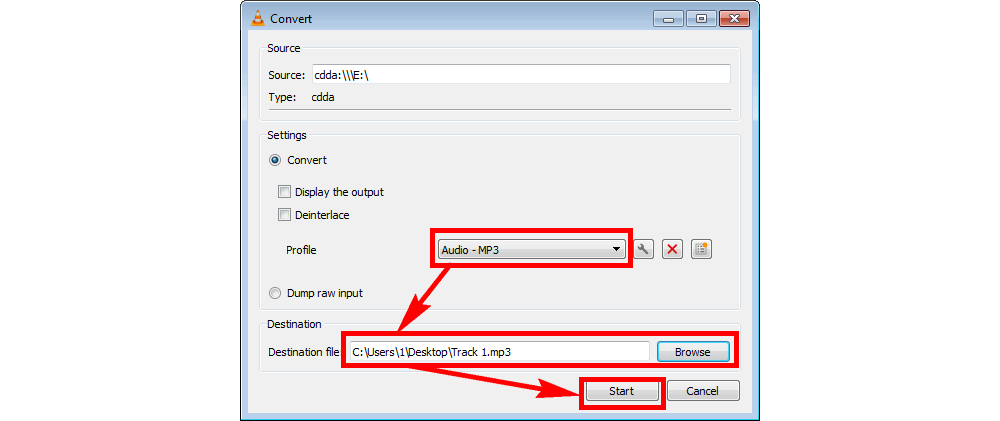
# 摘要
本文全面介绍了光盘刻录技术,从技术概述到具体软件选择标准,再到实战对比和进阶优化技巧,最终探讨了在不同应用场景下的应用以及未来发展趋势。在选择光盘刻录软件时,本文强调了功能性、用户体验、性能与稳定性的重要性。此外,本文还提供了光盘刻录的速度优化、数据安全保护及刻录后验证的方法,并探讨了在音频光盘制作、数据备份归档以及多媒体项目中的应用实例。最后,文章展望了光盘刻录技术的创
【FANUC机器人接线实战教程】:一步步教你完成Process IO接线的全过程
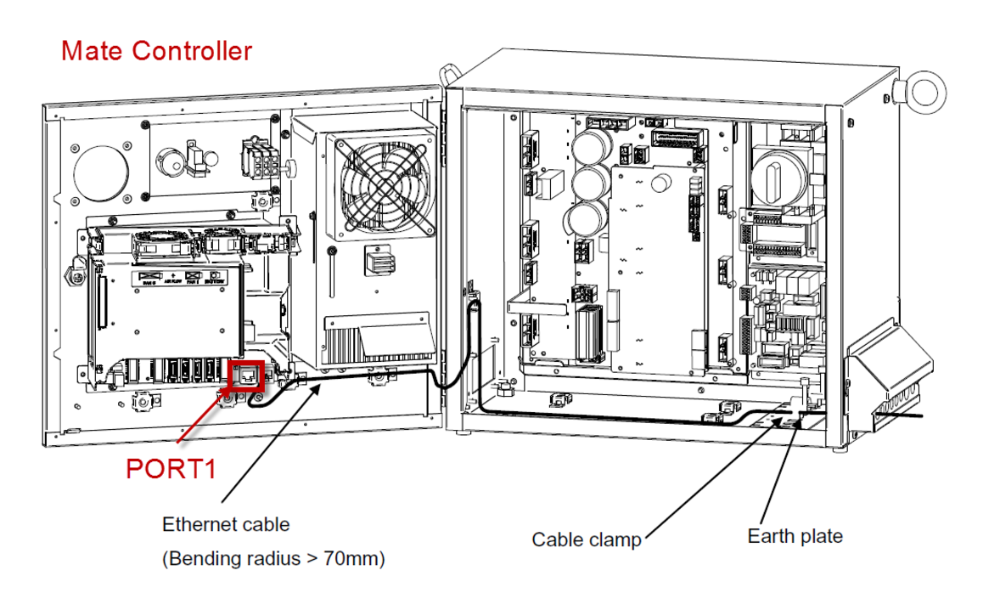
# 摘要
本文系统地介绍了FANUC机器人接线的基础知识、操作指南以及故障诊断与解决策略。首先,章节一和章节二深入讲解了Process IO接线原理,包括其优势、硬件组成、电气接线基础和信号类型。随后,在第三章中,提供了详细的接线操作指南,从准备工作到实际操作步骤,再到安全操作规程与测试,内容全面而细致。第四章则聚焦于故障诊断与解决,提供了一系列常见问题的分析、故障排查步骤与技巧,以及维护和预防措施
ENVI高光谱分析入门:3步掌握波谱识别的关键技巧

# 摘要
本文全面介绍了ENVI高光谱分析软件的基础操作和高级功能应用。第一章对ENVI软件进行了简介,第二章详细讲解了ENVI用户界面、数据导入预处理、图像显示与分析基础。第三章讨论了波谱识别的关键步骤,包括波谱特征提取、监督与非监督分类以及分类结果的评估与优化。第四章探讨了高级波谱分析技术、大数据环境下的高光谱处理以及ENVI脚本
ISA88.01批量控制核心指南:掌握制造业自动化控制的7大关键点

# 摘要
本文详细介绍了ISA88.01批量控制标准的理论基础和实际应用。首先,概述了ISA88.01标准的结构与组件,包括基本架构、核心组件如过程模块(PM)、单元模块(UM)
【均匀线阵方向图优化手册】:提升天线性能的15个实战技巧
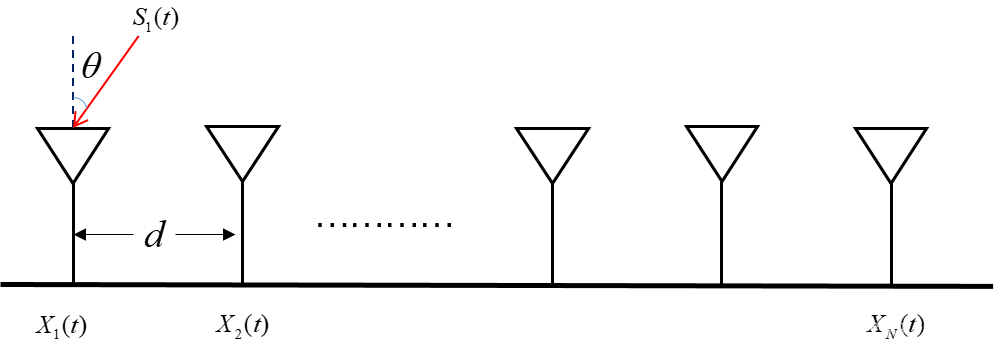
# 摘要
本文系统地介绍了均匀线阵天线的基础知识、方向图优化理论基础、优化实践技巧、系统集成与测试流程,以及创新应用。文章首先概述了均匀线阵天线的基本概念和方向图的重要性,然后
STM32F407 USB通信全解:USB设备开发与调试的捷径

# 摘要
本论文深入探讨了STM32F407微控制器在USB通信领域的应用,涵盖了从基础理论到高级应用的全方位知识体系。文章首先对USB通信协议进行了详细解析,并针对STM32F407的USB硬件接口特性进行了介绍。随后,详细阐述了USB设备固件开发流程和数据流管理,以及USB通信接口编程的具体实现。进一步地,针对USB调试技术和故障诊断、性能优化进行了系统性分析。在高级应用部分,重点介绍了USB主
车载网络诊断新趋势:SAE-J1939-73在现代汽车中的应用
# 摘要
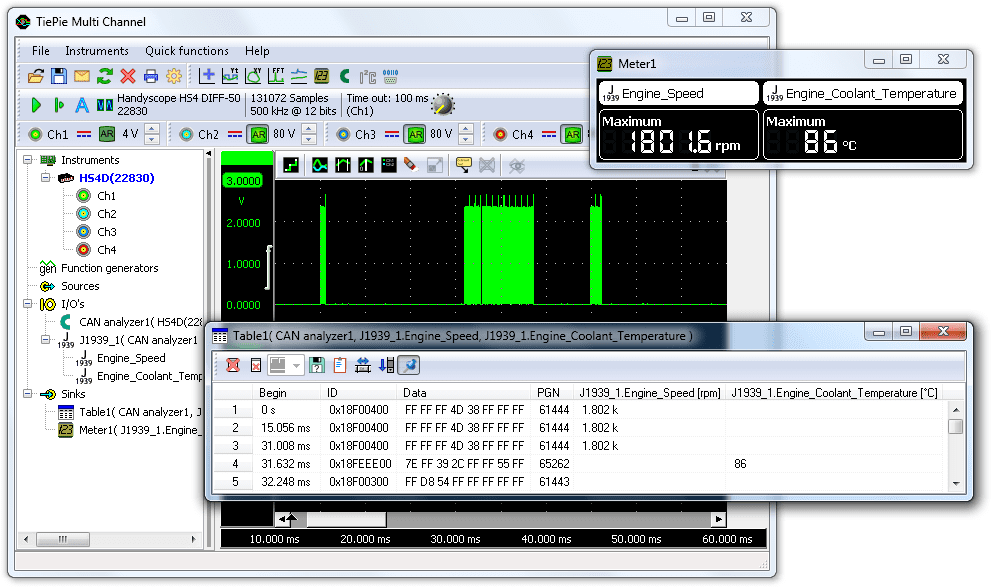
随着汽车电子技术的发展,车载网络诊断技术变得日益重要。本文首先概述了车载网络技术的演进和SAE-J1939标准及其子标准SAE-J1939-73的角色。接着深入探讨了SAE-J1939-73标准的理论基础,包括数据链路层扩展、数据结构、传输机制及诊断功能。文章分析了SAE-J1939-73在现代汽车诊断中的实际应用,车载网络诊断工具和设备,以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )