XPath绝对路径与相对路径区别与应用
发布时间: 2024-03-09 17:39:01 阅读量: 253 订阅数: 21 
# 1. XPath 简介和基本概念
XPath是一种用于在XML文档中定位节点的语言,它可以在XML和HTML文档中对元素和属性进行遍历和筛选。XPath通过路径表达式在文档中选取节点,这些路径表达式类似于文件系统中的路径。XPath可以用于定位文档中的任何节点,例如元素、属性、文本等,从而方便地进行数据提取、解析和处理。
## 1.1 XPath 的定义和作用
XPath是XML Path Language的缩写,是一门在XML文档中查找信息的语言。通过使用路径表达式,我们可以在XML文档中准确定位元素和属性。
## 1.2 XPath 绝对路径和相对路径的概念
XPath中的路径可以分为绝对路径和相对路径。绝对路径以斜杠(/)开头,从根节点开始进行查找;而相对路径则是相对于当前节点的路径。两者的用法不同,各有优劣。
## 1.3 XPath 在XML 和 HTML 中的应用
除了用于XML文档,XPath同样适用于HTML文档。在HTML中,XPath可以用于定位网页中的元素,结合网页数据抓取等操作,极大地拓展了XPath的应用范围。
# 2. XPath 绝对路径详解
XPath 绝对路径是指从文档的根节点开始的路径表达式。在XPath中,绝对路径始终以斜杠 `/` 开头。下面我们将深入探讨XPath绝对路径的语法、示例和在大型文档中的应用案例。
#### 2.1 绝对路径的语法和示例
XPath 绝对路径的语法非常简单,它总是以斜杠 `/` 开头,后面跟着节点的名称。例如,`/bookstore/book/title` 表示从根节点开始,选择所有 `bookstore` 节点下的 `book` 节点,再选择这些 `book` 节点下的 `title` 节点。
让我们以以下XML文档为例进行演示:
```xml
<bookstore>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="web">
<title lang="en">Learning XPath</title>
<author>John Smith</author>
</book>
</bookstore>
```
如果我们要使用绝对路径来选择第一本书的标题,可以使用以下XPath表达式:`/bookstore/book[1]/title`。这将选择根节点下的 `bookstore`,再选择其下的第一个 `book`,最后选择这个 `book` 的 `title`。
#### 2.2 绝对路径的优缺点分析
绝对路径的优点是清晰明了,易于理解和编写。它从根节点开始,路径表达明确,能够准确地定位到目标节点。
然而,绝对路径的缺点是当文档结构发生变化时,路径可能会失效。因为它对节点位置的依赖性较强,如果节点发生了插入、删除或顺序改变,绝对路径就需要相应地调整。
#### 2.3 绝对路径在大型文档中的应用案例
在处理大型XML文档时,绝对路径可以帮助精确定位到目标节点,特别是当文档结构相对稳定,很少发生变化时。它的路径表达清晰,适合用于静态且层次结构固定的文档中。
绝对路径的应用场景包括企业级数据交换、文档处理系统以及对静态文档进行结构化数据提取等领域。在这些场景下,文档结构相对固定,使用绝对路径能够准确地获取所需的数据。
# 3. XPath 相对路径详解
在XPath中,相对路径是相对于当前节点的路径,通常使用来定位当前节点的子节点、兄弟节点或父节点。相对路径是XPath中常用的定位方式,因为它更为灵活、简洁,并且具有良好的可维护性。以下将详细介绍XPath相对路径的语法、示例以及其在查找层级结构复杂的文档中的应用案例。
#### 3.1 相对路径的语法和示例
XPath相对路径以"./"开头表示从当前节点开始查找子节点,以"../"表示查找父节点,以"//"表示跨越多层级查找节点。以下是一些常见的相对路径语法示例:
```python
# Python 示例代码
from lxml import etree
# 创建 XML 文档
xml = """
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J.K. Rowling</author>
</book>
</bookstore>
# 解析 XML
root = etree.fromstring(xml)
# 使用相对路径查找子节点
titles = root.xpath('./book/title/text()')
for title in titles:
print(title)
```
#### 3.2 相对路径的优缺点分析
相对路径相较于绝对路径来说,更具灵活性和可读性。相对路径更适合于针对文档中特定上下文节点的查找,当文档结构发生变化时,相对路径的调整相对简单。但是相对路径可能无法精确定位某些节点,尤其是当文档结构比较复杂或存在多个相同节点名称时,需要慎重编写相对路径。
#### 3.3 相对路径在查找层级结构复杂的文档中的应用案例
假设我们需要在一个包含多层级结构的XML文档中查找所有书籍的作者信息,可以通过相对路径来实现:
```python
# 继续 Python 示例代码
# 使用相对路径查找父节点
authors = root.xpath('//book/author/text()')
for author in authors:
print(author)
```
在这个案例中,相对路径"//book/author/text()"可以跨越多个层级直接查找所有书籍的作者信息,展示了相对路径在查找层级复杂文档中的应用。
通过学习相对路径的语法、优缺点以及应用案例,我们可以更好地理解XPath相对路径的重要性和实际应用。
# 4. XPath 绝对路径与相对路径的比较
XPath 作为一种用于在XML和HTML中定位元素的语言,在路径选择上存在绝对路径和相对路径两种选择。本章将对这两种路径进行深入比较分析,并探讨它们在不同场景下的最佳应用方式。
#### 4.1 优缺点对比分析
##### 4.1.1 绝对路径的优缺点
优点:
- 更精准:使用绝对路径可以直接定位到目标元素,确保唯一性和准确性。
- 可靠性高:不受上下文环境的影响,适用于固定结构的文档。
缺点:
- 脆弱性:文档结构的微小改变都可能导致路径失效,维护成本高。
- 可读性差:过长的路径不易读懂,维护困难。
##### 4.1.2 相对路径的优缺点
优点:
- 灵活性强:适应文档结构变化,相对路径更具适应性。
- 可读性好:简短的路径更易于理解和维护。
缺点:
- 需要上下文支持:在复杂结构的文档中,相对路径可能无法准确定位目标元素。
- 性能开销:相对路径可能需要更多的计算来定位目标元素。
#### 4.2 选择何种路径的考量因素
在实际应用中,需要综合考虑以下因素:
- 文档结构稳定性:如果文档结构经常变动,相对路径更具优势;反之,绝对路径可能更适合。
- 定位精准度:如果目标元素在文档中唯一且固定,绝对路径更合适;否则,相对路径更灵活。
- 可读性和维护成本:相对路径在可读性和维护成本上具有优势,特别是对于长期维护的项目更为重要。
#### 4.3 区分不同场景下的最佳应用
在实际场景中,可以根据文档结构的稳定性、定位元素的精准度以及项目的维护需求,灵活选择绝对路径和相对路径的结合使用。在文档结构较为稳定且目标元素固定的情况下,可以优先考虑绝对路径;而在文档结构变化频繁或需要更灵活定位的情况下,相对路径更为适合。
通过深入了解路径选择的优缺点和考量因素,可以更加准确地应用XPath路径语言,提高定位元素的准确性和代码的可维护性。
# 5. XPath 路径的实际应用
XPath路径不仅仅可以用于在XML和HTML文档中定位和选择元素,还可以在各种实际场景中发挥作用。以下是XPath路径在不同应用中的具体使用方式:
#### 5.1 XPath 路径在网页数据抓取中的应用
在网页数据抓取中,XPath路径可以帮助我们准确定位到需要抓取的数据。比如,在使用网络爬虫抓取网页数据时,可以通过XPath路径选择特定的HTML元素,提取其中的文本内容或链接地址。
```python
import requests
from lxml import etree
# 发起请求
response = requests.get('https://example.com')
html = etree.HTML(response.text)
# 使用XPath路径抓取标题
title = html.xpath('//h1/text()')
print(title)
```
#### 5.2 XPath 路径在数据提取和解析中的使用
在数据提取和解析中,XPath路径可以帮助我们从结构化数据中提取所需的信息。比如,可以使用XPath路径从XML数据中提取特定的字段,或从HTML表格中获取数据。
```java
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document doc = builder.parse(new InputSource(new StringReader("<data><name>John</name><age>30</age></data>")));
XPath xpath = XPathFactory.newInstance().newXPath();
String name = (String) xpath.compile("/data/name/text()").evaluate(doc, XPathConstants.STRING);
System.out.println(name);
```
#### 5.3 XPath 路径在自动化测试中的应用案例
在自动化测试中,XPath路径可以作为定位元素的方法,用于模拟用户操作或验证页面内容。通过XPath路径定位到特定的元素,可以进行点击、输入文本或获取元素属性等操作。
```javascript
const element = driver.findElement(By.xpath("//input[@id='username']"));
element.sendKeys("testuser");
```
通过这些实际应用案例,我们可以看到XPath路径在不同领域中的灵活运用,具有广泛的实用性和适用性。
# 6. XPath 实践技巧和注意事项
XPath具有强大的功能,但在实际应用中也需要注意一些技巧和注意事项。本章将介绍在实际开发中编写XPath时需要遵循的最佳实践,并指出在不同浏览器和环境下的兼容性注意事项。
6.1 XPath 编写的最佳实践
在编写XPath时,需要考虑到页面结构的灵活性和稳定性,可以采取以下最佳实践:
- 使用简洁而具有唯一性的表达式:避免使用过于复杂的XPath表达式,尽量使用能够准确定位到元素且具有唯一性的简洁表达式。
- 适当利用元素属性:如果元素的子元素定位困难,可以考虑利用元素的属性来定位,如class、id等。
- 注意页面结构的变化:在编写XPath时需要考虑页面结构的变化,尽量使用相对稳定的路径来定位元素。
6.2 避免常见的 XPath 错误
在编写XPath时,常见的错误包括路径错误、语法错误、定位元素错误等。为了避免这些错误,需要进行良好的测试和验证,确保XPath表达式能够准确地定位到目标元素。
6.3 XPath 在不同浏览器和环境下的兼容性注意事项
不同浏览器和环境下对XPath的支持程度可能会有所差异,如在IE浏览器中可能不支持部分XPath语法。因此,在开发过程中需要对不同浏览器和环境进行充分的兼容性测试,确保XPath表达式在各种情况下都能正常工作。
通过遵循上述实践和注意事项,可以在实际开发中更加准确和稳定地使用XPath定位元素,提高开发效率和代码质量。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实时系统空间效率】:确保即时响应的内存管理技巧

# 1. 实时系统的内存管理概念
在现代的计算技术中,实时系统凭借其对时间敏感性的要求和对确定性的追求,成为了不可或缺的一部分。实时系统在各个领域中发挥着巨大作用,比如航空航天、医疗设备、工业自动化等。实时系统要求事件的处理能够在确定的时间内完成,这就对系统的设计、实现和资源管理提出了独特的挑战,其中最为核心的是内存管理。
内存管理是操作系统的一个基本组成部
【Python预测模型构建全记录】:最佳实践与技巧详解
# 1. Python预测模型基础
Python作为一门多功能的编程语言,在数据科学和机器学习领域表现得尤为出色。预测模型是机器学习的核心应用之一,它通过分析历史数据来预测未来的趋势或事件。本章将简要介绍预测模型的概念,并强调Python在这一领域中的作用。
## 1.1 预测模型概念
预测模型是一种统计模型,它利用历史数据来预测未来事件的可能性。这些模型在金融、市场营销、医疗保健和其
【算法竞赛中的复杂度控制】:在有限时间内求解的秘籍
# 1. 算法竞赛中的时间与空间复杂度基础
## 1.1 理解算法的性能指标
在算法竞赛中,时间复杂度和空间复杂度是衡量算法性能的两个基本指标。时间复杂度描述了算法运行时间随输入规模增长的趋势,而空间复杂度则反映了算法执行过程中所需的存储空间大小。理解这两个概念对优化算法性能至关重要。
## 1.2 大O表示法的含义与应用
大O表示法是用于描述算法时间复杂度的一种方式。它关注的是算法运行时
时间序列分析的置信度应用:预测未来的秘密武器
# 1. 时间序列分析的理论基础
在数据科学和统计学中,时间序列分析是研究按照时间顺序排列的数据点集合的过程。通过对时间序列数据的分析,我们可以提取出有价值的信息,揭示数据随时间变化的规律,从而为预测未来趋势和做出决策提供依据。
## 时间序列的定义
时间序列(Time Series)是一个按照时间顺序排列的观测值序列。这些观测值通常是一个变量在连续时间点的测量结果,可以是每秒的温度记录,每日的股票价
极端事件预测:如何构建有效的预测区间
# 1. 极端事件预测概述
极端事件预测是风险管理、城市规划、保险业、金融市场等领域不可或缺的技术。这些事件通常具有突发性和破坏性,例如自然灾害、金融市场崩盘或恐怖袭击等。准确预测这类事件不仅可挽救生命、保护财产,而且对于制定应对策略和减少损失至关重要。因此,研究人员和专业人士持
模型训练的动态Epochs策略
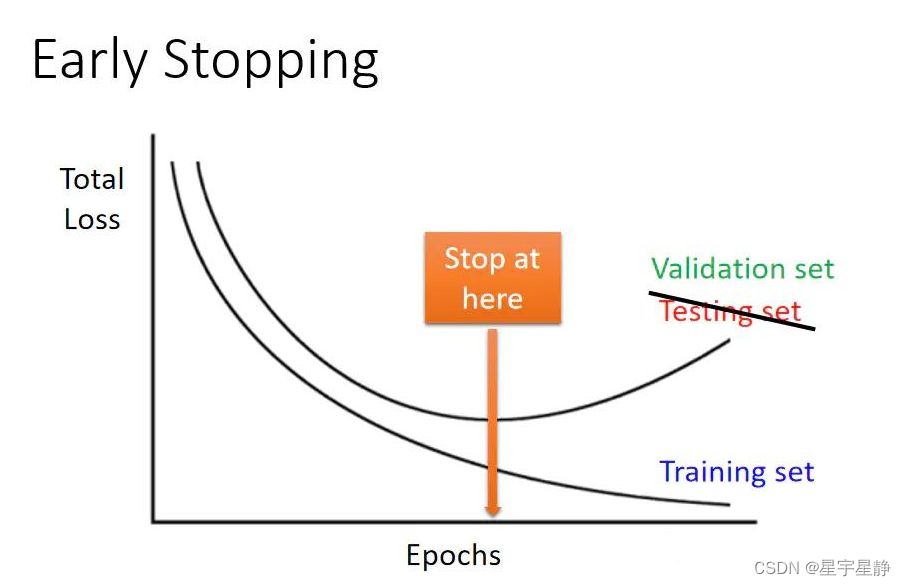
# 1. 模型训练基础与Epochs概念
在机器学习与深度学习模型的训练过程中,模型训练的循环次数通常由一个重要的参数控制:Epochs。简单来说,一个Epoch代表的是使用训练集中的所有数据对模型进行一次完整训练的过程。理解Epochs对于掌握机器学习模型训练至关重要,因为它的选择直接影响到模型的最终性能。
## Epochs的作用
Epochs的作用主要体现在两个方面:
- **模型参数更新:** 每一
机器学习性能评估:时间复杂度在模型训练与预测中的重要性
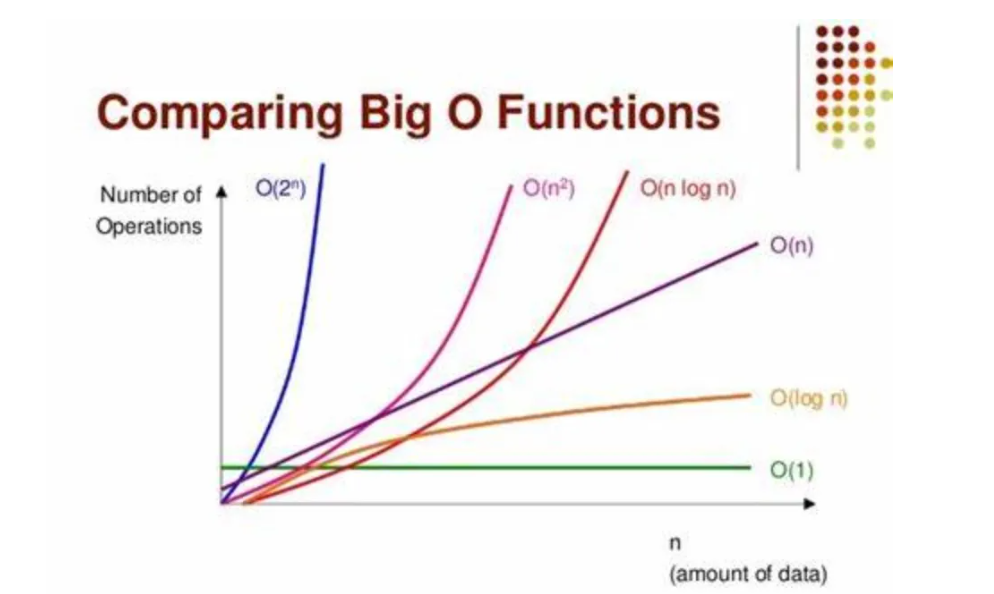
# 1. 机器学习性能评估概述
## 1.1 机器学习的性能评估重要性
机器学习的性能评估是验证模型效果的关键步骤。它不仅帮助我们了解模型在未知数据上的表现,而且对于模型的优化和改进也至关重要。准确的评估可以确保模型的泛化能力,避免过拟合或欠拟合的问题。
## 1.2 性能评估指标的选择
选择正确的性能评估指标对于不同类型的机器学习任务至关重要。例如,在分类任务中常用的指标有
贝叶斯优化:智能搜索技术让超参数调优不再是难题
# 1. 贝叶斯优化简介
贝叶斯优化是一种用于黑盒函数优化的高效方法,近年来在机器学习领域得到广泛应用。不同于传统的网格搜索或随机搜索,贝叶斯优化采用概率模型来预测最优超参数,然后选择最有可能改进模型性能的参数进行测试。这种方法特别适用于优化那些计算成本高、评估函数复杂或不透明的情况。在机器学习中,贝叶斯优化能够有效地辅助模型调优,加快算法收敛速度,提升最终性能。
接下来,我们将深入探讨贝叶斯优化的理论基础,包括它的工作原理以及如何在实际应用中进行操作。我们将首先介绍超参数调优的相关概念,并探讨传统方法的局限性。然后,我们将深入分析贝叶斯优化的数学原理,以及如何在实践中应用这些原理。通过对
探索与利用平衡:强化学习在超参数优化中的应用
# 1. 强化学习与超参数优化的交叉领域
## 引言
随着人工智能的快速发展,强化学习作为机器学习的一个重要分支,在处理决策过程中的复杂问题上显示出了巨大的潜力。与此同时,超参数优化在提高机器学习模型性能方面扮演着关键角色。将强化学习应用于超参数优化,不仅可实现自动化,还能够通过智能策略提升优化效率,对当前AI领域的发展产生了深远影响。
## 强化学习与超参数优化的关系
强化学习能够通过与环境的交互来学
模型参数泛化能力:交叉验证与测试集分析实战指南

# 1. 交叉验证与测试集的基础概念
在机器学习和统计学中,交叉验证(Cross-Validation)和测试集(Test Set)是衡量模型性能和泛化能力的关键技术。本章将探讨这两个概念的基本定义及其在数据分析中的重要性。
## 1.1 交叉验证与测试集的定义
交叉验证是一种统计方法,通过将原始数据集划分成若干小的子集,然后将模型在这些子集上进行训练和验证,以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )