【Python医学简单代码入门指南】:零基础快速上手医学数据分析
发布时间: 2024-06-20 03:26:21 阅读量: 142 订阅数: 39 

快速入门Python培训教程 Python基础入门教程 Python入门数据分析与机器学习学习路线 共63页.pptx
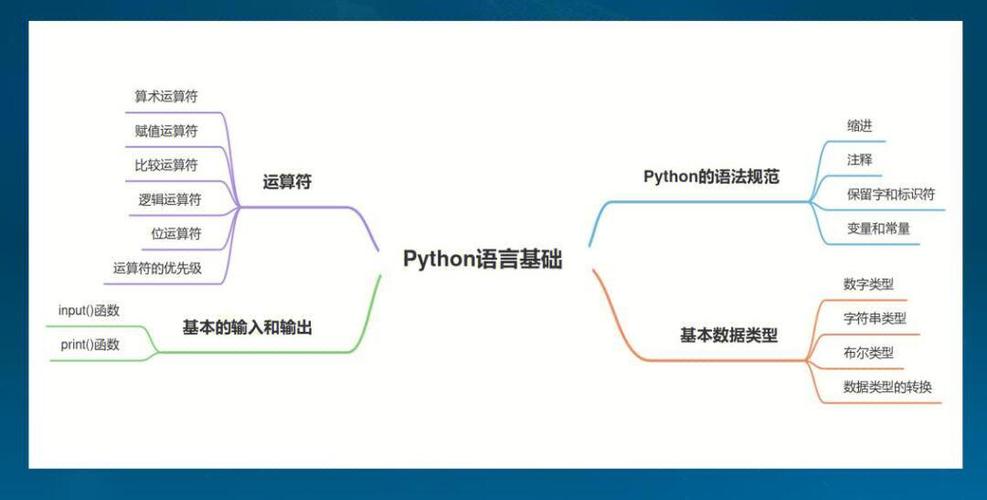
# 1. Python医学数据分析基础
医学数据分析是利用Python编程语言来处理、分析和建模医学数据,从而提取有价值的见解和预测结果。Python提供了一系列强大的库和工具,使其成为医学数据分析的理想选择。
### 1.1 医学数据的类型
医学数据可以分为两大类:结构化数据和非结构化数据。结构化数据具有预定义的格式,如电子表格或数据库中的数据。非结构化数据则没有预定义的格式,如文本、图像和视频。
### 1.2 Python医学数据分析库
Python提供了广泛的库来支持医学数据分析,包括:
- NumPy:用于处理数值数据
- Pandas:用于处理表格数据
- Scikit-learn:用于机器学习建模
- PyTorch:用于深度学习建模
- TensorFlow:用于深度学习建模
# 2. Python医学数据预处理
医学数据预处理是医学数据分析的重要步骤,其目的是将原始医学数据转化为适合建模和分析的形式。本节将介绍医学数据预处理中常用的技术,包括数据清洗和转换、特征工程等。
### 2.1 数据清洗和转换
数据清洗和转换是医学数据预处理的第一步,其目的是去除数据中的噪声、缺失值和不一致性,并将其转换为适合建模和分析的形式。
#### 2.1.1 缺失值处理
缺失值是医学数据中常见的现象,其原因可能是患者拒绝回答、数据收集错误或数据丢失等。缺失值的存在会影响模型的准确性,因此需要进行适当的处理。常用的缺失值处理方法包括:
- **删除缺失值:**如果缺失值较少,且对模型的影响较小,可以将其删除。
- **均值/中位数填充:**对于数值型数据,可以使用均值或中位数填充缺失值。
- **众数填充:**对于类别型数据,可以使用众数填充缺失值。
- **K近邻填充:**使用与缺失值相似的K个样本的平均值或中位数填充缺失值。
```python
import numpy as np
import pandas as pd
# 创建一个包含缺失值的 DataFrame
df = pd.DataFrame({
"Age": [20, 25, 30, np.nan, 35],
"Gender": ["M", "F", "M", "F", np.nan],
"Height": [1.75, 1.65, 1.80, np.nan, 1.70]
})
# 使用均值填充缺失值
df["Age"].fillna(df["Age"].mean(), inplace=True)
# 使用众数填充缺失值
df["Gender"].fillna(df["Gender"].mode()[0], inplace=True)
# 使用 KNN 填充缺失值
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=2)
df["Height"] = imputer.fit_transform(df["Height"].values.reshape(-1, 1))
```
#### 2.1.2 数据类型转换
医学数据中包含各种数据类型,包括数值型、类别型和日期型等。在建模和分析之前,需要将数据转换为适合模型输入的形式。常用的数据类型转换方法包括:
- **数值型转换:**将字符串型数据转换为数值型数据,例如使用 `int()` 或 `float()` 函数。
- **类别型转换:**将数值型数据转换为类别型数据,例如使用 `pd.Categorical()` 函数。
- **日期型转换:**将字符串型日期数据转换为日期型数据,例如使用 `pd.to_datetime()` 函数。
```python
# 将字符串型年龄数据转换为数值型
df["Age"] = df["Age"].astype(int)
# 将数值型性别数据转换为类别型
df["Gender"] = df["Gender"].astype("category")
# 将字符串型日期数据转换为日期型
df["Date"] = pd.to_datetime(df["Date"])
```
### 2.2 特征工程
特征工程是医学数据预处理的重要组成部分,其目的是从原始数据中提取有价值的特征,以提高模型的性能。常用的特征工程技术包括特征选择和特征提取。
#### 2.2.1 特征选择
特征选择是选择对模型预测结果影响最大的特征的过程。常用的特征选择方法包括:
- **Filter 方法:**基于统计指标(如方差、信息增益)选择特征。
- **Wrapper 方法:**基于模型性能选择特征。
- **Embedded 方法:**在模型训练过程中选择特征。
```python
# 使用 Filter 方法选择特征
from sklearn.feature_selection import SelectKBest, chi2
selector = SelectKBest(chi2, k=5)
X_new = selector.fit_transform(X, y)
# 使用 Wrapper 方法选择特征
from sklearn.feature_selection import RFE
selector = RFE(estimator=RandomForestClassifier(), n_features_to_select=5)
selector.fit(X, y)
X_new = selector.transform(X)
# 使用 Embedded 方法选择特征
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X, y)
X_new = model.coef_
```
#### 2.2.2 特征提取
特征提取是将原始特征组合成新特征的过程,以提高模型的泛化能力。常用的特征提取方法包括:
- **主成分分析(PCA):**将高维数据投影到低维空间。
- **线性判别分析(LDA):**将数据投影到类间差异最大的方向。
- **奇异值分解(SVD):**将数据分解为奇异值、左奇异向量和右奇异向量。
```python
# 使用 PCA 进行特征提取
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_new = pca.fit_transform(X)
# 使用 LDA 进行特征提取
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
lda = LinearDiscriminantAnalysis(n_components=2)
X_new = lda.fit_transform(X, y)
# 使用 SVD 进行特征提取
from sklearn.decomposition import TruncatedSVD
svd = TruncatedSVD(n_components=2)
X_new = svd.fit_transform(X)
```
# 3.1 监督学习
监督学习是一种机器学习方法,它使用标记数据来训练模型。标记数据是指已知输入和输出的数据集。监督学习模型学习从输入数据预测输出数据的映射。
#### 3.1.1 分类算法
分类算法用于预测类别变量的输出。常见的分类算法包括:
- **逻辑回归:**一种线性分类器,使用逻辑函数对输入数据进行建模。
- **决策树:**一种树形结构,其中每个节点代表一个特征,每个分支代表一个决策。
- **支持向量机:**一种非线性分类器,通过在数据点之间找到最大间隔来创建决策边界。
- **随机森林:**一种集成算法,它通过训练多个决策树并组合它们的预测来提高准确性。
#### 3.1.2 回归算法
回归算法用于预测连续变量的输出。常见的回归算法包括:
- **线性回归:**一种线性模型,使用一条直线对输入数据进行建模。
- **多项式回归:**一种非线性模型,使用多项式方程对输入数据进行建模。
- **决策树回归:**一种树形结构,其中每个节点代表一个特征,每个分支代表一个预测。
- **支持向量回归:**一种非线性回归器,通过在数据点之间找到最大间隔来创建预测边界。
#### 代码示例:使用逻辑回归进行分类
```python
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
# 加载数据
data = pd.read_csv('medical_data.csv')
# 分离特征和标签
X = data.drop('label', axis=1)
y = data['label']
# 训练模型
model = LogisticRegression()
model.fit(X, y)
# 预测新数据
new_data = np.array([[10, 20, 30]])
prediction = model.predict(new_data)
# 打印预测结果
print(prediction)
```
**代码逻辑分析:**
1. 使用 `pandas` 加载数据并分离特征和标签。
2. 使用 `sklearn` 的逻辑回归模型训练模型。
3. 使用训练好的模型对新数据进行预测。
4. 打印预测结果。
**参数说明:**
- `LogisticRegression()`:创建一个逻辑回归模型。
- `fit(X, y)`:使用特征 `X` 和标签 `y` 训练模型。
- `predict(new_data)`:使用训练好的模型对新数据进行预测。
# 4. Python医学数据分析实战
### 4.1 医学影像分析
#### 4.1.1 图像分割
**简介**
医学影像分割是将医学图像中的感兴趣区域(ROI)从背景中分离出来的过程。它在疾病诊断、治疗规划和手术导航中至关重要。
**方法**
图像分割方法可分为以下几类:
- **基于阈值的分割:**将图像像素分为前景和背景,基于像素强度或其他特征。
- **区域生长分割:**从种子点开始,将具有相似特征的像素聚集成区域。
- **边缘检测分割:**检测图像中的边缘,然后将边缘连接起来形成封闭的区域。
- **深度学习分割:**使用卷积神经网络(CNN)自动学习图像特征并进行分割。
**代码示例:**
```python
import numpy as np
from skimage import io, segmentation
# 读取图像
image = io.imread("medical_image.jpg")
# 基于阈值的分割
mask = segmentation.threshold_otsu(image)
# 显示结果
io.imshow(mask)
io.show()
```
**逻辑分析:**
* `threshold_otsu` 函数使用 Otsu 阈值算法将图像像素分为前景和背景。
* `imshow` 和 `show` 函数用于显示分割结果。
#### 4.1.2 图像分类
**简介**
医学图像分类是将医学图像分配到特定类别(例如,正常或异常)的任务。它用于疾病筛查、诊断和预后。
**方法**
图像分类方法可分为以下几类:
- **传统机器学习方法:**使用手工提取的特征和分类器(如支持向量机)。
- **深度学习方法:**使用 CNN 自动学习图像特征和进行分类。
**代码示例:**
```python
import numpy as np
import tensorflow as tf
# 准备数据
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 创建模型
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=10)
# 评估模型
model.evaluate(x_test, y_test)
```
**逻辑分析:**
* `load_data` 函数加载 MNIST 数据集,其中包含手写数字图像和标签。
* `Sequential` 类创建了一个顺序模型,其中包含一个展平层、一个隐藏层和一个输出层。
* `compile` 函数编译模型,指定优化器、损失函数和度量指标。
* `fit` 函数训练模型,使用训练数据更新模型权重。
* `evaluate` 函数评估模型,使用测试数据计算损失和准确度。
### 4.2 电子病历分析
#### 4.2.1 文本挖掘
**简介**
电子病历文本挖掘是从电子病历中提取有价值信息的自动化过程。它用于疾病诊断、风险评估和决策支持。
**方法**
文本挖掘方法可分为以下几类:
- **信息提取:**从文本中识别和提取特定实体(例如,疾病、药物、症状)。
- **主题建模:**发现文本中的潜在主题或模式。
- **情感分析:**分析文本中的情绪和观点。
**代码示例:**
```python
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# 读取文本
text = open("medical_record.txt").read()
# 分词
tokens = word_tokenize(text)
# 去除停用词
stop_words = set(stopwords.words('english'))
tokens = [token for token in tokens if token not in stop_words]
# 提取实体
entities = nltk.ne_chunk(tokens)
```
**逻辑分析:**
* `open` 函数读取电子病历文本。
* `word_tokenize` 函数将文本分词。
* `set` 函数创建停用词集合。
* `ne_chunk` 函数提取命名实体。
#### 4.2.2 自然语言处理
**简介**
自然语言处理(NLP)是计算机理解和生成人类语言的能力。它用于电子病历的摘要、问答和聊天机器人。
**方法**
NLP 方法可分为以下几类:
- **语言模型:**学习单词序列的概率分布,用于文本生成和预测。
- **词嵌入:**将单词表示为低维向量,用于语义相似性和关系建模。
- **机器翻译:**将一种语言的文本翻译成另一种语言。
**代码示例:**
```python
import transformers
# 加载预训练语言模型
model = transformers.AutoModelForSeq2SeqLM.from_pretrained("t5-small")
# 生成摘要
input_text = "This is a medical record for a patient with diabetes."
output_text = model.generate(input_text, max_length=128)
```
**逻辑分析:**
* `AutoModelForSeq2SeqLM` 类加载预训练的 T5 语言模型。
* `generate` 函数生成文本摘要,指定最大长度。
# 5. Python医学数据分析应用
### 5.1 疾病诊断
#### 5.1.1 机器学习模型的应用
机器学习模型在医学数据分析中得到了广泛应用,特别是在疾病诊断领域。通过训练机器学习模型,我们可以基于患者的医学数据(例如,电子病历、影像数据)预测或分类疾病。
**具体应用:**
- **疾病风险预测:**建立模型预测患者患特定疾病的风险,例如,心血管疾病、癌症。
- **疾病分类:**将患者分为不同的疾病类别,例如,根据症状和影像数据区分不同类型的癌症。
- **疾病进展预测:**预测疾病的进展情况,例如,评估患者癌症复发的可能性。
#### 5.1.2 深度学习模型的应用
深度学习模型在医学图像分析领域取得了显著进展,为疾病诊断提供了新的方法。深度学习模型可以自动从医学图像中提取特征,并用于疾病诊断和分类。
**具体应用:**
- **医学影像分割:**分割医学图像中的不同解剖结构,例如,分割肿瘤区域。
- **医学影像分类:**根据医学图像分类疾病,例如,根据胸部 X 射线图像分类肺炎。
- **疾病检测:**检测医学图像中的疾病,例如,检测皮肤癌或糖尿病视网膜病变。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“Python医学简单代码”专栏,一个专为初学者和医学专业人士设计的指南,旨在让您快速上手医学数据分析。本专栏涵盖了从数据预处理到模型训练、自然语言处理到深度学习等广泛主题,并提供逐步指南和示例代码,帮助您轻松掌握医学数据分析的各个方面。通过本专栏,您将了解如何利用Python的力量来处理医学数据、构建预测模型、可视化结果并利用人工智能、大数据和云计算等先进技术来推进医学研究和实践。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【EmuELEC全面入门与精通】:打造个人模拟器环境(7大步骤)

# 摘要
EmuELEC是一款专为游戏模拟器打造的嵌入式Linux娱乐系统,旨在提供一种简便、快速的途径来设置和运行经典游戏机模拟器。本文首先介绍了EmuELEC的基本概念、硬件准备、固件获取和初步设置。接着,深入探讨了如何定制EmuELEC系统界面,安装和配置模拟器核心,以及扩展其功能。文章还详细阐述了游戏和媒体内容的管理方法,包括游戏的导入、媒体内容的集成和网络功能的
【TCAD仿真流程全攻略】:掌握Silvaco,构建首个高效模型
# 摘要
本文首先介绍了TCAD仿真和Silvaco软件的基础知识,然后详细讲述了如何搭建和配置Silvaco仿真环境,包括软件安装、环境变量设置、工作界面和仿真
【数据分析必备技巧】:0基础学会因子分析,掌握数据背后的秘密
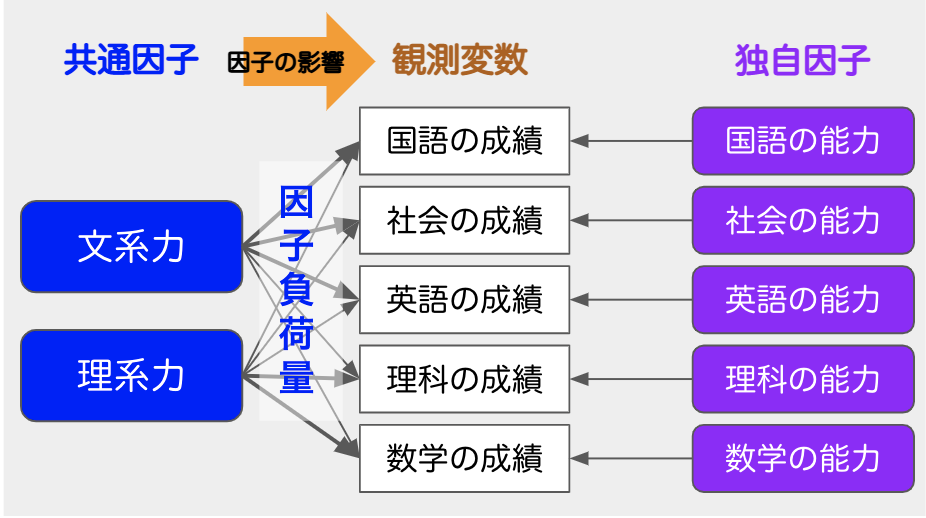
# 摘要
因子分析是一种强有力的统计方法,被广泛用于理解和简化数据结构。本文首先概述了因子分析的基本概念和统计学基础,包括描述性统计、因子分析理论模型及适用场景。随后,文章详细介绍了因子分析的实际操作步骤,如数据的准备、预处理和应用软件操作流程,以及结果的解读与报告撰写。通过市场调研、社会科学统计和金融数据分析的案例实战,本文展现了因子分析在不同领域的应用价值。最后,文章探讨了因子分析
【树莓派声音分析宝典】:从零开始用MEMS麦克风进行音频信号处理

# 摘要
本文详细介绍了基于树莓派的MEMS麦克风音频信号获取、分析及处理技术。首先概述了MEMS麦克风的基础知识和树莓派的音频接口配置,进而深入探讨了模拟信号数字化处理的原理和方法。随后,文章通过理论与实践相结合的方式,分析了声音信号的属性、常用处理算法以及实际应用案例。第四章着重于音频信号处理项目的构建和声音事件的检测响应,最后探讨了树莓派音频项目的拓展方向、
西门子G120C变频器维护速成

# 摘要
西门子G120C变频器作为工业自动化领域的一款重要设备,其基础理论、操作原理、硬件结构和软件功能对于维护人员和使用者来说至关重要。本文首先介绍了西门子G120C变频器的基本情况和理论知识,随后阐述了其硬件组成和软件功能,紧接着深入探讨了日常维护实践和常见故障的诊断处理方法。此外
【NASA电池数据集深度解析】:航天电池数据分析的终极指南
# 摘要
本论文提供了航天电池技术的全面分析,从基础理论到实际应用案例,以及未来发展趋势。首先,本文概述了航天电池技术的发展背景,并介绍了NASA电池数据集的理论基础,包括电池的关键性能指标和数据集结构。随后,文章着重分析了基于数据集的航天电池性能评估方法,包括统计学方法和机器学习技术的应用,以及深度学习在预测电池性能中的作用。此外,本文还探讨了数据可视化在分析航天电池数据集中的重要性和应用,包括工具的选择和高级可视化技巧。案例研究部分深入分析了NASA数据集中的故障模式识别及其在预防性维护中的应用。最后,本文预测了航天电池数据分析的未来趋势,强调了新兴技术的应用、数据科学与电池技术的交叉融合
HMC7044编程接口全解析:上位机软件开发与实例分析
# 摘要
本文全面介绍并分析了HMC7044编程接口的技术规格、初始化过程以及控制命令集。基于此,深入探讨了在工业控制系统、测试仪器以及智能传感器网络中的HMC7044接口的实际应用案例,包括系统架构、通信流程以及性能评估。此外,文章还讨论了HMC7044接口高级主题,如错误诊断、性能优化和安全机制,并对其在新技术中的应用前景进行了展望。
# 关键字
HMC7044;编程接口;数据传输速率;控制命令集;工业控制;性能优化
参考资源链接:[通过上位机配置HMC7044寄存器及生产文件使用](https://wenku.csdn.net/doc/49zqopuiyb?spm=1055.2635
【COMSOL Multiphysics软件基础入门】:XY曲线拟合中文操作指南
# 摘要
本文全面介绍了COMSOL Multiphysics软件在XY曲线拟合中的应用,旨在帮助用户通过高级拟合功能进行高效准确的数据分析。文章首先概述了COMSOL软件,随后探讨了XY曲线拟合的基本概念,包括数学基础和在COMSOL中的应用。接着,详细阐述了在COMSOL中进行XY曲线拟合的具体步骤,包括数据准备、拟合过程,
【GAMS编程高手之路】:手册未揭露的编程技巧大公开!
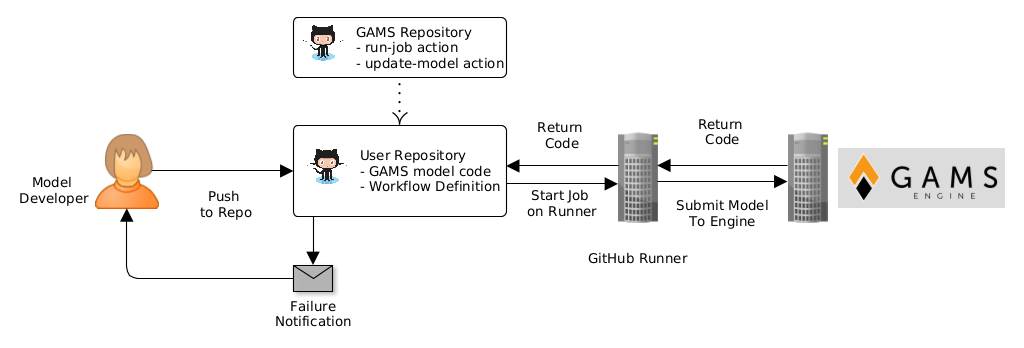
# 摘要
本文全面介绍了一种高级建模和编程语言GAMS(通用代数建模系统)的使用方法,包括基础语法、模型构建、进阶技巧以及实践应用案例。GAMS作为一种强大的工具,在经济学、工程优化和风险管理领域中应用广泛。文章详细阐述了如何利用GAMS进行模型创建、求解以及高级集合和参数处理,并探讨了如何通过高级
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )