【深入Java日志库】:Log4j 2高级特性详解
发布时间: 2024-09-27 17:49:01 阅读量: 112 订阅数: 42 

log4j,log4j2,slf4j,Java日志全部示例
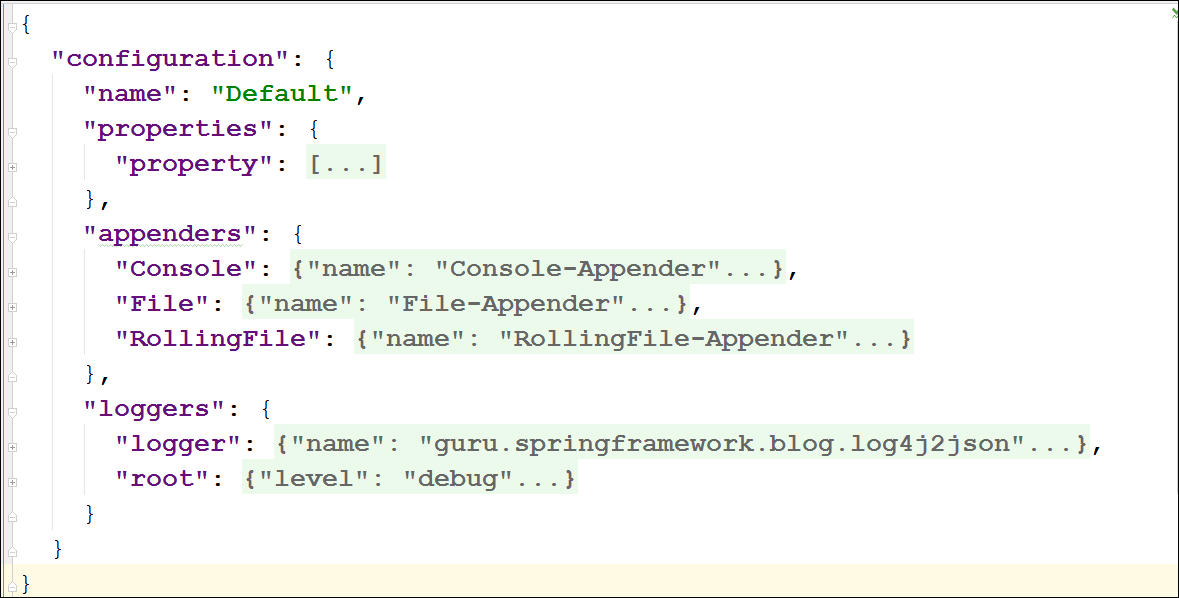
# 1. Log4j 2概述与基础配置
## 1.1 Log4j 2简介
Log4j 2是Apache基金会下的一个日志处理库,它提供了强大的日志记录功能,并且与早期的Log4j版本相比,性能上有显著的提升。Log4j 2不仅支持基于配置文件的日志记录,也支持Java代码配置,且能够实现异步日志记录,从而最小化对应用程序性能的影响。它是Java开发者在处理应用程序日志时的理想选择之一。
## 1.2 Log4j 2的安装与环境配置
在项目中引入Log4j 2非常简单,通常只需要添加依赖库到项目构建配置文件中即可。例如,在Maven项目中,只需在`pom.xml`文件中添加以下依赖:
```xml
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.x.x</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.x.x</version>
</dependency>
```
其中`2.x.x`应替换为当前的最新版本。之后,您可以配置一个基础的日志系统,通常通过编写`log4j2.xml`配置文件来实现。该文件应放在项目的`src/main/resources`目录下,具体内容示例如下:
```xml
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
```
这段配置文件定义了一个控制台输出器(Console Appender),它使用特定的模式(Pattern)来格式化日志信息,并将日志级别设置为`info`。
## 1.3 基础配置的执行逻辑
上述基础配置中,日志记录器(Logger)的根配置被设置为`info`级别,这意味着所有优先级不低于`info`的事件都会被处理。`AppenderRef`标签指明了将日志输出到哪里,这里的`Console`指定了输出到控制台。模式布局(PatternLayout)定义了日志消息的格式,`%d`代表日期和时间,`%t`代表线程名,`%-5level`显示日志级别,`%logger`显示记录日志的类的名称,`%msg`是日志消息,`%n`是换行符。
通过以上步骤,Log4j 2便可以开始记录应用程序运行中的各种信息。日志管理是开发和维护中不可或缺的工具,一个合理的日志配置能够帮助开发者及时定位和解决问题,保证系统的稳定性。接下来的章节中,我们将深入了解Log4j 2的核心组件,包括Logger、Appender和Filter等。
# 2. ```
# 第二章:Log4j 2核心组件解析
Log4j 2作为一个强大的日志管理框架,提供了丰富的API和配置选项,使得开发者能够轻松地处理日志记录、管理、以及优化。在本章,我们将深入探讨Log4j 2的核心组件,包括日志记录器Logger、Appender机制、以及日志过滤器Filter,并分析这些组件的具体应用和性能影响。
## 2.1 日志记录器 Logger
Logger是Log4j 2中最核心的组件,它负责按照日志级别记录日志消息。通过合理的配置和使用Logger,开发人员可以对日志的输出进行细致的控制。
### 2.1.1 Logger 的层次结构与性能影响
Logger在Log4j中是按照树状的层次结构组织的,每个Logger都有一个与之相关联的名称,这个名称通常和包名、类名相同。Logger间的层次关系使得父Logger的设置可以影响到子Logger。例如,如果一个子Logger没有被配置,那么它将会继承父Logger的配置。
层次结构对性能的影响主要体现在配置继承上。为了避免频繁地查找和配置继承,Log4j 2使用了Logger上下文(Context)来缓存这些配置信息。然而,如果层次结构过于复杂,配置的解析和应用可能会消耗更多的资源。因此,在配置Logger时,应当尽量保持层次结构的简洁。
### 2.1.2 Logger 的配置选项与使用场景
在配置文件log4j2.xml中,我们可以详细地设置每个Logger的级别和附加的Appender。配置选项包括但不限于:日志级别、是否添加附加的Appender、是否继承父Logger的配置等。
对于不同使用场景,Logger的配置也有所不同。例如,在生产环境中,我们可能需要记录DEBUG级别的日志以进行问题追踪,但在开发环境中则可能更关注INFO级别以上的日志。通过合理配置Logger,可以使得日志系统更加灵活和强大。
## 2.2 Appender 机制与扩展
Appender是Log4j中用于输出日志的组件。它们决定了日志的存储位置和格式。
### 2.2.1 标准 Appender 类型与配置
Log4j 2提供了多种标准的Appender类型,比如ConsoleAppender用于输出到控制台,FileAppender用于输出到文件,RollingFileAppender用于文件的日志滚动等。每种Appender都有自己的配置选项,如文件路径、文件名模式、缓冲大小等。
以ConsoleAppender为例,我们可以在log4j2.xml中这样配置它:
```xml
<Appender name="STDOUT" class="org.apache.logging.log4j.core.appender.ConsoleAppender">
<Target>SYSTEM_OUT</Target>
<PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n"/>
</Appender>
```
上述配置定义了一个输出到控制台的Appender,它使用特定的模式格式化日志消息。
### 2.2.2 自定义 Appender 的实现与应用
在特定场景下,标准的Appender可能无法满足需求,这时可以通过实现自己的Appender来扩展Log4j的功能。自定义Appender需要继承`org.apache.logging.log4j.core.Appender`类,并实现必要的方法,例如`append(LogEvent event)`用于处理日志事件。
下面是一个简单的自定义Appender的示例代码:
```java
public class CustomAppender extends AbstractAppender {
protected CustomAppender(String name, Filter filter, Layout<? extends Serializable> layout) {
super(name, filter, layout);
}
@Override
public void append(LogEvent event) {
// 实现自定义的日志处理逻辑
}
}
```
通过自定义Appender,我们可以将日志输出到特殊的目的地,比如数据库、消息队列等。在实际应用中,自定义Appender可以提供更大的灵活性和扩展性。
## 2.3 日志过滤器 Filter
Filter允许在Logger和Appender之间进行动态日志过滤。它基于日志事件来决定是否允许日志消息被进一步处理或输出。
### 2.3.1 内建 Filter 的功能与应用
Log4j 2提供了一系列内建的Filter,如ThresholdFilter、MarkerFilter、RegexFilter等。这些Filter可以基于日志级别、标记、内容等进行过滤。
例如,ThresholdFilter能够确保只有高于或等于特定级别的日志才会被处理:
```xml
<ThresholdFilter level="debug" onMatch="ACCEPT" onMismatch="DENY"/>
```
上述配置表示只接受DEBUG级别及以上的日志,其他的将被拒绝。
### 2.3.2 自定义 Filter 的开发与配置
就像Appender一样,Log4j 2也支持自定义Filter的创建。自定义Filter需要实现`org.apache.logging.log4j.core.Filter`接口,并定义`filter()`方法来决定是否接受或拒绝日志事件。
下面是一个简单的自定义Filter的示例代码:
```java
public class CustomFilter extends AbstractFilter {
public int filter(LogEvent event) {
// 这里可以实现自定义的过滤逻辑,返回DENY、NEUTRAL或ACCEPT
}
}
```
通过自定义Filter,开发者可以控制更细粒度的日志处理逻辑,这对于某些特殊的日志管理需求非常有用。
在本章中,我们深入探讨了Log4j 2的核心组件,包括日志记录器Logger、Appender机制和日志过滤器Filter。这些组件的工作机制和配置方法对于构建高效、可控的日志系统至关重要。在下一章节中,我们将讨论Log4j 2的高级特性以及它们在实际应用中的实践。
```
# 3. Log4j 2的高级特性与实践
## 3.1 异步日志处理
### 3.1.1 异步日志的优势与配置
在现代的软件应用中,性能至关重要,尤其是在高负载或实时处理系统中。Log4j 2引入了异步日志记录器(Async Loggers),它允许日志事件在另一个线程中异步处理,大大提高了日志记录的性能。异步日志处理的优势在于减少了线程阻塞的可能性,避免了I/O操作的延迟,这对于优化关键路径的性能有显著效果。
要配置异步日志记录器,只需在log4j2.xml中进行简单配置即可:
```xml
<AsyncRoot level="info">
<AppenderRef ref="AsyncFileAppender"/>
</AsyncRoot>
```
在上述配置中,`AsyncRoot` 标签内的 `level` 属性指定了日志级别,而 `AppenderRef` 标签引用了一个异步的appender。这个appender需要单独配置,并且支持所有标准的appender类型。
### 3.1.2 异步日志的性能优化与案例分析
在实现异步日志时,Log4j 2允许进一步优化性能。例如,可以在异步appender中设置队列容量和策略,如“Discard”或“Error”策略。如果队列满,Discard策略会丢弃消息,而Error策略会在控制台输出错误信息。
配置示例:
```xml
<AsyncAppender name="AsyncFileAppender" bufferSize="1024">
<AppenderRef ref="FileAppender"/>
</AsyncAppender>
```
上述配置中`bu

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面介绍了 Java 日志记录库,涵盖从入门到高级主题。它比较了流行的库,如 Log4j、Logback 和 SLF4J,深入探讨了它们的架构和设计模式。专栏还提供了性能测试结果,指导读者在大型 Java 应用程序中选择和使用日志框架。此外,它还介绍了日志库的最佳实践、审计和分析技巧,以及动态日志级别调整。深入了解 Log4j 2 的高级特性,并比较了不同日志库的性能和功能。专栏还提供了构建日志监控解决方案、制定日志规范、扩展日志库以及解决实际日志管理问题的案例研究。通过本专栏,读者将掌握 Java 日志记录的各个方面,并能够在自己的应用程序中有效地使用日志库。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘HID协议:中文版Usage Tables实战演练与深入分析

# 摘要
人类接口设备(HID)协议是用于计算机和人机交互设备间通信的标准协议,广泛应用于键盘、鼠标、游戏控制器等领域。本文首先介绍了HID协议的基本概念和理论基础,深入分析了其架构、组成以及Usage Tables的定义和分类。随后,通过实战演练,本文阐述了如何在设备识别、枚举和自定
【掌握核心】:PJSIP源码深度解读与核心功能调试术

# 摘要
PJSIP是一个广泛使用的开源SIP协议栈,它提供了丰富的功能集和高度可定制的架构,适用于嵌入式系统、移动设备和桌面应用程序。本文首先概述了PJ
【网络稳定性秘籍】:交换机高级配置技巧,揭秘网络稳定的秘诀

# 摘要
交换机作为网络基础设施的核心设备,其基本概念及高级配置技巧对于保障网络稳定性至关重要。本文首先介绍了交换机的基本功能及其在网络稳定性中的重要性,然后深入探讨了交换机的工作原理、VLAN机制以及网络性能指标。通过理论和实践结合的方式,本文展示了如何通过高级配置技巧,例如VLAN与端口聚合配置、安全设置和性能优化来提升网络的可靠性和
Simtrix.simplis仿真模型构建:基础知识与进阶技巧(专业技能揭秘)

# 摘要
本文全面介绍了Simtrix.simplis仿真模型的基础知识、原理、进阶应用和高级技巧与优化。首先,文章详细阐述了Simtrix.simplis仿真环境的设置、电路图绘制和参数配置等基础操作,为读者提供了一个完整的仿真模型建立过程。随后,深入分析了仿真模型的高级功能,包括参数扫描、多域仿真技术、自定义模
【数字电位器电压控制】:精确调节电压的高手指南

# 摘要
数字电位器作为一种可编程的电阻器,近年来在电子工程领域得到了广泛应用。本文首先介绍了数字电位器的基本概念和工作原理,随后通过与传统模拟电位器的对比,凸显其独特优势。在此基础上,文章着重探讨了数字电位器在电压控制应用中的作用,并提供了一系列编程实战的案例。此外,本文还分享了数字电位器的调试与优化技
【通信故障急救】:台达PLC下载时机不符提示的秒杀解决方案

# 摘要
本文全面探讨了通信故障急救的全过程,重点分析了台达PLC在故障诊断中的应用,以及通信时机不符问题的根本原因。通过对通信协议、同步机制、硬件与软件配合的理论解析,提出了一套秒杀解决方案,并通过具体案例验证了其有效性。最终,文章总结了成功案例的经验,并提出了预防措施与未来通信故障处理的发展方向,为通信故障急救提供了理论和实践上的指导。
# 关键字
通信故障;PLC故障诊断;通信协议;同步机制;故障模型
【EMMC协议深度剖析】:工作机制揭秘与数据传输原理解析

# 摘要
本文对EMMC协议进行了全面的概述和深入分析。首先介绍了EMMC协议的基本架构和组件,并探讨了其工作机制,包括不同工作模式和状态转换机制,以及电源管理策略及其对性能的影响。接着,深入分析了EMMC的数据传输原理,错误检测与纠正机制,以及性能优化策略。文中还详细讨论了EMMC协议在嵌入式系统中的应用、故障诊断和调试,以及未来发展趋势。最后,本文对EMMC协议的扩展和安全性、与
【文件哈希一致性秘籍】:揭露Windows与Linux下MD5不匹配的真正根源
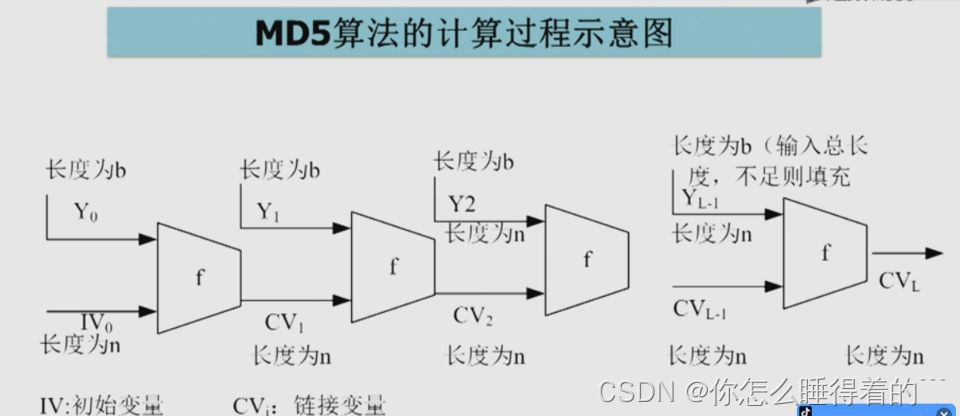
# 摘要
本文首先介绍了哈希一致性与MD5算法的基础知识,随后深入探讨了MD5的工作原理、数学基础和详细步骤。分析了MD5算法的弱点及其安全性问题,并对Windows和Linux文件系统的架构、特性和元数据差异进行了比较。针对MD5不匹配的实践案例,本文提供了原因分析、案例研究和解决方案。最后,探讨了哈希一致性检查工具的种类与选择、构建自动化校验流程的方法,并展望了哈希算法的未
高速数据采集:VISA函数的应用策略与技巧

# 摘要
高速数据采集技术在现代测量、测试和控制领域发挥着至关重要的作用。本文首先介绍了高速数据采集技术的基础概念和概况。随后,深入探讨了VISA(Virtual Instrument Soft
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )