Logback背后的设计哲学:架构和设计模式解析
发布时间: 2024-09-27 17:29:24 阅读量: 60 订阅数: 38 

# 1. Logback架构概述
## 1.1 Logback简介
Logback作为一款广泛使用的Java日志框架,是log4j的继承者,由Ceki Gülcü创建。它被设计为能够轻松处理不同的日志记录需求,无论是在小型应用还是大型企业级应用中,都能提供高效率、可扩展的日志记录解决方案。Logback支持按级别记录日志,如DEBUG、INFO、WARN、ERROR等,同时也支持按不同的条件和格式输出日志。
## 1.2 核心优势
Logback的核心优势在于其性能和灵活性。它在处理高吞吐量的日志记录时表现出色,特别适合于性能关键型应用场景。此外,Logback还具有易于配置和可插拔的特性,允许开发人员通过简单的配置文件来修改日志策略。日志格式化和输出目标也十分灵活,可以通过Layout和Appender组件自定义。
## 1.3 工作原理
Logback的工作原理基于三个核心组件:Logger、Appender和Layout。Logger负责记录日志,Appender决定日志的输出位置(如控制台、文件或网络),Layout则定义了日志的格式。通过这些组件的协同工作,Logback能够灵活地进行日志的生成、处理和输出。同时,Logback还提供了滚动策略和过滤器来进一步管理日志的生命周期和内容。
# 2. Logback核心组件分析
### 2.1 Logger, Appender, Layout三大组件
#### 2.1.1 Logger的职责和层次结构
在Logback的日志系统中,`Logger`是用于记录日志的组件,它处于日志系统的核心位置。一个`Logger`代表了一个日志记录器,它负责捕获所有相关的日志信息,并提供给`Appender`进行处理。`Logger`具有继承的层次结构,即一个`Logger`会查找它的父`Logger`,直到根`Logger`,以决定是否将日志事件传递给`Appender`。
为了管理好日志输出,通常会按照不同的模块或功能定义多个`Logger`,以区分不同来源的日志。`Logger`通过设置不同的日志级别(如INFO, DEBUG, ERROR等)来决定是否要捕获某些级别以上的日志信息。比如,如果你只想记录ERROR级别的信息,那么你的`Logger`就需要设置为ERROR级别。
```java
Logger logger = LoggerFactory.getLogger(MyClass.class);
***("This is an info message.");
```
在上面的Java代码片段中,我们创建了一个特定于`MyClass`类的`Logger`实例,并使用`info`方法记录了一条信息。这将会触发日志记录请求,该请求将根据`Logger`的设置(例如日志级别)传递给相应的`Appender`。
#### 2.1.2 Appender的类型和配置
`Appender`是负责实际记录日志的组件,它定义了日志事件的输出目的地,例如控制台、文件或远程服务器等。Logback支持多种类型的`Appender`,包括但不限于:
- `ConsoleAppender`:将日志输出到控制台。
- `FileAppender`:将日志输出到文件系统上的文件。
- `RollingFileAppender`:在`FileAppender`基础上增加了滚动策略,支持日志文件的自动轮换。
- `SMTPAppender`:将日志通过电子邮件发送。
- `SyslogAppender`:将日志发送到远程的syslog服务器。
`Appender`的配置通常在Logback的配置文件中完成(如`logback.xml`),以下是一个`FileAppender`的配置示例:
```xml
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>logs/myapp.log</file>
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
```
在此配置中,`FileAppender`设置了一个输出文件`myapp.log`,并指定了一个`Encoder`来定义日志格式。
#### 2.1.3 Layout的作用和转换模式
`Layout`是定义日志格式的组件。它将日志事件(如时间戳、日志级别、消息内容等)转换成字符串,并发送给`Appender`。`Layout`对于生成符合用户需求的日志格式至关重要。
Logback的`Layout`支持多种转换模式,允许用户以一种高度自定义的方式格式化日志输出。一个常用的`Layout`是`PatternLayout`,它使用转换模式字符串来定义输出格式。
```xml
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
```
上面的`pattern`定义了一个具体的日志格式,其中包含时间戳、线程名、日志级别、记录器名和消息内容。这种自定义格式化让日志信息更加清晰易读。
在深入了解了Logger、Appender和Layout这三个核心组件之后,您现在应该对如何在Logback中使用这些组件有了基本的理解。接下来,我们将探讨Logback如何实现滚动策略以及过滤器的工作原理。
# 3. Logback设计模式探究
## 3.1 工厂模式在Logback中的应用
### 3.1.1 Logback工厂模式的实现细节
工厂模式是一种创建型设计模式,它提供了一种在创建对象时不直接指定其具体类,而是由一个工厂类来决定创建哪一个类的实例的机制。在Logback中,工厂模式被广泛用于对象的创建过程,它使得日志系统的配置更为灵活且易于扩展。
在Logback的实现中,工厂模式主要体现在以下几个方面:
- **LoggerFactory**:Logback使用`LoggerFactory`来创建日志记录器`Logger`的实例。`LoggerFactory`持有一个`LoggerContext`,通过调用其`getLogger`方法来创建对应的`Logger`实例。
- **AppenderFactory**:`Appender`的创建也是通过工厂模式实现的。Logback通过配置文件中定义的类名来决定实例化哪一个`Appender`的子类,从而实现灵活的配置。
- **LayoutFactory**:`Layout`负责日志消息的格式化,不同的`Appender`需要不同的`Layout`。Logback通过工厂模式来创建与`Appender`相匹配的`Layout`对象。
### 3.1.2 工厂模式的优势和场景适应性
工厂模式的优势在于它将对象的创建和使用分离开来,当添加新的日志记录器或`Appender`时,不需要修改现有代码,只需配置相应的类名即可。
工厂模式尤其适用于以下场景:
- **对象创建的逻辑较为复杂**:工厂模式可以封装创建细节,使得客户端代码无需关心创建过程的复杂性。
- **系统需要高度扩展性**:当系统的扩展性需求较高时,使用工厂模式可以非常方便地增加新的产品类型。
- **产品类族已经明确,而且产品族中各产品的区别仅在于具体实现**:在Logback中,无论是`Logger`、`Appender`还是`Layout`,都可以根据特定的配置来创建具体实现。
## 3.2 策略模式在日志级别管理中的应用
### 3.2.1 策略模式的定义和原则
策略模式是一种行为设计

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面介绍了 Java 日志记录库,涵盖从入门到高级主题。它比较了流行的库,如 Log4j、Logback 和 SLF4J,深入探讨了它们的架构和设计模式。专栏还提供了性能测试结果,指导读者在大型 Java 应用程序中选择和使用日志框架。此外,它还介绍了日志库的最佳实践、审计和分析技巧,以及动态日志级别调整。深入了解 Log4j 2 的高级特性,并比较了不同日志库的性能和功能。专栏还提供了构建日志监控解决方案、制定日志规范、扩展日志库以及解决实际日志管理问题的案例研究。通过本专栏,读者将掌握 Java 日志记录的各个方面,并能够在自己的应用程序中有效地使用日志库。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
全球高可用部署:MySQL PXC集群的多数据中心策略

# 1. 高可用部署与MySQL PXC集群基础
在IT行业,特别是在数据库管理系统领域,高可用部署是确保业务连续性和数据一致性的关键。通过本章,我们将了解高可用部署的基础以及如何利用MySQL Percona XtraDB Cluster (PXC) 集群来实现这一目标。
## MySQL PXC集群的简介
MySQL PXC集群是一个可扩展的同步多主节点集群解决方案,它能够提供连续可用性和数据一致
【NLP新范式】:CBAM在自然语言处理中的应用实例与前景展望

# 1. NLP与深度学习的融合
在当今的IT行业,自然语言处理(NLP)和深度学习技术的融合已经产生了巨大影响,它们共同推动了智能语音助手、自动翻译、情感分析等应用的发展。NLP指的是利用计算机技术理解和处理人类语言的方式,而深度学习作为机器学习的一个子集,通过多层神经网络模型来模拟人脑处理数据和创建模式
故障恢复计划:机械运动的最佳实践制定与执行

# 1. 故障恢复计划概述
故障恢复计划是确保企业或组织在面临系统故障、灾难或其他意外事件时能够迅速恢复业务运作的重要组成部分。本章将介绍故障恢复计划的基本概念、目标以及其在现代IT管理中的重要性。我们将讨论如何通过合理的风险评估与管理,选择合适的恢复策略,并形成文档化的流程以达到标准化。
## 1.1 故障恢复计划的目的
故障恢复计划的主要目的是最小化突发事件对业务的
拷贝构造函数的陷阱:防止错误的浅拷贝
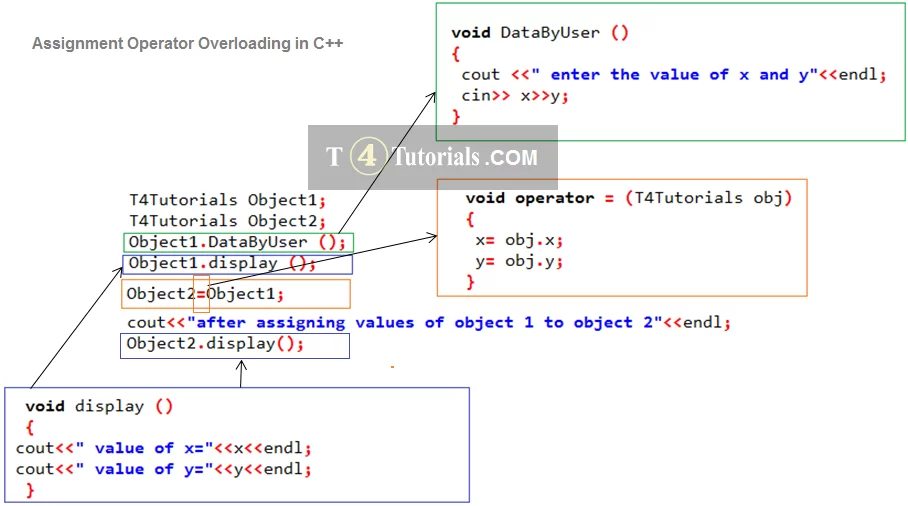
# 1. 拷贝构造函数概念解析
在C++编程中,拷贝构造函数是一种特殊的构造函数,用于创建一个新对象作为现有对象的副本。它以相同类类型的单一引用参数为参数,通常用于函数参数传递和返回值场景。拷贝构造函数的基本定义形式如下:
```cpp
class ClassName {
public:
ClassName(const ClassName& other); // 拷贝构造函数
Android二维码框架选择:如何集成与优化用户界面与交互

# 1. Android二维码框架概述
在移动应用开发领域,二维码技术已经成为不可或缺的一部分。Android作为应用广泛的移动操作系统,其平台上的二维码框架种类繁多,开发者在选择适合的框架时需要综合考虑多种因素。本章将为读者概述二维码框架的基本知识、功
MATLAB遗传算法与模拟退火策略:如何互补寻找全局最优解

# 1. 遗传算法与模拟退火策略的理论基础
遗传算法(Genetic Algorithms, GA)和模拟退火(Simulated Annealing, SA)是两种启发式搜索算法,它们在解决优化问题上具有强大的能力和独特的适用性。遗传算法通过模拟生物
【深度学习在卫星数据对比中的应用】:HY-2与Jason-2数据处理的未来展望

# 1. 深度学习与卫星数据对比概述
## 深度学习技术的兴起
随着人工智能领域的快速发展,深度学习技术以其强大的特征学习能力,在各个领域中展现出了革命性的应用前景。在卫星数据处理领域,深度学习不仅可以自动
Python算法实现捷径:源代码中的经典算法实践

# 1. Python算法实现捷径概述
在信息技术飞速发展的今天,算法作为编程的核心之一,成为每一位软件开发者的必修课。Python以其简洁明了、可读性强的特点,被广泛应用于算法实现和教学中。本章将介绍如何利用Python的特性和丰富的库,为算法实现铺平道路,提供快速入门的捷径
MATLAB时域分析:动态系统建模与分析,从基础到高级的完全指南
# 1. MATLAB时域分析概述
MATLAB作为一种强大的数值计算与仿真软件,在工程和科学领域得到了广泛的应用。特别是对于时域分析,MATLAB提供的丰富工具和函数库极大地简化了动态系统的建模、分析和优化过程。在开始深入探索MATLAB在时域分析中的应用之前,本章将为读者提供一个基础概述,包括时域分析的定义、重要性以及MATLAB在其中扮演的角色。
时域
【JavaScript人脸识别的用户体验设计】:界面与交互的优化

# 1. JavaScript人脸识别技术概述
## 1.1 人脸识别技术简介
人脸识别技术是一种通过计算机图像处理和识别技术,让机器能够识别人类面部特征的技术。近年来,随着人工智能技术的发展和硬件计算能力的提升,JavaScript人脸识别技术得到了迅速的发展和应用。
## 1.2 JavaScript在人脸识别中的应用
JavaScript作为一种强
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )