【数据清洗关键技巧】:R语言中的准备工作,决定成败
发布时间: 2024-11-03 12:02:11 阅读量: 26 订阅数: 39 

# 1. 数据清洗的重要性与准备工作概述
在处理数据的全生命周期中,数据清洗是一个不可或缺的环节。准确、可靠的数据是建立预测模型、进行数据挖掘以及进行其他数据分析活动的基础。数据清洗不仅提高了数据质量,也确保了后续分析的准确性和有效性。
## 数据清洗的重要性
数据清洗的主要目的是清除不一致性和错误数据,以提高数据质量。它涉及识别并处理缺失值、异常值、重复记录以及格式错误等问题。在处理大规模数据集时,数据清洗能够显著提高分析结果的准确性,进而影响决策的有效性。
## 准备工作概述
在数据清洗之前,需要完成一系列准备工作,以确保清洗过程的顺利进行。这些准备工作包括:
- **数据理解**:分析数据集的内容、结构和业务背景,以了解数据的特点和潜在的问题。
- **环境搭建**:配置必要的数据处理工具和软件,例如安装R语言及其相关包。
- **策略规划**:制定数据清洗的策略和流程,明确在清洗过程中要实现的目标。
通过这些准备工作,我们可以在清洗数据之前就已经有了一个清晰的方向和计划,为后续的数据处理工作奠定了坚实的基础。接下来的章节中,我们将逐步探讨如何使用R语言进行数据清洗和数据结构的操作。
# 2. R语言数据类型和数据结构
## 2.1 R语言中的基本数据类型
R语言中的基本数据类型主要包括向量、矩阵和数组、数据框(DataFrame)和列表(List)。理解这些数据类型是进行数据操作和分析的基础。
### 2.1.1 向量、矩阵和数组
向量是R中最基本的数据结构,可以包含数值、字符或其他类型的数据。创建向量可以使用`c()`函数,比如创建一个数值型向量:
```R
num_vector <- c(1, 2, 3, 4)
```
矩阵是一个二维数组,必须包含相同数据类型的数据,并且具有行和列。创建矩阵可以使用`matrix()`函数:
```R
matrix(1:9, nrow = 3, ncol = 3)
```
数组是一种多维数据结构,至少包含二维。创建数组可以使用`array()`函数:
```R
array(1:24, dim = c(3, 4, 2))
```
### 2.1.2 数据框(DataFrame)和列表(List)
数据框是R中最常用的数据结构,可以看作是一个表格形式的变量,其中的每列可以包含不同数据类型。数据框使用`data.frame()`函数创建:
```R
data_frame <- data.frame(
id = 1:5,
name = c("Alice", "Bob", "Charlie", "David", "Eve"),
age = c(23, 45, 32, 21, 53)
)
```
列表可以包含不同数据类型的元素,可以嵌套其他列表,使用`list()`函数创建:
```R
list_vector <- list("Alice", 1:5, matrix(1:9, nrow = 3))
```
## 2.2 R语言中的数据结构操作
数据结构的操作是数据处理的基础,R提供了丰富的函数和操作符来操作数据结构。
### 2.2.1 数据的创建和赋值
在R中创建数据结构并赋值可以通过多种方式,例如:
```R
# 使用 <- 或 = 赋值
x <- c(1, 2, 3)
y = c("a", "b", "c")
# 使用函数创建
z <- data.frame(x = 1:10, y = letters[1:10])
```
### 2.2.2 数据的索引和子集选取
索引是选择数据框中的元素的关键,R中可以使用`[]`或`[[]]`进行索引操作:
```R
# 选取数据框中的一列
x <- z[, 1] # 或者 z$x
# 选取数据框中的行
y <- z[1:5, ]
```
### 2.2.3 数据的合并和重塑
数据的合并和重塑是数据分析中常见的需求,可以使用`merge()`, `rbind()`, `cbind()`, `reshape()`等函数实现:
```R
# 合并数据框
merge(x, y, by = "id")
# 重塑数据框
reshape(z, direction = "long", idvar = "id", varying = list(colnames(z)[-1]))
```
## 2.3 R语言中的数据导入导出
数据的导入导出是数据处理的重要步骤,R支持从多种来源导入数据,也可以将数据导出到不同的格式。
### 2.3.1 从不同来源导入数据
R可以导入多种格式的数据,如CSV、Excel、文本文件等:
```R
# 从CSV文件导入
data_from_csv <- read.csv("path/to/file.csv")
# 从Excel文件导入
data_from_excel <- readxl::read_excel("path/to/file.xlsx")
```
### 2.3.2 数据的导出与存储
将数据导出到不同的格式或存储到文件系统中:
```R
# 导出到CSV
write.csv(data_frame, "path/to/output.csv")
# 导出到R数据文件
saveRDS(data_frame, "path/to/output.rds")
```
以上内容涵盖R语言数据类型和数据结构的基础知识,是进一步学习数据清洗技术的前提。理解了这些基础概念后,可以更高效地进行数据处理和分析。
# 3. R语言数据清洗实践技巧
数据清洗是数据分析中不可或缺的一步,它直接影响到后续分析结果的准确性和可靠性。在数据清洗的过程中,处理缺失数据、异常值、噪声数据以及对数据进行转换和正规化是经常遇到的问题。本章将深入探讨这些实践技巧,并以R语言为工具进行操作示例。
## 3.1 缺失数据处理
### 3.1.1 缺失值的检测和理解
在R语言中,缺失值通常用`NA`来表示。在处理数据之前,首先需要检测数据集中是否存在缺失值,并了解它们的分布情况。`is.na()`函数可以帮助我们识别哪些元素是缺失的,而`summary()`函数则可以给出数据集中每个变量的缺失值统计信息。
```r
# 创建一个数据框示例
data <- data.frame(
A = c(1, 2, NA, 4, 5),
B = c(NA, 2, 3, 4, 5),
C = c(1, NA, 3, NA, 5)
)
# 检测数据框中的缺失值
missing_values <- is.na(data)
# 统计每个变量的缺失值数量
summary_missing <- summary(data)
# 输出检测结果
print(missing_values)
# 输出统计信息
print(summary_missing)
```
### 3.1.2 缺失数据的填补方法
处理缺失数据的常见方法有删除含有缺失值的行或列、用均值、中位数、众数或预测模型填补等。在R中,`na.omit()`函数可以删除所有含有`NA`的行,`mean()`、`median()`或`mode()`函数可以用于填补数值型变量的缺失值,而`mice`包提供了一种更为高级的多重插补方法。
```r
# 删除含有NA的行
cleaned_data <- na.omit(data)
# 用均值填补数值型变量的缺失值
for (i in 1:n
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏提供全面的 R 语言指南,涵盖从基础到高级应用的各个方面。它深入探讨了数据可视化、大数据分析、数据分析项目开发、函数和代码优化,以及机器学习模型构建。专栏还重点介绍了 pvclust 数据包,这是一个强大的聚类分析工具,可用于挖掘复杂数据问题的深入见解。通过循序渐进的教程、清晰的解释和实用示例,本专栏旨在帮助读者掌握 R 语言的强大功能,并将其应用于各种数据分析和机器学习任务。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【西数硬盘维修WDR5.3新手指南】:一步步教你基础入门和工具使用

# 摘要
本文系统介绍了西数硬盘维修软件WDR5.3的操作流程和技巧。文章首先概述了硬盘的工作原理和常见故障类型,随后详细阐释了WDR5.3软件的基本理论知识、操作实践、进阶技巧以及性能优化方法。通过详细分析真实案例,本文评估了维修前后的硬盘性能和数据恢复成功率。最后,文章总结了维修过程中的成功和失败经验,并对硬盘维修行业未来的发展趋势进行了展望。
# 关键字
硬盘维修;WDR5.3软件;故障诊断;数据恢复;性能
编程传奇:雷军如何用汇编代码重塑编程世界

# 摘要
本文全面探讨了汇编语言编程的历史演变、基础理论、编程实践技巧、雷军与汇编语言的关联故事以及其现代应用和未来展望。文章第一章回顾了汇编语言的发展历程
【BSF服务部署策略】:从理论到实际的转变

# 摘要
BSF服务部署策略是一个关键领域,涉及服务的概念、优势、部署环境、配置、优化和故障处理。本文全面概述了BSF服务的部署策略,提供了基础理论知识,并介绍了配置和优化的实际方法。文中还探讨了BSF服务的安全策略、集群部署和API集成
【智能电网新纪元】:继电保护技术的革新与IT融合
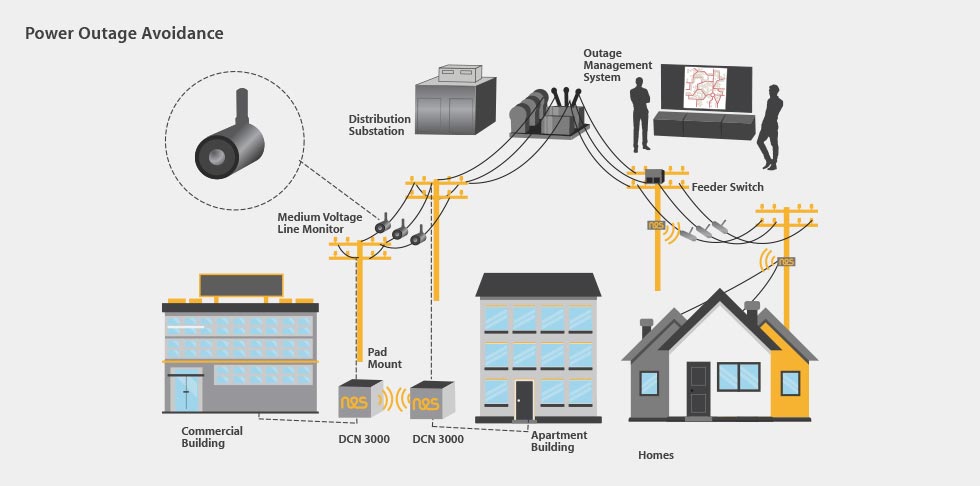
# 摘要
智能电网与继电保护技术是电力系统现代化的两大核心领域。本文首先概述了智能电网与继电保护技术的基本概念和理论基础,随后探讨了继电保护技术的创新进展和可靠性分析,同时分析了IT技术在继电保护领域的应用以及智能化系统架构和网络安全策略。在智能电网的IT技术融合实践章节,文章讨论了通信协议标准、IT系统实践案例和可持续发展策略。最后,文章展望了未来电网技术的发展方向,电网智能化面临的挑战和对策,并提出了创新与实践
【GMDSS通信原理揭秘】:深入理解与模拟实践技巧
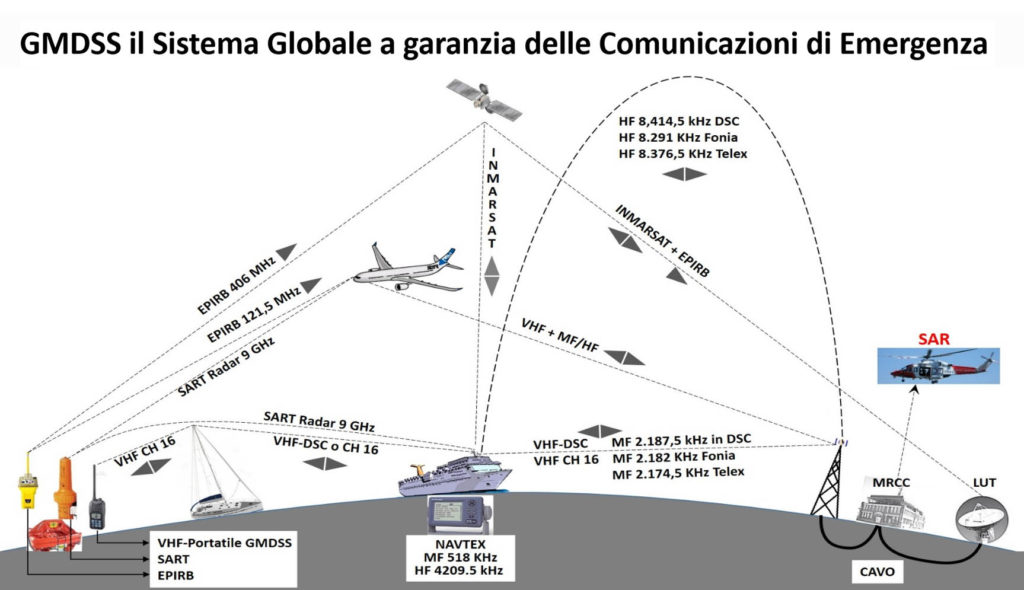
# 摘要
本文综述了全球海上遇险与安全系统(GMDSS)的通信技术,覆盖了硬件构成、通信协议、信号处理、模拟仿真,以及系统的安全与可靠性分析。在硬件构成方面,详细探讨了GMDSS主要设备的功能与分类、通信终端技术,以及导航设备与辅助系统。通信协议与信号部分介绍了GMDSS的标准协议、信号编码与调制技术,以及安全与紧急通信流程。模拟与仿真是通过软件进行通信测试和场景模拟,重点在于实验结果的分析与验证。安全与可靠性
【硬盘克隆进阶】:深入理解扇区级复制,个性化Ghost设置详解

# 摘要
随着信息技术的飞速发展,硬盘克隆技术已成为数据备份、迁移与恢复的重要手段。本文首先概述了硬盘克隆的基本概念及其在数据保护中的作用。随后,深入分析了扇区级复制的理论基础,包括硬盘结构、扇区定义及其复制原理。在个性化Ghost设置部分,本文详细介绍了Ghost软件的操作方法、硬件加速技巧以及扇区映射和错误检测的技术。通过实践操作部分,本文指导读者如何手动和通过自
FT232H接口设计:硬件与软件的考量要点

# 摘要
FT232H作为一种常用的USB转串口芯片,在数据通信领域发挥着重要作用。本文首先概述了FT232H接口的基本概念及其工作原理,然后深入分析了硬件设计的关键考量,包括电气特性、电源管理、PCB设计等。接着,文章探讨了软件驱动开发中固件与驱动架构、跨平台兼容性以及高级通信协议实现的重要性。通过不同领域应用实例的分析,展示了F
研发部门绩效考核案例研究:构建高效研发团队的KPI系统秘籍

# 摘要
绩效考核在研发团队管理中扮演着至关重要的角色,它直接关联到团队的工作效率和目标达成。本文深入探讨了KPI(关键绩效指标)与研发团队绩效之间的紧密联系,以及如何设计有效的KPI体系以确保其与组织目标的一致性。文章通过具体实践案例,分析了建立高效研发团队KPI系统的过程,并指出
【网络启动故障不求人】:一步步教你排查与解决PXE和GHOST常见问题

# 摘要
网络启动技术是现代IT基础设施部署中不可或缺的一部分,本文旨在探讨网络启动技术的基础原理、故障排查以及高级应用。首先,介绍了PXE启动技术及其故障排查,包括PXE的工作原理、常见故障类型和排查方法。接着,深入分析了GHOST部署中遇到的故障问题及其解决策略。此外,本文还探讨了网络启动的高级应用,例如集中管理和自动化部署,以及如何通过工具
STM32定时器高级应用:HAL库定时技巧与案例分析
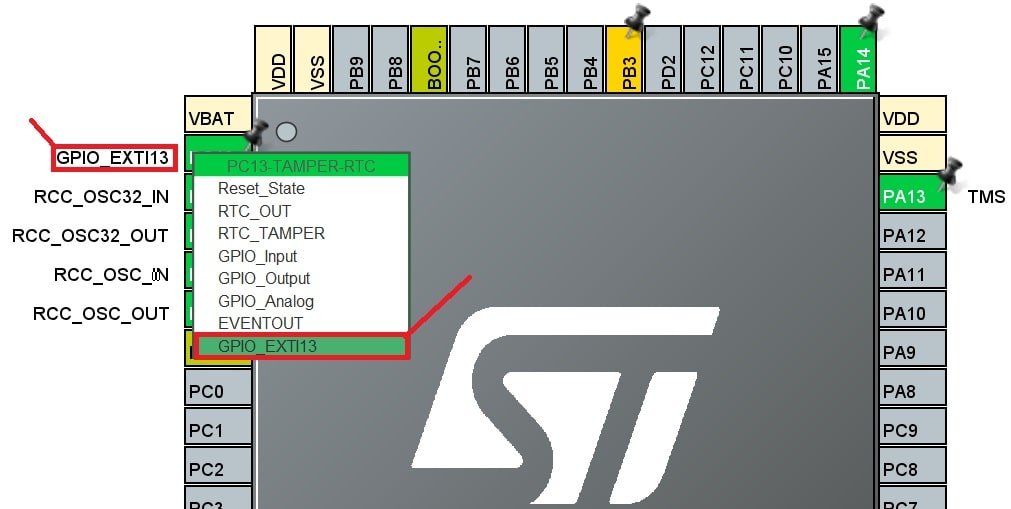
# 摘要
本文系统地探讨了STM32微控制器中定时器的功能、配置和应用。首先,介绍了定时器的基本工作原理和HAL库提供的API函数,以及定时器配置参数的详细解析。随后,本文深入阐述了定时器编程技巧,包括如何精确配置定时器时间和实现高级应用。文章进一步分析了定时器在不同应用场景中的实际运用,比如通信
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )