YOLOv8优化秘籍:特征提取与性能提升的实战对比分析
发布时间: 2024-12-12 03:57:22 阅读量: 6 订阅数: 13 

java+sql server项目之科帮网计算机配件报价系统源代码.zip

# 1. YOLOv8目标检测算法概述
在计算机视觉领域,目标检测技术一直是一个研究热点。YOLO系列算法,作为目前最受欢迎的目标检测模型之一,以其出色的实时性和准确性成为了研究和商业应用中的宠儿。本章将对YOLOv8算法进行基础性概述,为后续章节中对YOLOv8的深入剖析、性能优化技巧、实战案例分析以及未来发展方向奠定基础。
## YOLOv8的发展背景
YOLO(You Only Look Once)算法因其高效性,即一次通过即可完成目标定位和分类,而广为人知。YOLOv8作为该系列算法的最新版本,不仅继承了前几代的快速检测能力,还在准确性、鲁棒性和可扩展性方面做出了显著改进。它针对不同环境和场景提供了更多灵活性,适用于包括安防监控、自动驾驶车辆、工业视觉检测等多个领域。
## YOLOv8的核心特点
- **实时性能**:YOLOv8在保持高检测精度的同时,进一步优化了模型的运行效率,使其在边缘设备上也可实现接近实时的处理速度。
- **准确性提升**:通过改进特征提取机制和后处理技术,YOLOv8在多数标准数据集上显示了更高的检测精度。
- **易于扩展**:YOLOv8允许研究人员和工程师轻松地修改和扩展以适应特定的应用需求。
随着第一章的结束,我们对YOLOv8有了初步的了解。接下来的章节将会详细探讨YOLOv8的内部工作机制,包括其特征提取机制和关键技术,以及如何利用这些机制进行性能优化和实际应用。
# 2. YOLOv8的特征提取机制深入剖析
YOLOv8的特征提取机制是整个目标检测系统的核心,涉及如何高效地从原始图像中提取信息,然后通过网络结构的深度处理,转化为可用于目标检测的丰富特征。本章节将深入分析YOLOv8中的特征提取框架、关键技术以及如何通过这些技术提升检测准确率。
## 2.1 YOLOv8的特征提取框架
### 2.1.1 网络结构与层次
YOLOv8的网络结构设计是基于特征提取深度和宽度的权衡结果。在网络的初始阶段,浅层网络通过卷积操作捕获图像中的边缘和纹理等基础特征。随着网络层次的加深,高层网络开始提取更为复杂的模式,如形状和对象的部分结构。
为了有效地提取特征,YOLOv8采用了类似于ResNet的残差结构,这种结构允许梯度直接流经网络,从而解决深层网络训练困难的问题。残差块内通常包括卷积层、批量归一化层和非线性激活函数等,这些组件共同协作,使得网络可以训练得更深,同时也保持了信息的完整性。
```mermaid
flowchart LR
Input --> Conv1[Convolution Layer]
Conv1 --> BatchNorm1[Batch Normalization]
BatchNorm1 --> Act1[Activation Function]
Act1 --> ResidualBlock[Residual Block]
ResidualBlock --> Conv2[Convolution Layer]
Conv2 --> BatchNorm2[Batch Normalization]
BatchNorm2 --> Act2[Activation Function]
Act2 --> Add[Addition Operation]
Add --> Output[Output Feature Map]
```
### 2.1.2 特征图的生成和理解
特征图是网络层间传递信息的载体,每一个特征图都代表了图像在特定空间尺度上的特征表示。YOLOv8通过卷积操作生成特征图,每个卷积核都可以看作是一个滤波器,专门用于检测图像中的某种特定特征。
特征图的大小由卷积核的尺寸、步长和填充策略决定。YOLOv8在设计上利用了不同尺寸的卷积核以捕捉从粗到细的特征,并且通过池化层降低特征图的空间维度,增加感受野,实现多尺度的特征提取。
## 2.2 YOLOv8中的关键技术
### 2.2.1 空洞卷积与注意力机制
空洞卷积允许网络在保持分辨率的同时,增加感受野,这种设计对目标检测尤为重要,因为检测任务往往需要关注图像的全局信息以识别目标。YOLOv8运用空洞卷积在深层次网络中替代部分标准卷积,来扩大卷积核的视域而不增加计算量。
注意力机制的引入进一步提升了网络对重要特征的提取能力。例如,在YOLOv8中可以使用SENet(Squeeze-and-Excitation Networks)中的注意力模块,这个模块通过学习各个特征通道的重要性,自动调整特征的权重,使网络更加专注于对目标检测有贡献的特征。
### 2.2.2 预训练模型的应用与调整
在深度学习领域,使用预训练模型进行迁移学习是加速训练过程和提高最终模型性能的有效手段。YOLOv8也不例外,通常会使用在大规模数据集(如ImageNet)上预训练的模型作为起点,然后针对特定的目标检测任务进行微调。
在调整预训练模型时,需要对最后几层进行特殊处理,这些层通常与原始数据集的特征空间最为相关。通过重新训练和调整这些层,可以使得模型更好地适应新的数据分布,并提升在特定任务上的表现。
## 2.3 特征提取与提升准确率的策略
### 2.3.1 多尺度特征融合
在目标检测任务中,需要对不同大小的对象进行检测,这就要求模型能够同时处理不同尺度的特征。为此,YOLOv8采用了多尺度特征融合的策略,将来自不同网络层次的特征图整合起来,形成综合的特征表示。
具体实现上,可以使用像特征金字塔网络(Feature Pyramid Network, FPN)这样的结构,该结构将高层的语义信息和低层的细节信息结合起来,以此来捕捉不同尺度的目标。这种方法有效地平衡了速度和准确率,使得YOLOv8即使在复杂的场景下也能保持良好的检测性能。
### 2.3.2 非极大值抑制(NMS)的改进
非极大值抑制是一种常用的方法,用于去除目标检测中的多余框,从而得到最终的检测结果。YOLOv8对传统的NMS方法进行了改进,以提升其在复杂背景中的准确率和鲁棒性。
改进的NMS会考虑到检测框的置信度和目标类别的概率分布,从而更合理地选择保留哪些框。此外,还可能引入一些启发式规则,比如针对不同尺寸的目标采用不同的NMS阈值,或者对不同类别设置不同的阈值,以优化整体的检测性能。
```markdown
| 参数 | 描述 |
|------|------|
| IOU阈值 | 用于判定重叠框是否为同一个目标的交并比 |
| 置信度阈值 | 最小目标检测置信度 |
| 类别阈值 | 对每个类别的置信度阈值 |
```
通过上述对YOLOv8特征提取机制的深入剖析,我们可以看到其在设计上的精妙之处,以及如何通过一系列的高级技术来确保检测任务的有效性。下一章节,我们将探讨如何进一步优化YOLOv8的性能,使之更加适应实际应用场景的需求。
# 3. YOLOv8性能优化的实践技巧
## 3.1 硬件加速与模型部署
### 3.1.1 GPU加速与NPU支持
深度学习模型,特别是实时目标检测算法如YOLOv8,在实际应用中对硬件的要求较高。GPU加速是提升模型推理速度的重要手段。图形处理单元(GPU)因其并行计算架构,能够快速处理大规模的矩阵运算,这对于深度学习的卷积操作来说是必需的。为了在不同的硬件上部署YOLOv8模型,开发者必须考虑模型在不同计算资源下的优化。例如,NPU(神经网络处理单元)专为深度学习运算设计,拥有更高的能效比和更低的延迟,是许多移动和边缘计算设备的首选。在本小节中,我们将探讨如何为GPU和NPU优化YOLOv8模型,以及如何在硬件级别上进行相应的调整。
#### 代码示例:使用TensorRT对YOLOv8进行GPU加速
```python
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
trt_runtime = trt.Runtime(TRT_LOGGER)
def build_engine(onnx_file_path):
with trt.Builder(TRT_LOGGER) as builder, \
builder.create_network(common.EXPLICIT_BATCH) as network, \
trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_workspace_size = 1 << 30 # 1 GB
builder.max_batch_size = 16
with open(onnx_file_path, 'rb') as model:
if not parser.parse(model.read()):
print('ERROR: Failed to parse the ONNX file.')
for error in range(parser.num_errors):
print(parser.get_error(error))
return None
return builder.build_cuda_engine(network)
# Load the engine from a serialized engine file, if available.
engine_path = "yolov8.trt"
with open(engine_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
context = engine.create_execution_context()
```
在上述代码中,我们首先导入了TensorRT的Python API,并创建了一个运行时实例。接着,我们使用`trt.Builder`创建了一个网络,这个网络会被用来解析ONNX文件,并构建推理引擎。构建过程涉及到设置最大工作空间大小和最大批量大小,这些参数决定了TensorRT的优化程度和性能。最后,我们加载预先构建好的TensorRT模型,准备进行推理。
请注意,这段代码需要在一个已经安装了TensorRT和pycuda库的环境中执行,并且需要一个有效的YOLOv8 ONNX文件作为输入。在实际部署中,开发者需要根据具体的硬件条件调整参数,优化模型以获得最佳性能。
### 3.1.2 移动端部署与优化
移动端部署主要是为了在移动设备或者边缘计算设备上执行模型,这些设备的计算能力和存储空间都比服务器端要有限得多。针对移动端的优化包括模型量化、剪枝和知识蒸馏等策略。通过这些技术,我们可以将YOLOv8模型压缩到一个较小的体积,同时尽量保持准确率,这样就能在资源受限的环境下实现快速推理。
#### 代码示例:使用TensorRT进行模型量化
```python
import tensorrt as trt
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
def build_quantized_engine(onnx_file_path, calib_data_path, output_engine_path):
builder = trt.Builder(TRT_LOGGER)
network = builder.create_network(common.EXPLICIT_BATCH)
parser = trt.OnnxParser(network, TRT_LOGGER)
with open(onnx_file_path, 'rb') as model:
if not parser.parse(model.read()):
print('ERROR: Failed to parse the ONNX file.')
for error in range(parser.num_errors):
print(parser.get_error(error))
return None
config = builder.create_builder_config()
profile = builder.create_network_profile(network)
config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 1 << 30) # 1 GB
config.add_quantization_config(trt.QuantizationConfig(profile))
with open(calib_data_path, 'rb') as f:
calibration_stream = trt.IsEnabled(f.read())
engine = builder.build_engine(network, config)
with open(output_engine_path, "wb") as f:
f.write(engine.serialize())
# Usage example
build_quantized_engine("yolov8.onnx", "calibration.bin", "yolov8_quantized.trt")
```
在该代码段中,我们首先定义了日志记录器TRT_LOGGER,并创建了TensorRT构建器和网络。接着,我们使用ONNX解析器加载了YOLOv8模型,并创建了一个构建配置`config`,其中包括对模型进行量化所需的量化配置。最后,我们使用`builder.build_engine`构建并序列化了一个量化的引擎。请注意,量化通常需要一个校准数据集(calibration data set),用于确定最佳的量化参数。代码中的`calib_data_path`就是校准数据集的路径。
移动端部署的优化技巧还包括模型的剪枝、知识蒸馏,以及专门针对移动设备的网络结构设计,这些都会在后续的小节中详细讨论。
## 3.2 模型压缩与推理速度提升
### 3.2.1 权重量化与剪枝技术
随着模型的增大,参数数量增加,这会导致推理时间和资源消耗的增加,同时影响模型在移动设备上的部署。权重量化与剪枝技术是为了解决这一问题而诞生的。权重量化将浮点数参数转换成低精度的整数参数,可以减少模型大小,加速推理速度,并降低内存占用。而剪枝则是删除网络中不重要的连接,减少参数数量,从而达到压缩模型的目的。
#### 权重量化的逻辑分析和参数说明
量化是一种模型压缩技术,可以将32位浮点参数转换为更低位宽的整数,如INT8或INT16。这种转换利用了深度学习中参数的稀疏性和动态范围,以更少的位数来表示模型参数。量化后的模型占用更少的内存和带宽,加速模型的加载和推理速度,同时还可以利用专门的硬件加速器进行加速,这些加速器通常对低精度计算进行了优化。
在进行权重量化时,需要确定量化的范围和精度。范围通常通过校准数据集来确定,以保证在量化过程中的数值精度损失最小化。精度的选定取决于硬件支持和模型对精度的敏感度。例如,INT8量化通常可以达到与32位浮点数相似的准确度,同时减少存储空间和计算资源的要求。
#### 代码示例:使用TensorFlow模型优化工具进行量化
```python
import tensorflow as tf
from tensorflow.keras.models import load_model
# Load the YOLOv8 model
yolov8_model = load_model('yolov8.h5')
# Convert the model to TensorFlow Lite format
converter = tf.lite.TFLiteConverter.from_keras_model(yolov8_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# Convert and apply quantization to the model
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()
# Save the quantized model
with open('yolov8_quantized.tflite', 'wb') as f:
f.write(tflite_quant_model)
```
在这个代码示例中,我们首先导入了TensorFlow,并加载了YOLOv8模型。然后,我们使用`TFLiteConverter`将模型转换为TensorFlow Lite格式,并应用默认优化。通过设置`supported_types`参数,我们指定了模型应被量化为16位浮点数。最后,我们保存了量化后的模型。请注意,对于不同的硬件平台和优化需求,参数可能需要调整。例如,如果目标平台支持INT8,那么可以通过将`supported_types`设置为`tf.int8`来进一步降低模型大小和加速推理。
### 3.2.2 知识蒸馏的应用实例
知识蒸馏是一种模型压缩技术,其核心思想是将一个大型的、复杂的网络(教师网络)的知识转移到一个小型的、简单的网络(学生网络)中。在这个过程中,学生网络学习模仿教师网络的输出,包括其软预测(soft predictions),而不仅仅是硬决策。这种软预测包含了类别间概率分布的丰富信息,有助于学生网络学到更精细的特征表示。
#### 知识蒸馏的逻辑分析和参数说明
知识蒸馏分为两个主要步骤。首先是训练阶段,其中教师网络生成一个带有额外"温度"参数的软标签,然后训练学生网络去拟合这些软标签,而不仅仅是训练数据的硬标签。温度参数用于平滑概率分布,使得学生网络学习到更加平滑的特征表示。接着是蒸馏阶段,学生网络会在训练集上进行微调,以达到更好的性能。
在实施知识蒸馏时,有几个关键参数需要考虑,比如温度参数的值、蒸馏损失函数的权重、蒸馏的策略等。温度参数决定了软标签的平滑程度,过高的温度会导致类别信息丧失,而过低的温度则相当于没有蒸馏。蒸馏损失函数的权重决定了蒸馏在学生网络训练中的重要性。通常需要在验证集上进行一些实验,以找到最佳的参数设置。
#### 代码示例:使用PyTorch实施知识蒸馏
```python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision.models import resnet18, resnet34
def distill_loss(y_pred_student, y_pred_teacher, y_true, temperature=1.0):
# Softmax with temperature
y_true = nn.functional.softmax(y_true / temperature, dim=-1)
y_pred_student = nn.functional.softmax(y_pred_student / temperature, dim=-1)
y_pred_teacher = nn.functional.softmax(y_pred_teacher / temperature, dim=-1)
# Calculate蒸馏 loss
loss = nn.KLDivLoss(reduction="batchmean")(y_pred_student.log(), y_pred_teacher)
loss += nn.CrossEntropyLoss()(y_pred_student, y_true)
return loss
# Define the teacher and student models
teacher_model = resnet34(pretrained=True)
student_model = resnet18(pretrained=False)
# Prepare data and optimizer
optimizer = optim.Adam(student_model.parameters(), lr=0.001)
# Training loop with distillation
for inputs, labels in data_loader:
optimizer.zero_grad()
outputs_teacher = teacher_model(inputs)
outputs_student = student_model(inputs)
loss = distill_loss(outputs_student, outputs_teacher, labels)
loss.backward()
optimizer.step()
```
在上述代码段中,我们定义了一个`distill_loss`函数,它计算了蒸馏损失,由交叉熵损失和Kullback-Leibler散度(KL散度)损失组合而成。在训练循环中,我们首先将输入数据通过教师网络和学生网络,然后计算损失函数,并进行反向传播和权重更新。这种方法有助于学生网络学习到教师网络的软预测,从而提升模型的性能和泛化能力。
通过上述技巧的应用,YOLOv8模型可以被有效地压缩,以便在资源受限的环境中部署。量化和剪枝是减少模型大小和加速推理的关键技术,而知识蒸馏则有助于保持模型在压缩过程中的准确性。
## 3.3 模型训练与优化的技巧
### 3.3.1 超参数调优的策略
深度学习模型的性能极大地依赖于超参数的选择。超参数是模型训练之前设定的参数,它们控制了学习过程,例如学习率、批大小、优化器类型等。正确选择超参数是提高模型性能、加速收敛以及避免过拟合的关键。
#### 超参数调优的逻辑分析和参数说明
调优超参数是一个实验性的过程,需要在验证集上测试不同超参数设置的效果。学习率是最重要的超参数之一,它决定了权重更新的幅度。一个过高的学习率可能导致模型无法收敛,而过低的学习率则会导致训练过程缓慢或者陷入局部最小值。批大小决定了每次训练时使用多少个样本,这影响到梯度估计的准确性和内存使用。优化器的选择(例如SGD、Adam、RMSprop等)则影响着权重更新的方向和幅度。
调优超参数的常用方法包括网格搜索(Grid Search)、随机搜索(Random Search)和贝叶斯优化。网格搜索尝试了参数空间中的每一个组合,而随机搜索则在参数空间中随机选择组合,贝叶斯优化则使用了贝叶斯推理来智能地选择参数组合。
#### 代码示例:使用Keras Tuner进行超参数调优
```python
import keras_tuner as kt
def build_model(hp):
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(
filters=hp.Int('filters', min_value=32, max_value=256, step=32),
kernel_size=hp.Int('kernel_size', min_value=3, max_value=5),
activation='relu',
input_shape=(300, 300, 3)))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(
units=hp.Int('units', min_value=32, max_value=512, step=32),
activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.compile(
optimizer=tf.keras.optimizers.Adam(
hp.Float('learning_rate', min_value=1e-4, max_value=1e-2, sampling='LOG')),
loss='binary_crossentropy',
metrics=['accuracy'])
return model
# Define the model tuner
tuner = kt.RandomSearch(
build_model,
objective=kt.Objective("val_accuracy", direction="max"),
max_trials=10,
executions_per_trial=3,
directory="my_dir",
project_name="yolov8_tuning")
# Perform hyperparameter search
tuner.search_space_summary()
tuner.search(x_train, y_train, epochs=10, validation_data=(x_val, y_val))
# Retrieve the best hyperparameters
best_hps = tuner.get_best_hyperparameters(num_trials=1)[0]
```
在这个例子中,我们使用了Keras Tuner库来自动搜索最佳的超参数配置。首先定义了一个构建模型的函数`build_model`,该函数接收超参数(hp)作为输入,并构建了一个卷积神经网络模型。我们使用了Keras Tuner提供的`RandomSearch`方法来搜索最佳的超参数配置,其中包括滤波器数量、内核大小、全连接层单元数和学习率。最后,我们通过调用`tuner.search`方法开始搜索过程,并获取最佳的超参数配置。
### 3.3.2 正则化方法与避免过拟合
为了避免深度学习模型在训练数据上过拟合,我们可以采用一系列正则化方法。正则化是通过向模型损失函数中添加附加项来惩罚过大的权重,从而减少模型复杂性,并鼓励模型学习更平滑的决策边界。
#### 正则化方法的逻辑分析和参数说明
最常见的正则化方法包括L1和L2正则化、Dropout和数据增强。L1和L2正则化通过向损失函数添加权重的绝对值或平方和来工作,这鼓励模型学习更加稀疏或平滑的权重矩阵。Dropout是一种在训练过程中随机丢弃网络中的一些神经元的方法,这迫使网络学习更加鲁棒的特征表示。数据增强通过在输入数据上应用变换(如旋转、缩放、裁剪等)来增加训练集的多样性,从而减少过拟合的风险。
正则化参数,如L1和L2的权重衰减系数,Dropout的比例以及数据增强的变换策略,都需要根据具体问题和数据集进行调整。正则化参数的不当选择可能会导致模型欠拟合或者过拟合。
#### 代码示例:使用Dropout进行正则化
```python
from keras.layers import Dropout
from keras.models import Sequential
from keras.layers import Dense
# Define the model with Dropout layers
model = Sequential()
model.add(Dense(64, input_shape=(784,), activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='softmax'))
# Compile the model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# Train the model with Dropout layers
model.fit(x_train, y_train, epochs=10, batch_size=128, validation_data=(x_test, y_test))
```
在上述代码段中,我们构建了一个简单的全连接神经网络模型,并在两个隐藏层之间添加了Dropout层。每个Dropout层随机丢弃20%的输入单元,以防止网络学习到过于复杂的特征表示。接着,我们编译并训练了模型,在训练过程中,Dropout层在每个epoch中都会更新其被丢弃的单元。通过这种方法,模型可以更好地泛化到未见过的数据上。
通过超参数调优和正则化方法的应用,我们可以优化YOLOv8模型的训练过程,提高模型在测试集上的性能,避免过拟合,并加速训练收敛。
在本章节的介绍中,我们深入探讨了YOLOv8在性能优化方面的实践技巧,涵盖了硬件加速、模型压缩、超参数调优和避免过拟合等多个方面。这些优化措施不仅提升了模型在各类硬件上的部署能力,还提高了模型在实际应用中的准确性和鲁棒性。随着深度学习技术的不断发展,这些优化技巧也在不断地演进,为YOLOv8等先进模型的落地应用提供了坚实的技术支持。
# 4. 性能提升对比分析
## 基准测试与性能指标
### 常见的性能评估指标
在评估目标检测算法如YOLOv8的性能时,基准测试是不可或缺的一环。基准测试关注的性能指标主要包括精确度、速度和资源消耗。精确度通常通过准确率(Precision)、召回率(Recall)和平均精度均值(mAP)等指标来衡量。精确度指标反映了模型对于目标检测的准确性,而速度指标(如每秒帧数FPS)则决定了模型在实时系统中的可行性。资源消耗则涉及到模型在特定硬件上的内存占用和推理时间。
例如,在视频监控场景中,模型的实时性能尤为重要,因为需要快速响应并作出判断。而在自动驾驶等场景,除了速度和精确度之外,系统的鲁棒性和在极端环境下的表现也是评估的关键。
```markdown
| 性能指标 | 描述 |
| --- | --- |
| 准确率 (Precision) | 正确检测出的目标与检测出目标总数的比值 |
| 召回率 (Recall) | 正确检测出的目标与真实目标总数的比值 |
| 平均精度均值 (mAP) | 在不同阈值下的平均精确度的平均值 |
| 每秒帧数 (FPS) | 模型每秒处理的图像数量 |
```
### 不同环境下的性能测试
为了全面评估YOLOv8的性能,需要在不同的硬件平台和软件环境中进行测试。例如,在GPU、CPU和嵌入式设备上分别运行模型,以测试其在不同计算资源下的表现。同时,软件环境的测试也至关重要,需要确保YOLOv8能够兼容不同的深度学习框架和版本。
通过不同环境下的性能测试,我们可以了解YOLOv8的适应性,以及在特定条件下可能遇到的问题。例如,在某些特定型号的GPU上,模型可能会遇到驱动兼容性问题,或者在老版本的深度学习框架上无法运行某些优化过的算子。
## YOLOv8与前代版本的对比分析
### 特征提取能力对比
YOLOv8作为系列算法的最新版本,其在特征提取能力上有了显著的提升。特征提取是目标检测的核心,它直接影响到检测的准确性和速度。与前代版本相比,YOLOv8在特征提取框架上进行了优化和增强,例如引入了多尺度特征融合技术,使得模型能够在不同尺度上捕获更丰富的上下文信息。
在进行对比分析时,我们可以选取一组标准的测试数据集,如PASCAL VOC、COCO等,使用相同的训练配置和测试流程来评估各个版本的YOLO算法。通过这种方式,我们可以得到一个量化的对比结果,了解YOLOv8在特征提取方面相对于前代版本的具体提升。
### 性能优化效果对比
随着算法的演进,YOLOv8在性能优化方面也做出了显著的努力。通过改进非极大值抑制(NMS)、引入深度可分离卷积等技术,YOLOv8在保持高精确度的同时,提升了模型的运行速度和效率。与前代版本相比,YOLOv8在相同的硬件条件下,往往能提供更快的推理速度和更低的延迟。
对比分析可以通过实际的性能测试数据进行,例如,在同一硬件平台上,记录不同模型的FPS以及处理特定任务所需的平均时间。这样的对比可以直观地显示出YOLOv8相对于前代版本的性能提升。
## 实际应用场景下的优化实例
### 视频监控中的应用
在视频监控的应用中,YOLOv8的性能提升尤为明显。首先,通过优化后的多尺度特征提取和精确的目标定位,YOLOv8能够在高分辨率视频中快速准确地检测出目标。其次,模型对动态场景和复杂背景的适应能力也得到了提升,这使得在交通监控、人群监控等场景下,YOLOv8能提供更加稳定和准确的结果。
### 自动驾驶场景的挑战与应用
在自动驾驶领域,YOLOv8面临的挑战更大,因为这里的检测准确性和响应速度对安全性有着直接的影响。通过引入更深的网络层次、更高效的特征提取机制,YOLOv8在自动驾驶领域实现了高精度的目标检测。与此同时,YOLOv8在移动和边缘设备上的部署能力,使得自动驾驶系统能在资源有限的设备上运行,这对于商业化落地具有重要的意义。
```mermaid
graph LR
A[YOLOv8部署] --> B[自动驾驶系统]
B --> C[实时目标检测]
C --> D[行驶决策]
```
YOLOv8的这些优化不仅推动了自动驾驶技术的发展,也为相关领域的研究提供了新的视角和方法。
通过这些实际应用场景下的优化实例,我们可以看到YOLOv8在目标检测领域实现的诸多突破,并进一步理解了YOLOv8在不同实际应用中的潜力和价值。
# 5. YOLOv8的未来发展方向与挑战
YOLOv8作为当前目标检测领域的一个重要里程碑,虽然在诸多方面取得了突破性进展,但仍然存在一定的局限性,并且随着技术的发展和应用场景的不断扩展,其未来的方向和挑战也逐渐浮现。本章将深入探讨YOLOv8的局限性与改进空间,讨论其在新兴领域的应用前景,并探索可能的创新路径。
## 5.1 YOLOv8的局限性与改进空间
### 5.1.1 模型泛化能力的局限
YOLOv8虽然在多个标准数据集上表现出了优越的性能,但在面对某些特殊场景时,其泛化能力仍然有待提高。一个主要的问题是如何使YOLOv8更好地适应各种复杂和多变的现实世界环境。例如,光照变化、目标遮挡、场景混乱等因素都会对目标检测的准确性造成影响。针对这些问题,研究者们可以考虑以下几个方向:
- **数据增强策略**:引入更具挑战性的数据增强方法,如模拟极端光照条件、增加噪声干扰等,以提高模型对于不同环境变化的适应能力。
- **自适应机制**:开发模型中的自适应机制,使其能够根据输入数据的不同自动调整检测策略,以应对复杂的现实场景。
### 5.1.2 实时性能优化的方向
虽然YOLOv8在实时目标检测方面已经领先于很多其他算法,但随着应用场景对实时性的要求越来越高,YOLOv8的实时性能优化还有很大的空间。在实际部署中,模型需要在不同的硬件平台上运行,包括但不限于CPU、GPU、NPU等。针对实时性能的优化,可以从以下几个方面入手:
- **模型轻量化**:通过剪枝、量化等技术进一步减小模型的计算量和参数量,以适应低功耗和低资源消耗的硬件设备。
- **算法优化**:对YOLOv8中的关键算法进行优化,比如研究更高效的特征提取方法和更快速的推理策略。
## 5.2 YOLOv8在新兴领域的应用前景
### 5.2.1 深度学习的进一步融合
随着深度学习技术的快速发展,YOLOv8在未来可以进一步与其他深度学习分支相结合,为特定应用场景带来更多的可能性。例如:
- **多模态学习**:结合视觉以外的其他模式数据(如文本、音频),使YOLOv8能够处理更加复杂的任务。
- **生成对抗网络(GAN)**:利用GAN生成更多具有挑战性的训练数据,或者开发YOLOv8的对抗样本检测能力。
### 5.2.2 边缘计算与云平台的结合
在边缘计算和云计算日益融合的今天,YOLOv8的部署策略也需要适应这种趋势。一方面,YOLOv8可以在边缘设备上进行轻量级部署,实现快速的本地响应;另一方面,其计算能力可以通过云计算资源得到增强,处理更加复杂和大规模的任务。结合策略可能包括:
- **联合推理**:边缘设备和云平台联合完成推理任务,根据任务的实时性和计算量需求动态调整推理位置。
- **模型分割**:将YOLOv8分割为多个子模型,轻量级部分部署在边缘端,复杂部分则由云平台处理。
## 5.3 探索YOLOv8的创新路径
### 5.3.1 结合其他深度学习模型的优势
未来的YOLOv8可以吸收其他深度学习模型的优势,比如Transformer在序列建模方面的优越性,以此来提升其特征提取和信息融合的能力。研究者可以尝试将YOLOv8与其他模型进行融合,例如:
- **Transformer融合**:将YOLOv8中的卷积层与Transformer结构相结合,改进其特征编码方式,增强模型对于长距离依赖关系的捕捉能力。
- **多尺度融合网络**:探索更高效的多尺度特征融合方法,使得YOLOv8能够在不同尺度上获取更丰富的上下文信息。
### 5.3.2 模型透明度与可解释性的提升
随着模型应用的不断深入,提高模型的透明度和可解释性变得越来越重要。这不仅有助于我们更好地理解模型的决策过程,也对于提升用户信任和满足法规要求至关重要。为此,可以采取以下措施:
- **可视化技术**:开发和优化可视化工具,将YOLOv8在检测过程中的关键特征和决策路径更加直观地展现出来。
- **解释性模型**:引入或构建解释性较强的辅助模型,用来解释和验证YOLOv8的检测结果,提升整体模型的可信赖度。
在以上章节内容中,我们分析了YOLOv8在当前的局限性、面临的挑战以及未来的发展方向。从模型泛化能力的提升到实时性能的优化,再到深度学习技术的融合和创新路径的探索,YOLOv8的未来充满了无限可能。通过对现有技术和策略的持续迭代,我们可以期待YOLOv8在未来在目标检测领域能够发挥更大的作用,并拓展到更多新兴应用领域中。
# 6. 综合应用:构建与部署YOLOv8的端到端解决方案
## 6.1 YOLOv8环境搭建与数据准备
### 6.1.1 构建深度学习工作环境
构建YOLOv8所需的深度学习工作环境首先需要确定系统配置,包括操作系统(如Ubuntu 18.04或更高版本)、适当的CUDA版本(推荐11.1或更高)、cuDNN(推荐CUDA对应的版本),以及安装Python环境。
接下来是通过包管理器安装必要的库。对于YOLOv8,推荐使用以下命令通过conda环境进行安装:
```bash
conda create -n yolov8 python=3.8
conda activate yolov8
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch -c nvidia
pip install scikit-learn opencv-python matplotlib
```
在安装完基础库后,就可以开始安装YOLOv8的依赖项。这可能包括其他自定义的库,如`tensorboard`用于日志查看,以及`onnx`和`onnx-simplifier`用于模型转换。
### 6.1.2 数据预处理与增强技术
数据是深度学习项目成功的关键因素之一。为YOLOv8准备数据包括标注、格式化、归一化及增强技术。
- **标注**:通常使用诸如LabelImg的工具进行标注,生成对应的标注文件(如VOC格式或YOLO格式)。
- **格式化**:将数据组织成YOLOv8模型可以接受的格式,通常包括图片文件和对应的标注信息文件。
- **归一化**:将图片像素值归一化到0-1之间,有助于提升模型训练的稳定性。
- **增强技术**:数据增强通过改变图片的大小、旋转、裁剪等方式扩充数据集,提高模型的泛化能力。例如使用`torchvision.transforms`:
```python
import torchvision.transforms as T
data_transforms = T.Compose([
T.Resize((256, 256)),
T.RandomRotation(degrees=(0, 180)),
T.RandomCrop(224),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
```
数据准备是深度学习项目中耗时且关键的一步,对最终模型的性能有着决定性的影响。上述步骤为构建和部署YOLOv8的端到端解决方案打下了坚实的基础。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏深入剖析了 YOLOv8 目标检测算法的特征提取机制,并提供专家级实战教程。通过行业案例和实战指南,专栏揭秘了 YOLOv8 的特征提取技术,并分析了其在对抗样本和模型压缩方面的策略。此外,专栏还详细阐述了 YOLOv8 中的注意力机制和多尺度处理技术,帮助读者全面理解 YOLOv8 的强大性能和广泛应用。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Vue Select选择框数据监听秘籍:掌握数据流与$emit通信机制

# 摘要
本文深入探讨了Vue框架中Select组件的数据绑定和通信机制。从Vue Select组件与数据绑定的基础开始,文章逐步深入到Vue的数据响应机制,详细解析了响应式数据的初始化、依赖追踪,以及父子组件间的数据传递。第三章着重于Vue Select选择框的动态数据绑定,涵盖了高级用法、计算属性的优化,以及数据变化监听策略。第四章则专注于实现Vue Se
【操作秘籍】:施耐德APC GALAXY5000 UPS开关机与故障处理手册
# 摘要
本文对施耐德APC GALAXY5000 UPS进行全面介绍,涵盖了设备的概述、基本操作、故障诊断与处理、深入应用与高级管理,以及案例分析与用户经验分享。文章详细说明了UPS的开机、关机、常规检查、维护步骤及监控报警处理流程,同时提供了故障诊断基础、常见故障排除技巧和预防措施。此外,探讨了高级开关机功能、与其他系统的集成以及高级故障处理技术。最后,通过实际案例和用户经验交流,强调了该UPS在不同应用环境中的实用性和性能优化。
# 关键字
UPS;施耐德APC;基本操作;故障诊断;系统集成;案例分析
参考资源链接:[施耐德APC GALAXY5000 / 5500 UPS开关机步骤
wget自动化管理:编写脚本实现Linux软件包的批量下载与安装
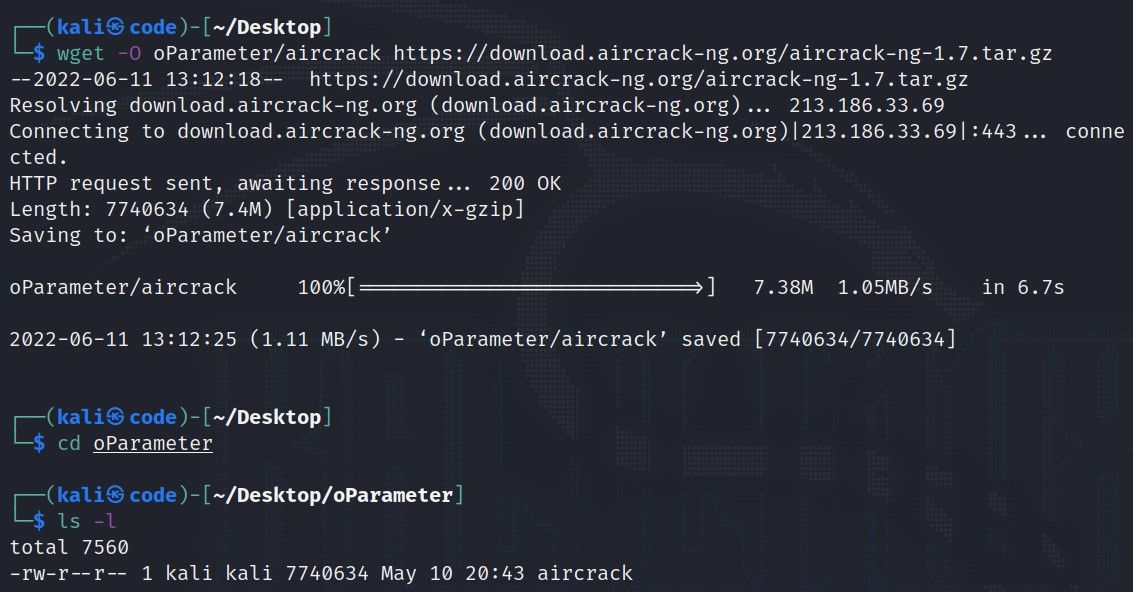
# 摘要
本文对wget工具的自动化管理进行了系统性论述,涵盖了wget的基本使用、工作原理、高级功能以及自动化脚本的编写、安装、优化和安全策略。首先介绍了wget的命令结构、选项参数和工作原理,包括支持的协议及重试机制。接着深入探讨了如何编写高效的自动化下载脚本,包括脚本结构设计、软件包信息解析、批量下载管理和错误
Java中数据结构的应用实例:深度解析与性能优化
# 摘要
本文全面探讨了Java数据结构的理论与实践应用,分析了线性数据结构、集合框架、以及数据结构与算法之间的关系。从基础的数组、链表到复杂的树、图结构,从基本的集合类到自定义集合的性能考量,文章详细介绍了各个数据结构在Java中的实现及其应用。同时,本文深入研究了数据结构在企业级应用中的实践,包括缓存机制、数据库索引和分布式系统中的挑战。文章还提出了Java性能优化的最佳实践,并展望了数据结构在大数据和人
SPiiPlus ACSPL+变量管理实战:提升效率的最佳实践案例分析

# 摘要
SPiiPlus ACSPL+是一种先进的控制系统编程语言,广泛应用于自动化和运动控制领域。本文首先概述了SPiiPlus ACSPL+的基本概念与变量管理基础,随后深入分析了变量类型与数据结构,并探讨了实现高效变量管理的策略。文章还通过实战技巧,讲解了变量监控、调试、性能优化和案例分析,同时涉及了高级应用,如动态内存管理、多线程变量同步以及面向对象的变
DVE基础入门:中文版用户手册的全面概览与实战技巧

# 摘要
本文旨在为初学者提供DVE(文档可视化编辑器)的入门指导和深入了解其高级功能。首先,概述了DVE的基础知识,包括用户界面布局和基本编辑操作,如文档的创建、保存、文本处理和格式排版。接着,本文探讨了DVE的高级功能,如图像处理、高级文本编辑技巧和特殊功能的使用。此外,还介绍了DVE的跨平台使用和协作功能,包括多用户协作编辑、跨平台兼容性以及与其他工具的整合。最后,通过
【Origin图表专业解析】:权威指南,坐标轴与图例隐藏_显示的实战技巧

# 摘要
本文系统地介绍了Origin软件中图表的创建、定制、交互功能以及性能优化,并通过多个案例分析展示了其在不同领域中的应用。首先,文章对Origin图表的基本概念、坐标轴和图例的显示与隐藏技巧进行了详细介绍,接着探讨了图表高级定制与性能优化的方法。文章第四章结合实战案例,深入分析了O
EPLAN Fluid团队协作利器:使用EPLAN Fluid提高设计与协作效率
# 摘要
EPLAN Fluid是一款专门针对流体工程设计的软件,它能够提供全面的设计解决方案,涵盖从基础概念到复杂项目的整个设计工作流程。本文从EPLAN Fluid的概述与基础讲起,详细阐述了设计工作流程中的配置优化、绘图工具使用、实时协作以及高级应用技巧,如自定义元件管理和自动化设计。第三章探讨了项目协作机制,包括数据管理、权限控制、跨部门沟通和工作流自定义。通过案例分析,文章深入讨论
【数据迁移无压力】:SGP.22_v2.0(RSP)中文版的平滑过渡策略

# 摘要
本文深入探讨了数据迁移的基础知识及其在实施SGP.22_v2.0(RSP)迁移时的关键实践。首先,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )