合并小文件的艺术:自定义InputFormat优化MapReduce作业
发布时间: 2024-10-31 08:12:30 阅读量: 6 订阅数: 11 
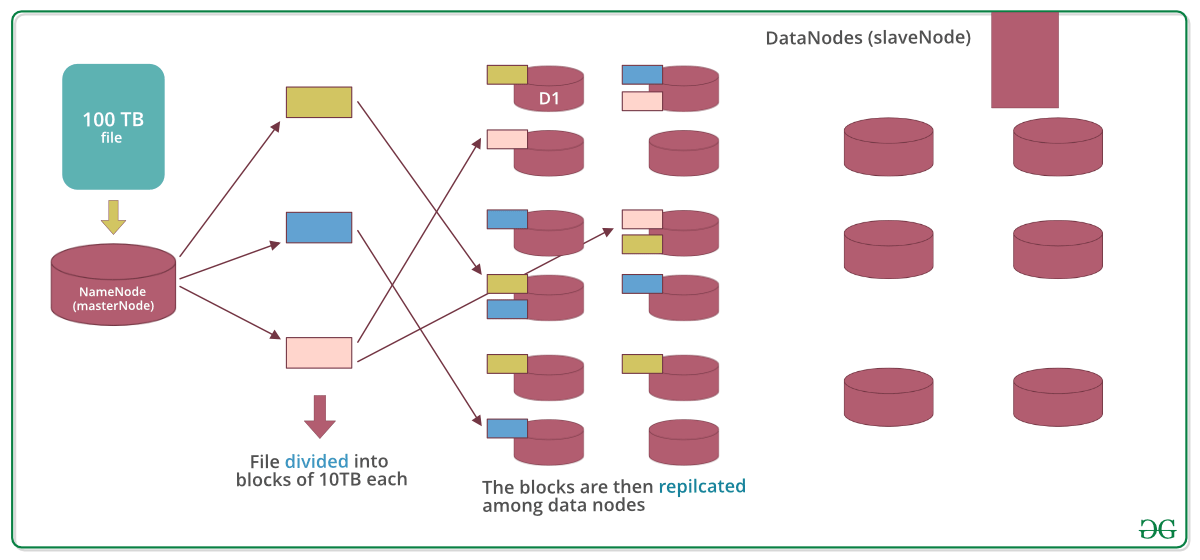
# 1. MapReduce概述与小文件问题
MapReduce是Hadoop的核心组件之一,主要用于处理大规模数据集的并行运算。随着技术的发展,大数据分析需求日益增长,MapReduce成为了大数据处理的重要工具。然而,在进行大规模数据分析时,小文件问题逐渐显现出对性能的负面影响。本章将对MapReduce进行概述,并着重分析小文件问题,讨论其对MapReduce性能的具体影响,为后续章节中自定义InputFormat的讨论打下理论基础。
小文件问题是指在处理数据时,文件数量过多且文件体积过小,导致在文件系统中进行文件管理时消耗过多的资源,从而影响系统的整体性能。MapReduce在处理这些小文件时,会遇到任务调度缓慢、数据读写频繁且开销大、内存资源浪费等问题。因此,理解小文件对MapReduce性能的影响及其优化方法变得尤为重要。
接下来的章节会探讨如何通过自定义InputFormat来解决小文件问题,并分析优化后的性能提升,为IT行业提供解决方案。
# 2. 自定义InputFormat理论基础
## 2.1 MapReduce输入流程解析
### 2.1.1 输入数据的读取机制
在MapReduce的执行过程中,输入数据的读取机制是整个数据处理流程的起始点。首先,需要了解MapReduce如何定位和读取输入文件中的数据。Hadoop框架默认使用`FileSystem`的API来访问HDFS上的文件,它利用本地文件系统或者Hadoop分布式文件系统(HDFS)来获取需要处理的数据块。
在读取输入数据时,MapReduce框架将每个文件分割成多个"输入分片"(InputSplit),这些分片被分发给Map任务进行处理。每个InputSplit的大小由`mapreduce.input.fileinputformat.split.minsize`参数决定,这个参数定义了最小的分片大小。当输入文件的大小小于这个值时,整个文件会被作为一个单独的InputSplit处理。
理解输入数据的读取机制对于后续的自定义InputFormat设计至关重要。因为在处理小文件时,如果没有适当的策略去合并这些分片,将会导致大量的Map任务并行启动,这对于资源管理和处理性能都是一个挑战。
### 2.1.2 默认InputFormat的工作原理
默认的InputFormat在Hadoop中实现为`FileInputFormat`,它是所有其他InputFormat类的基类。这个类使用`FileSystem`的`listStatus()`方法来获取输入目录下所有的文件,将它们转换为InputSplit。默认情况下,每个文件会被封装成一个单独的InputSplit,除非文件很大而被进一步切分成更小的分片。
在Map任务开始处理数据之前,`RecordReader`对象负责读取InputSplit中的数据,并将数据转换成键值对(key-value pairs)供Mapper使用。默认情况下,`RecordReader`是`LineRecordReader`,它以行为单位读取数据,键是文件中数据的位置偏移量,值是行的内容。
了解默认InputFormat的工作原理对于深入自定义InputFormat有重大意义。自定义的InputFormat不仅需要继承`FileInputFormat`类,还需要覆盖默认的`getSplits`方法和`createRecordReader`方法,以实现更灵活的分片和读取机制。
## 2.2 自定义InputFormat的重要性
### 2.2.1 小文件问题对MapReduce性能的影响
小文件问题通常是指在Hadoop集群中存在大量的小文件,这些文件在处理时会导致显著的性能下降。小文件问题的根源在于每个小文件都会生成一个单独的InputSplit,并为每个分片启动一个Map任务。这意味着如果存在大量小文件,将导致Map任务数量急剧增加,从而引起Map任务调度延迟、资源竞争加剧以及任务执行效率下降。
小文件还会导致更多的数据被写入到磁盘,因为每个小文件的处理往往不会填满数据块的大小,导致数据的随机访问更加频繁。在MapReduce中,频繁的磁盘读写操作将对性能造成极大压力。此外,由于NameNode的内存资源是有限的,大量的小文件会消耗NameNode的内存,影响集群的整体稳定性。
### 2.2.2 InputFormat自定义的可行性分析
为了解决小文件问题对MapReduce性能的影响,可以考虑通过自定义InputFormat来优化数据的输入流程。自定义InputFormat类可以设计更合理的分片策略,实现对小文件的合并,减少Map任务的数量,以及优化数据读取逻辑,从而提升整个作业的处理效率。
自定义InputFormat的可行性分析可以从以下几个方面进行:
- **合并小文件**:通过自定义InputFormat将多个小文件合并成一个较大的InputSplit,可以减少Map任务的数量。
- **分片策略的优化**:可以设计分片策略,使得单个Map任务能够处理更多的数据,减少任务调度开销。
- **提高读取效率**:通过自定义`RecordReader`,可以优化数据读取的性能,比如减少序列化和反序列化的开销,减少数据复制。
此外,自定义InputFormat需要考虑的不仅仅是功能实现,还包括如何与现有的Hadoop生态系统无缝集成,保证作业的稳定性和可靠性。在实际使用中,还要考虑自定义InputFormat在不同版本的Hadoop环境下的兼容性问题。
通过上述分析,自定义InputFormat不仅理论上可行,而且在实践中也具有重大的应用价值。自定义InputFormat是解决小文件问题的有效手段之一,对于优化MapReduce作业性能有着重要作用。
下一章节,我们将详细介绍如何设计和实现自定义InputFormat类,以及如何通过它来合并小文件,优化MapReduce的输入流程。
# 3. 自定义InputFormat的设计与实现
## 3.1 设计自定义InputFormat类
### 3.1.1 继承InputFormat类的基本结构
设计自定义的InputFormat类是解决小文件问题的关键步骤之一。基本结构需要继承自Hadoop的`InputFormat`抽象类,并且定义具体的输入文件分片方式和如何读取数据。
```java
public class MyInputFormat extends InputFormat<LongWritable, Text> {
@Override
public List<InputSplit> getSplits(JobContext context) throws IOException, InterruptedException {
// 实现分片逻辑
}
@Override
public RecordReader<LongWritable, Text> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
// 实现RecordReader逻辑
}
}
```
在上述代码中,`getSplits`方法用于定义如何将输入数据分割成多个`InputSplit`,而`createRecordReader`方法则定义了如何从每个`InputSplit`中读取数据。
### 3.1.2 文件分片策略的设计
文件分片策略的设计需要考虑文件的大小、数量以及数据分布等因素。例如,可以设计一个简单的分片策略,将小文件直接作为单独的分片,而对于大文件则采用固定大小的分片策略。
```java
public List<InputSplit> getSplits(JobContext job) throws IOException, InterruptedException {
Configuration conf = job.getConfiguration();
long minSize = conf.getLong("mapreduce.input.fileinputformat.split.minsize", 1);
long maxSize = conf.getLong("mapreduce.input.fileinputformat.split.maxsize", Long.MAX_VALUE);
// 获取输入目录
Path path = ...;
FileStatus[] statuses = ...;
List<InputSplit> splits = new ArrayList<InputSplit>();
for (FileStatus status : statuses) {
// 对于大文件,进行固定大小分片
if (status.getPath().getName().endsWith(".large")) {
long length = status
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏深入探讨了 MapReduce 中小文件带来的挑战和优化策略。它从为什么避免小文件开始,分析了小文件对性能的影响,并提供了避免它们的实用建议。专栏还深入研究了处理小文件的技术,包括合并技术、压缩技术、自定义输入格式和输出格式。此外,它还讨论了数据本地化、系统性解决方案、工具选择、资源管理和参数调优等优化策略。通过案例研究和最佳实践,该专栏为优化 MapReduce 作业以处理小文件提供了全面的指南,帮助读者提高集群性能并避免小文件带来的负面影响。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【大数据精细化管理】:掌握ReduceTask与分区数量的精准调优技巧

# 1. 大数据精细化管理概述
在当今的信息时代,企业与组织面临着数据量激增的挑战,这要求我们对大数据进行精细化管理。大数据精细化管理不仅关系到数据的存储、处理和分析的效率,还直接关联到数据价值的最大化。本章节将概述大数据精细化管理的概念、重要性及其在业务中的应用。
大数据精细化管理涵盖从数据
【数据仓库Join优化】:构建高效数据处理流程的策略

# 1. 数据仓库Join操作的基础理解
## 数据库中的Join操作简介
在数据仓库中,Join操作是连接不同表之间数据的核心机制。它允许我们根据特定的字段,合并两个或多个表中的数据,为数据分析和决策支持提供整合后的视图。Join的类型决定了数据如何组合,常用的SQL Join类型包括INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN等。
## SQL Joi
MapReduce自定义分区:规避陷阱与错误的终极指导

# 1. MapReduce自定义分区的理论基础
MapReduce作为一种广泛应用于大数据处理的编程模型,其核心思想在于将计算任务拆分为Map(映射)和Reduce(归约)两个阶段。在MapReduce中,数据通过键值对(Key-Value Pair)的方式被处理,分区器(Partitioner)的角色是决定哪些键值对应该发送到哪一个Reducer。这种机制至关
MapReduce与大数据:挑战PB级别数据的处理策略
# 1. MapReduce简介与大数据背景
## 1.1 大数据的定义与特性
大数据(Big Data)是指传统数据处理应用软件难以处
【分片大小的艺术】:算法、公式及计算详解

# 1. 分片大小概念概述
在大数据处理和存储领域,分片(Sharding)是将数据分散存储在多个物理节点上的一种技术。分片大小是分片策略中一个关键参数,它决定了每个分片的数据量大小,直接影响系统性能、可扩展性及数据管理的复杂度。合理设置分片大小能够提高查询效率,优化存储使用,并且对于维护高性能和可伸缩性至关重要。接下来章节将对分片算法的理论基
跨集群数据Shuffle:MapReduce Shuffle实现高效数据流动

# 1. MapReduce Shuffle基础概念解析
## 1.1 Shuffle的定义与目的
MapReduce Shuffle是Hadoop框架中的关键过程,用于在Map和Reduce任务之间传递数据。它确保每个Reduce任务可以收到其处理所需的正确数据片段。Shuffle过程主要涉及数据的排序、分组和转移,目的是保证数据的有序性和局部性,以便于后续处理。
MapReduce小文件处理:数据预处理与批处理的最佳实践

# 1. MapReduce小文件处理概述
## 1.1 MapReduce小文件问题的普遍性
在大规模数据处理领域,MapReduce小文件问题普遍存在,严重影响
项目中的Map Join策略选择
# 1. Map Join策略概述
Map Join策略是现代大数据处理和数据仓库设计中经常使用的一种技术,用于提高Join操作的效率。它主要依赖于MapReduce模型,特别是当一个较小的数据集需要与一个较大的数据集进行Join时。本章将介绍Map Join策略的基本概念,以及它在数据处理中的重要性。
Map Join背后的核心思想是预先将小数据集加载到每个Map任
MapReduce中的Combiner与Reducer选择策略:如何判断何时使用Combiner

# 1. MapReduce框架基础
MapReduce 是一种编程模型,用于处理大规模数据集
【MapReduce数据处理】:掌握Reduce阶段的缓存机制与内存管理技巧

# 1. MapReduce数据处理概述
MapReduce是一种编程模型,旨在简化大规模数据集的并行运算。其核心思想是将复杂的数据处理过程分解为两个阶段:Map(映射)阶段和Reduce(归约)阶段。Map阶段负责处理输入数据,生成键值对集合;Reduce阶段则对这些键值对进行合并处理。这一模型在处理大量数据时,通过分布式计算,极大地提
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )