傅里叶逆变换在自然语言处理中的4个核心应用,解锁文本分析新境界
发布时间: 2024-07-13 20:24:07 阅读量: 50 订阅数: 36 

# 1. 傅里叶逆变换的理论基础
傅里叶逆变换是傅里叶变换的逆运算,用于将频域信号转换为时域信号。其数学表达式为:
```
f(t) = ∫[-∞,∞] F(ω) * e^(iωt) dω
```
其中:
- `f(t)` 是时域信号
- `F(ω)` 是频域信号
- `ω` 是角频率
傅里叶逆变换揭示了信号在时域和频域之间的关系,为信号分析和处理提供了重要工具。
# 2. 傅里叶逆变换在文本分析中的应用
傅里叶逆变换在文本分析中发挥着至关重要的作用,为文本相似度计算、文本分类和文本生成提供了强大的数学基础。
### 2.1 文本相似度计算
#### 2.1.1 傅里叶变换的应用
傅里叶变换可以将文本转换为频率域,其中文本中的每个单词对应于一个频率分量。通过比较两个文本的频率分量,我们可以计算它们的相似度。
#### 2.1.2 余弦相似度和欧氏距离
余弦相似度和欧氏距离是常用的文本相似度度量。余弦相似度衡量两个文本向量之间的夹角,而欧氏距离衡量它们之间的距离。
```python
import numpy as np
# 计算两个文本向量的余弦相似度
def cosine_similarity(vec1, vec2):
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
# 计算两个文本向量的欧氏距离
def euclidean_distance(vec1, vec2):
return np.linalg.norm(vec1 - vec2)
```
### 2.2 文本分类
#### 2.2.1 傅里叶逆变换的特征提取
傅里叶逆变换可以从文本中提取特征,这些特征可以用于训练机器学习模型进行文本分类。
#### 2.2.2 机器学习算法的应用
常用的机器学习算法,如支持向量机(SVM)和朴素贝叶斯,可以利用傅里叶逆变换提取的特征对文本进行分类。
```python
from sklearn.svm import SVC
# 使用傅里叶逆变换特征训练SVM模型
def train_svm_model(X_train, y_train):
model = SVC()
model.fit(X_train, y_train)
return model
# 使用训练好的SVM模型对新文本进行分类
def classify_text(model, X_test):
return model.predict(X_test)
```
### 2.3 文本生成
#### 2.3.1 傅里叶逆变换的序列建模
傅里叶逆变换可以对文本序列进行建模,这为文本生成提供了基础。
#### 2.3.2 生成式对抗网络的应用
生成式对抗网络(GAN)是一种生成模型,可以利用傅里叶逆变换建模的文本序列生成新的文本。
```python
import tensorflow as tf
# 定义生成器和判别器网络
generator = tf.keras.models.Sequential(...)
discriminator = tf.keras.models.Sequential(...)
# 训练GAN模型
def train_gan_model(generator, discriminator, X_train):
# 定义损失函数和优化器
loss_fn = tf.keras.losses.BinaryCrossentropy()
optimizer_g = tf.keras.optimizers.Adam()
optimizer_d = tf.keras.optimizers.Adam()
# 训练循环
for epoch in range(num_epochs):
# 训练判别器
for batch in X_train:
# 更新判别器权重
with tf.GradientTape() as tape:
real_loss = loss_fn(discriminator(batch), tf.ones_like(discriminator(batch)))
fake_loss = loss_fn(discriminator(generator(batch)), tf.zeros_like(discriminator(generator(batch))))
loss = real_loss + fake_loss
gradients = tape.gradient(loss, discriminator.trainable_weights)
optimizer_d.apply_gradients(zip(gradients, discriminator.trainable_weig
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《傅里叶逆变换》专栏深入探讨了傅里叶逆变换在各个领域的广泛应用。从信号处理到图像处理,再到物理学、通信系统、深度学习、机器学习、计算机视觉、自然语言处理、生物信息学、医学成像、金融建模、气象预报、材料科学和化学,本专栏提供了全面的指南,帮助读者了解和掌握傅里叶逆变换的原理和应用。通过深入浅出的讲解、实用技巧和实战案例,本专栏旨在帮助读者轻松驾驭时域与频域,提升信号质量、图像增强、波动探索、通信效率、AI算法潜力、模型精度、图像识别、文本分析、基因组奥秘、诊断准确性、市场预测、天气预知、材料特性和分子结构等领域的专业知识。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【R语言数据预处理全面解析】:数据清洗、转换与集成技术(数据清洗专家)

# 1. R语言数据预处理概述
在数据分析与机器学习领域,数据预处理是至关重要的步骤,而R语言凭借其强大的数据处理能力在数据科学界占据一席之地。本章节将概述R语言在数据预处理中的作用与重要性,并介绍数据预处理的一般流程。通过理解数据预处理的基本概念和方法,数据科学家能够准备出更适合分析和建模的数据集。
## 数据预处理的重要性
数据预处理在数据分析中占据核心地位,其主要目的是将原
R语言与Rworldmap包的深度结合:构建数据关联与地图交互的先进方法

# 1. R语言与Rworldmap包基础介绍
在信息技术的飞速发展下,数据可视化成为了一个重要的研究领域,而地理信息系统的可视化更是数据科学不可或缺的一部分。本章将重点介绍R语言及其生态系统中强大的地图绘制工具包——Rworldmap。R语言作为一种统计编程语言,拥有着丰富的图形绘制能力,而Rworldmap包则进一步扩展了这些功能,使得R语言用户可以轻松地在地图上展
【R语言数据可读性】:利用RColorBrewer,让数据说话更清晰

# 1. R语言数据可读性的基本概念
在处理和展示数据时,可读性至关重要。本章节旨在介绍R语言中数据可读性的基本概念,为理解后续章节中如何利用RColorBrewer包提升可视化效果奠定基础。
## 数据可读性的定义与重要性
数据可读性是指数据可视化图表的清晰度,即数据信息传达的效率和准确性。良好的数据可读
【R语言图表美化】:ggthemer包,掌握这些技巧让你的数据图表独一无二

# 1. ggthemer包介绍与安装
## 1.1 ggthemer包简介
ggthemer是一个专为R语言中ggplot2绘图包设计的扩展包,它提供了一套更为简单、直观的接口来定制图表主题,让数据可视化过程更加高效和美观。ggthemer简化了图表的美化流程,无论是对于经验丰富的数据
R语言与GoogleVIS包:制作动态交互式Web可视化

# 1. R语言与GoogleVIS包介绍
R语言作为一种统计编程语言,它在数据分析、统计计算和图形表示方面有着广泛的应用。本章将首先介绍R语言,然后重点介绍如何利用GoogleVIS包将R语言的图形输出转变为Google Charts API支持的动态交互式图表。
## 1.1 R语言简介
R语言于1993年诞生,最初由Ross Ihaka和Robert Gentleman在新西
【构建交通网络图】:baidumap包在R语言中的网络分析

# 1. baidumap包与R语言概述
在当前数据驱动的决策过程中,地理信息系统(GIS)工具的应用变得越来越重要。而R语言作为数据分析领域的翘楚,其在GIS应用上的扩展功能也越来越完善。baidumap包是R语言中用于调用百度地图API的一个扩展包,它允许用户在R环境中进行地图数据的获取、处理和可视化,进而进行空间数据分析和网
rgwidget在生物信息学中的应用:基因组数据的分析与可视化
# 1. 生物信息学与rgwidget简介
生物信息学是一门集生物学、计算机科学和信息技术于一体的交叉学科,它主要通过信息化手段对生物学数据进行采集、处理、分析和解释,从而促进生命科学的发展。随着高通量测序技术的进步,基因组学数据呈现出爆炸性增长的趋势,对这些数据进行有效的管理和分析成为生物信息学领域的关键任务。
rgwidget是一个专为生物信息学领域设计的图形用户界面工具包,它旨在简化基因组数据的分析和可视化流程。rgwidge
REmap包在R语言中的高级应用:打造数据驱动的可视化地图

# 1. REmap包简介与安装
## 1.1 REmap包概述
REmap是一个强大的R语言包,用于创建交互式地图。它支持多种地图类型,如热力图、点图和区域填充图,并允许用户自定义地图样式,增加图形、文本、图例等多种元素,以丰富地图的表现形式。REmap集成了多种底层地图服务API,比如百度地图、高德地图等,使得开发者可以轻松地在R环境中绘制出专业级别的地图。
## 1.2 安装REmap包
在R环境
R语言数据包用户社区建设
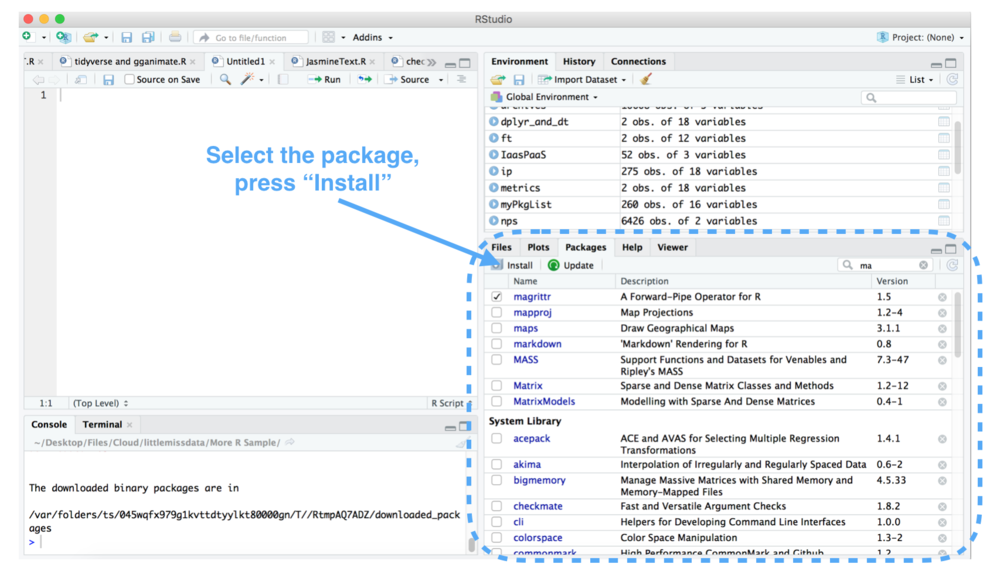
# 1. R语言数据包用户社区概述
## 1.1 R语言数据包与社区的关联
R语言是一种优秀的统计分析语言,广泛应用于数据科学领域。其强大的数据包(packages)生态系统是R语言强大功能的重要组成部分。在R语言的使用过程中,用户社区提供了一个重要的交流与互助平台,使得数据包开发和应用过程中的各种问题得以高效解决,同时促进
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )