【Beautiful Soup高级用法】:构建复杂数据结构解析框架的秘诀
发布时间: 2024-09-30 22:59:43 阅读量: 32 订阅数: 34 

面向新手解析python Beautiful Soup基本用法

# 1. Beautiful Soup简介和安装使用
在本章节中,我们将介绍Beautiful Soup库的基本概念,它的作用以及如何在我们的项目中安装并开始使用它。Beautiful Soup是一个Python库,主要用于Web页面内容的解析工作,它可以将复杂的HTML和XML文档转换成一个树形结构,通过这个树形结构,我们可以方便地提取我们所需要的数据。
首先,我们需要通过Python的包管理工具pip来安装Beautiful Soup。安装指令非常简单,只需要在我们的命令行界面中输入以下命令:
```bash
pip install beautifulsoup4
```
安装完成后,我们将通过一个简单的示例来演示如何使用Beautiful Soup。假设我们有以下一段HTML代码,我们想要提取其中所有的标题内容:
```html
<html><head><title>Example Page</title></head><body><h1>First heading</h1><p>This is a paragraph.</p><h2>Second heading</h2></body></html>
```
我们使用Python代码,利用Beautiful Soup来解析这段HTML,并提取所有标题标签<h1>和<h2>中的文本:
```python
from bs4 import BeautifulSoup
# 我们将HTML内容和解析器传递给BeautifulSoup类,这里使用'lxml'作为解析器
soup = BeautifulSoup('<html><head><title>Example Page</title></head><body><h1>First heading</h1><p>This is a paragraph.</p><h2>Second heading</h2></body></html>', 'lxml')
# 使用find_all方法找到所有的标题标签<h1>和<h2>
headings = soup.find_all(['h1', 'h2'])
# 提取并打印每个标签中的文本
for heading in headings:
print(heading.get_text())
```
输出结果将会是:
```
First heading
Second heading
```
通过这个简单的例子,我们可以看到Beautiful Soup的使用非常直观,它使得处理HTML和XML文档变得简单方便。接下来的章节中,我们将深入了解Beautiful Soup的强大功能,并掌握更多高级技巧。
# 2. Beautiful Soup的基础解析技巧
在开始学习Beautiful Soup的基础解析技巧之前,理解其作为一个Python库的定位是非常重要的。Beautiful Soup库能够将复杂的HTML或XML文档转换成一个简单易操作的树形结构,提供了一系列的导航、搜索和修改树节点的功能。这意味着它可以帮助开发者从结构化的文档中提取数据,甚至在数据结构不完整或者文档格式有误的情况下也能应付自如。
### 2.1 HTML和XML文档解析
#### 2.1.1 基本的标签选择和文本提取
Beautiful Soup提供了一系列简单的方法来选择和搜索文档树中的元素。首先,你需要创建一个BeautifulSoup对象,这个对象会包装并解析你的文档,使其成为Beautiful Soup库可操作的结构。
```python
from bs4 import BeautifulSoup
# 示例文档
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<a href="***" id="link1">Link 1</a>
<a href="***">Link 2</a>
<a href="***">Link 3</a>
</body>
</html>
soup = BeautifulSoup(html_doc, 'html.parser')
# 选择所有<a>标签
links = soup.find_all('a')
# 提取<a>标签的文本
text = links[0].text
print(text) # 输出: Link 1
```
#### 2.1.2 属性操作和CSS选择器应用
除了标签选择,Beautiful Soup还能帮助我们快速获取标签的属性。同样地,它也支持使用CSS选择器来定位文档中的元素。
```python
# 获取<a>标签的href属性
href = links[0].get('href')
print(href) # 输出: ***
* 使用CSS选择器获取id为"link1"的元素
link1 = soup.select('#link1')[0]
print(link1.text) # 输出: Link 1
```
### 2.2 高级导航和搜索
#### 2.2.1 搜索树结构的方法
当你需要从文档中找到特定的元素时,Beautiful Soup提供了一组导航方法,如`find`, `find_all`, `parent`, `children`, `next_siblings`等,它们可以帮助我们遍历文档树并找到所需的节点。
```python
# 查找所有<p>标签中的<b>标签
bold_tags = soup.find_all('p')
for p in bold_tags:
print(p.b.text) # 输出: The Dormouse's story
```
#### 2.2.2 使用正则表达式查找元素
如果你的目标更加模糊不清,你可以使用正则表达式来匹配标签的名称或者属性值。这在处理复杂的或者不规则的文档时非常有用。
```python
import re
# 使用正则表达式查找所有href属性以'http'开始的<a>标签
links = soup.find_all('a', href=***pile('^http'))
for link in links:
print(link.text) # 输出: Link 1, Link 2, Link 3
```
### 2.3 数据清洗和预处理
#### 2.3.1 去除多余空格和格式化输出
在解析HTML或XML文档时,常常会遇到大量的空白字符和不规范的格式,Beautiful Soup提供了方法来处理这些问题,如`prettify`方法可以将文档树格式化为美观的形式。
```python
# 格式化输出整个文档
print(soup.prettify())
```
#### 2.3.2 处理特殊字符和编码问题
文档中可能包含一些特殊字符,这些字符如果不处理可能会导致解析错误或者显示问题。Beautiful Soup同样可以帮助我们处理这些字符。
```python
# 处理特殊字符
special_text = soup.find('p').get_text()
print(special_text) # 输出: The Dormouse's story
# 注意:输出中已经将特殊字符'’'转换成了正常的单引号
```
通过以上内容,我们已经介绍了一些基础的解析技巧,并展示了如何使用Beautiful Soup库对HTML和XML文档进行简单的解析和预处理。在接下来的章节中,我们将深入探讨如何构建复杂的数据结构解析框架,实现高级数据清洗,并且将这些技术与其他工具和框架集成,以处理更复杂的数据抓取和分析任务。
# 3. 构建复杂数据结构解析框架
在本章中,我们将深入探讨如何使用Beautiful Soup来构建更加复杂和高效的数据解析框架。无论是从复杂的HTML结构中提取信息,还是在处理大量数据时优化性能,以及创建易于维护和扩展的模块化代码,都是本章关注的重点。
### 3.1 多层级数据提取技术
#### 3.1.1 利用find_all和recursive参数
Beautiful Soup提供了强大的方法来遍历文档树,并且可以通过`find_all`方法找到符合条件的所有标签。在此过程中,`recursive`参数起到了关键作用,它决定了搜索的深度。
```python
from bs4 import BeautifulSoup
# 示例HTML文档
html_doc = '''
<html>
<head>
<title>示例文档</title>
</head>
<body>
<div id="container">
<p class="title">一级标题</p>
<p>内容段落</p>
<ul>
<li>列表项1</li>
<li>列表项2
<ul>
<li>子列表项1</li>
<li>子列表项2</li>
</ul>
</li>
</ul>
</div>
</body>
</html>
soup = BeautifulSoup(html_doc, 'html.parser')
titles = soup.find_all('p', class_='title', recursive=False)
for title in titles:
print(title.text)
```
上面的代码块使用`find_all

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 库 Beautiful Soup,为网页数据解析提供了全面的指南。从基础知识到高级技术,本专栏涵盖了广泛的主题,包括:
* 提升解析效率的秘诀
* Beautiful Soup 与 XPath 的比较
* 构建网络爬虫的实践技巧
* 处理复杂网页的策略
* 解决编码问题的终极指南
* 优化解析性能的方法
* 网页数据提取的最佳实践
* 避免解析错误的策略
* 多线程应用以提高效率
* 解析 CSS 选择器的指南
* 优雅处理解析异常的方法
* 遵守 Python 爬虫法律边界的指南
* 定制解析器的专家指南
* 处理 JavaScript 渲染页面的技巧
* 构建复杂数据结构解析框架的秘诀
* 自动化处理网页表单的实用指南
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【PCIe 5.0兼容性指南】:保证旧有设备与新标准无缝对接(7大实用技巧)
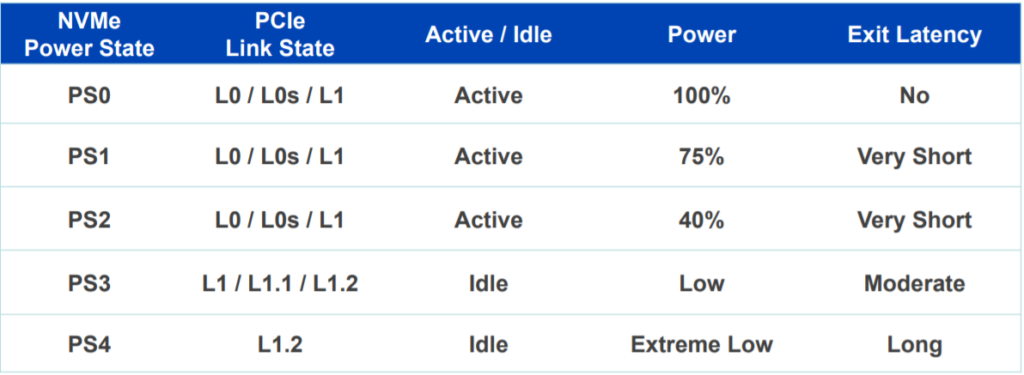
# 摘要
本文深入探讨了PCIe 5.0技术的兼容性问题,从基本架构、协议新特性到设备升级和兼容性实践技巧,提供了全面的理论和实践指导。文中分析了PCIe 5.0的兼容性挑战,探讨了硬件、软件以及固件的升级策略,并通过多种实际案例,讨论了如何实现旧设备与PCIe 5.0的无缝对接。此外,本文还提出了一系列解决兼容性问题的方法,并对如何进行兼容性验证和认证给出了详细流程,旨在帮助技术人员确保设备升级后与PCIe 5.0技术的兼容性和性能的优化。
深入理解SpringBoot与数据库交互:JPA和MyBatis集成指南
# 摘要
本文详细介绍了SpringBoot与数据库交互的技术实践,探讨了JPA(Java Persistence API)和MyBatis两种流行的ORM(Object-Relational Mapping)框架的集成与应用。文章从基本概念和原理出发,详细阐述了JPA的集成过程、高级特性以及MyBatis的核心组件和工作方式。在深入分析了JPA
硬件在环仿真实战:Simetrix与你的完美结合
# 摘要
本文详细介绍了硬件在环仿真(Hardware in the Loop, HIL)的基本概念、Simetrix软件的功能及应用,并提供了多个实战案例分析。首先,概述了Simetrix软件的安装、界面布局和仿真技术,包括与其它仿真软件的对比。随后,本论文深入探讨了硬件在环仿真平台的搭建、测试实施以及结果分析方法。在Simetrix的高级应用方面,本文探讨了脚本编写、自动化测试、电路
【WinCC V16 脚本编程高级教程】

# 摘要
WinCC V16是西门子公司推出的组态软件,其脚本编程功能强大,是实现用户特定功能的关键工具。本文全面介绍了WinCC V16脚本编程的各个层面,从基础语法特性到高级应用技巧,再到问题诊断与优化策略。文中详细分析了变量、数据结构、控制结构、逻辑编程以及性能优化等关键编程要素。在实践应用方面,探讨了用户界面交互设计、数据通信、动态数据处理与可视化等实际场景。高级脚本应用部分着重讲解了数据处理、系统安
Layui上传文件错误处理:文件上传万无一失的终极攻略

# 摘要
Layui作为一款流行的前端UI框架,其文件上传功能对于开发交互性网页应用至关重要。本文首先介绍了Layui文件上传功能的基础知识,随后深入探讨了文件上传的理论基础,包括HTTP协议细节、Layui upload模块原理及常见错误类型。第三章和第四章集中于错误诊断与预防,以及解决与调试技巧,提供了前端和后端详细的错误处理方法和调试工具的使用。最后,第五章通过案例分析,展示了在复杂环境
【ESP8266与CJSON的结合】:打造个性化天气预警系统

# 摘要
本文介绍ESP8266平台与CJSON库的集成,旨在构建一个高效、个性化的天气预警系统。首先,本文概述ESP8266平台和CJSON库的基础知识,包括硬件架构、开发环境搭建,以及CJSON库在数据处理中的优势。接着,详细阐述了如何获取和解析天气数据,以及如何在ESP8266平台上利用CJSON进行数据解析和本地化显示。文中还探讨了如
【实战揭秘】:用社区地面系统模型解决复杂问题的技巧
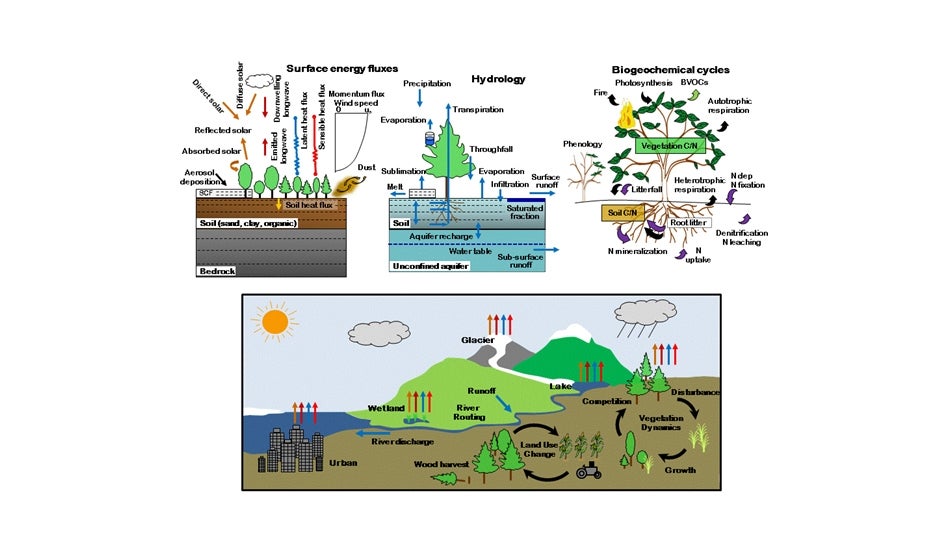
# 摘要
本文深入探讨了社区地面系统模型的构建与应用,从理论基础到实践案例进行了全面分析。首先,概述了社区地面系统模型的重要性和构建原则,接着讨论了系统模型的数学表达和验证方法。文章详细介绍了该模型在城市规划、灾害管理以及环境质量改善方面的具体应用,并探讨了模型在解决复杂问题时的多层次结构和优化策略。此外,本文
【Asap光学设计界面布局】:全面解析提升设计效率的关键步骤
# 摘要
本文详细探讨了Asap光学设计软件界面布局的各个方面,从基础的理论框架、设计元素到实际的应用技巧以及高级应用。文中分析了界面布局的基本原则和设计效率的关系,介绍了提高用户体验的交互设计和优化策略,并通过用户研究、设计工具的应用与界面布局的迭代来强化实践技巧。此外,文章还讨论了动态布局与响应式设计,高级交互技术的应用,以
【PLSY与PLSR调试优化】:三菱PLC脉冲控制技巧,提升性能

# 摘要
本文深入探讨了PLC(可编程逻辑控制器)中PLSY(脉冲输出)与PLSR(脉冲输入)指令的基础知识、理论基础及其在实际应用中的优化与调试方法。重点介绍了这些指令的工作原理、参数设置对性能的影响、以及在特定场合如电机控制中的实现。文章还探讨了脉冲控制技术在三菱PLC中的应用,包括多轴协调控制和精密位置控制策略,并提出
【个性化和利时M6软件体验】

# 摘要
本文介绍个性化和利时M6软件的理论基础和实践应用。首先,概述了软件的功能需求和核心架构,包括用户研究、功能模块化设计、软件的整体架构以及关键技术组件。其次,通过实践案例,展示了用户界面个性化定制、功能模块灵活配置和用户行为数据分析的应用。接着,深入探讨了软件与企业业务流程集成的最佳实践,以及技术创新对软件个性化的影响。最后,分析了个性化和利时M6软件在性能优化、安全挑战应对以及持续支持与服务升
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )