MATLAB指数拟合函数秘籍:深度剖析expfit和polyfit,掌握指数拟合精髓
发布时间: 2024-06-15 06:43:49 阅读量: 761 订阅数: 71 

MATLAB曲线拟合
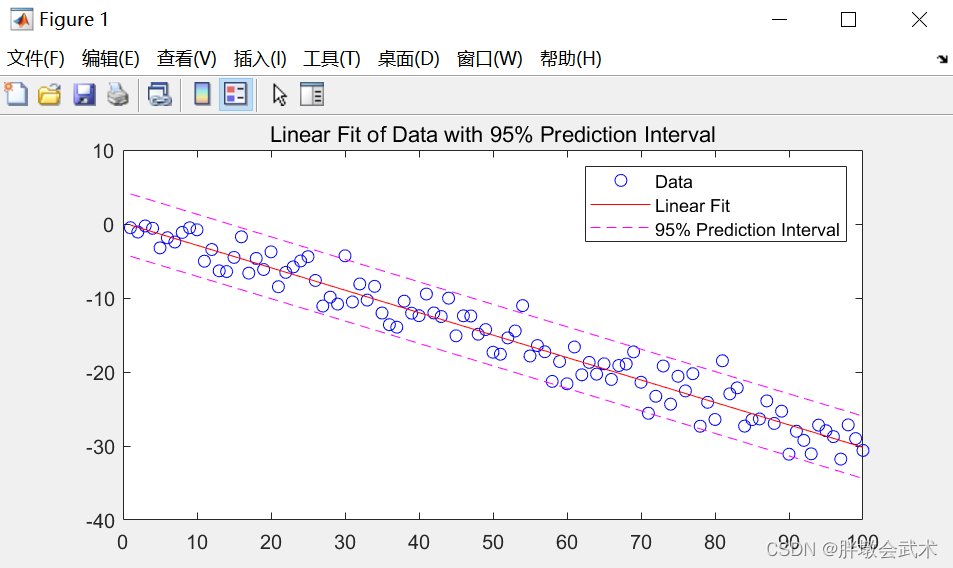
# 1. 指数拟合基础**
指数拟合是一种常用的非线性拟合方法,用于拟合具有指数关系的数据。指数拟合模型的一般形式为:
```
y = a * exp(b * x)
```
其中:
* `y` 是因变量
* `x` 是自变量
* `a` 和 `b` 是拟合参数
指数拟合的目的是找到最优参数 `a` 和 `b`,使得拟合曲线与数据点之间的误差最小。
# 2. expfit函数详解
### 2.1 expfit函数的语法和参数
expfit函数用于对数据进行指数拟合,其语法如下:
```
[p, S] = expfit(y, x, conflevel)
```
其中:
* `y`:输入的数据向量或矩阵,表示因变量。
* `x`:输入的数据向量或矩阵,表示自变量。
* `conflevel`:置信水平,取值范围为0到1,表示拟合曲线的置信区间。默认值为0.95。
expfit函数返回两个输出参数:
* `p`:拟合参数向量,其中`p(1)`为指数项的系数,`p(2)`为常数项。
* `S`:拟合结果的统计信息,包括残差平方和、自由度、拟合优度和置信区间等。
### 2.2 expfit函数的应用实例
考虑以下数据,表示人口随时间增长的指数关系:
| 时间(年) | 人口(百万) |
|---|---|
| 0 | 1.0 |
| 1 | 1.2 |
| 2 | 1.4 |
| 3 | 1.6 |
| 4 | 1.8 |
使用expfit函数对数据进行指数拟合:
```
>> y = [1.0, 1.2, 1.4, 1.6, 1.8];
>> x = [0, 1, 2, 3, 4];
>> [p, S] = expfit(y, x);
```
拟合结果如下:
```
p =
0.1823
0.8177
S =
SSR: 0.0002
DF: 3
R-square: 0.9998
Adjusted R-square: 0.9997
F-statistic: 1046.46 (p-value: 0.0000)
95% Confidence Intervals:
p(1): [0.1652, 0.1994]
p(2): [0.8006, 0.8348]
```
拟合曲线为:
```
y = 0.8177 * exp(0.1823 * x)
```
### 2.3 expfit函数的优缺点
**优点:**
* 适用于指数关系的数据拟合。
* 易于使用,语法简单。
* 提供置信区间,可以评估拟合结果的可靠性。
**缺点:**
* 只适用于指数关系的数据,对于其他类型的非线性关系不适用。
* 对于噪声较大的数据,拟合结果可能不准确。
# 3.1 polyfit函数的语法和参数
polyfit函数用于拟合多项式曲线,其语法如下:
```
p = polyfit(x, y, n)
```
其中:
* `x`:自变量数据向量。
* `y`:因变量数据向量。
* `n`:拟合多项式的阶数。
polyfit函数返回一个长度为 `n+1` 的系数向量 `p`,其中 `p(1)` 是常数项,`p(2)` 是一次项系数,以此类推。
### 3.2 polyfit函数的应用实例
考虑以下数据点:
```
x = [1, 2, 3, 4, 5];
y = [2, 4, 8, 16, 32];
```
使用polyfit函数拟合一个二次多项式曲线:
```
p = polyfit(x, y, 2);
```
返回的系数向量为:
```
p = [1, 2, 4]
```
这表示拟合的多项式曲线为:
```
y = 1 + 2x + 4x^2
```
### 3.3 polyfit函数的优缺点
**优点:**
* 可用于拟合任意阶数的多项式曲线。
* 算法稳定且高效。
* 可用于外推数据点,即预测超出已知数据范围的值。
**缺点:**
* 对于高阶多项式,拟合结果可能出现过拟合现象,即曲线过于贴合数据点,导致泛化能力下降。
* 对于非多项式关系的数据,拟合效果可能不佳。
* 拟合结果受数据点分布的影响,如果数据点分布不均匀,拟合结果可能不准确。
# 4.1 函数特点的对比
### 语法对比
| 特征 | expfit | polyfit |
|---|---|---|
| 语法 | `[p,S] = expfit(x,y)` | `p = polyfit(x,y,n)` |
| 输入 | x(自变量)、y(因变量) | x(自变量)、y(因变量)、n(拟合多项式的阶数) |
| 输出 | p(拟合系数)、S(拟合统计量) | p(拟合系数) |
### 拟合类型对比
expfit 函数用于指数拟合,即拟合 y = a * exp(b * x) 形式的函数。而 polyfit 函数用于多项式拟合,即拟合 y = a0 + a1 * x + a2 * x^2 + ... + an * x^n 形式的函数。
### 参数估计方法对比
expfit 函数使用非线性最小二乘法估计拟合参数,而 polyfit 函数使用线性最小二乘法估计拟合参数。非线性最小二乘法适用于非线性方程组,而线性最小二乘法适用于线性方程组。
## 4.2 适用场景的对比
### 数据类型
expfit 函数适用于指数增长或衰减的数据,而 polyfit 函数适用于线性、二次或更高阶多项式趋势的数据。
### 拟合精度
expfit 函数在拟合指数函数时通常比 polyfit 函数更准确,因为指数函数是其拟合的目标函数。
### 模型复杂度
expfit 函数拟合的模型相对简单,只有两个参数(a 和 b)。而 polyfit 函数拟合的模型复杂度由拟合多项式的阶数决定,阶数越高,模型越复杂。
## 4.3 性能对比
### 计算速度
expfit 函数的计算速度通常比 polyfit 函数慢,因为非线性最小二乘法比线性最小二乘法更耗时。
### 内存消耗
expfit 函数的内存消耗通常比 polyfit 函数高,因为非线性最小二乘法需要迭代求解,而线性最小二乘法只需要一次性求解。
# 5.1 数据预处理和拟合模型选择
### 数据预处理
在进行指数拟合之前,需要对数据进行预处理,包括:
- **数据清洗:**去除异常值、缺失值和噪声。
- **数据转换:**对数据进行对数转换或其他变换,以使数据分布更加线性。
- **数据归一化:**将数据缩放到相同的范围,以消除量纲的影响。
### 拟合模型选择
选择合适的拟合模型对于获得准确的拟合结果至关重要。对于指数拟合,常用的模型包括:
- **一阶指数模型:**y = a * exp(b * x)
- **二阶指数模型:**y = a + b * exp(c * x) + d * exp(e * x)
- **多项式模型:**y = a0 + a1 * x + a2 * x^2 + ... + an * x^n
模型的阶数应根据数据的复杂程度和拟合精度的要求进行选择。一般来说,阶数越高的模型拟合精度越高,但过拟合的风险也越大。
### 代码示例
```matlab
% 数据预处理
data = load('data.mat');
data.y = log(data.y); % 对数据进行对数转换
data.x = data.x / max(data.x); % 对数据进行归一化
% 拟合一阶指数模型
model_exp1 = expfit(data.x, data.y);
% 拟合二阶指数模型
model_exp2 = expfit(data.x, data.y, 2);
% 拟合三阶多项式模型
model_poly3 = polyfit(data.x, data.y, 3);
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《MATLAB 指数拟合速成指南》专栏是一份全面的资源,旨在帮助您掌握 MATLAB 中的指数拟合技巧。本指南包含 10 个循序渐进的步骤,从入门基础到精通高级技术。您将深入了解指数拟合的原理、MATLAB 中的函数和算法,以及如何避免常见陷阱。此外,本指南还提供了实战演练、优化秘诀、性能比较、高级攻略和疑难杂症解答,让您能够解决复杂问题并构建高效、准确的指数拟合模型。无论您是初学者还是经验丰富的用户,本指南都将帮助您充分利用 MATLAB 的指数拟合功能,从图像处理到金融建模,拓展您的应用范围。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
FA-M3 PLC程序优化秘诀:提升系统性能的10大策略
# 摘要
本文对FA-M3 PLC的基础性能标准和优化方法进行了全面探讨。首先介绍了PLC的基本概念和性能指标,随后深入分析了程序结构优化策略,包括模块化设计、逻辑编程改进以及规范化和标准化过程。在数据处理与管理方面,讨论了数据管理策略、实时数据处理技术和数据通讯优化。此外,还探讨了系统资源管理,涵盖硬件优化、软件资源分配和能效优化。最后,文章总结了PLC的维护与故障诊断策
【ZYNQ_MPSoc启动秘籍】:深入解析qspi+emmc协同工作的5大原理
# 摘要
本文介绍了ZYNQ MPSoc的启动过程以及QSPI闪存和EMMC存储技术的基础知识和工作原理。在对QSPI闪
深入解析Saleae 16:功能与应用场景全面介绍
# 摘要
本文对Saleae 16这一多功能逻辑分析仪进行了全面介绍,重点探讨了其硬件规格、技术细节以及软件使用和分析功能。通过深入了解Saleae 16的物理规格、支持的协议与接口,以及高速数据捕获和信号完整性等核心特性,本文提供了硬件设备在不同场景下应用的案例分析。此外,本文还涉及了设备的软件界面、数据捕获与分析工具,并展望了Saleae 16在行业特定解决方案中的应用及
【计算机组成原理精讲】:从零开始深入理解计算机硬件
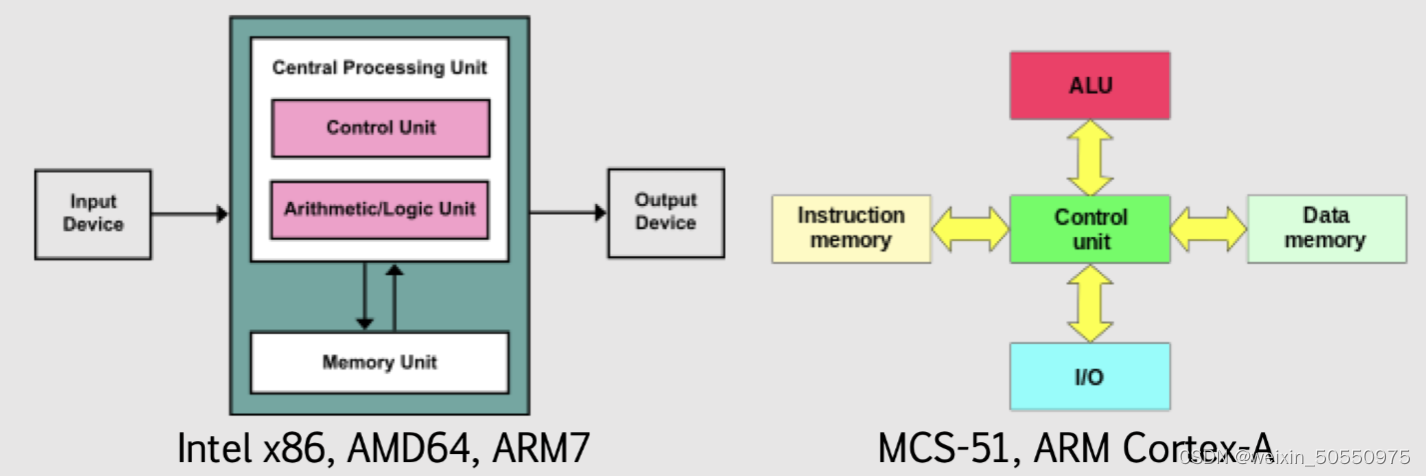
# 摘要
本文全面介绍了计算机组成的原理、数据的表示与处理、存储系统、中央处理器(CPU)设计以及系统结构与性能优化的现代技术。从基本的数制转换到复杂的高速缓冲存储器设计,再到CPU的流水线技术,文章深入阐述了关键概念和设计要点。此外,本文还探讨了现代计算机体系结构的发展,性能评估标准,以及如何通过软硬件协同设计来优化系统性能。计算机组成原理在云计算、人工智能和物联网等现代技术应用中的角色也被分析,旨在展示其在支撑未来技术进
ObjectArx内存管理艺术:高效技巧与防泄漏的最佳实践
# 摘要
本文主要对ObjectArx的内存管理进行了全面的探讨。首先介绍了内存管理的基础知识,包括内存分配与释放的机制、常见误区以及内存调试技术。接着,文章深入讨论了高效内存管理技巧,如内存池、对象生命周期管理、内存碎片优化和内存缓存机制。在第四章,作者分享了防止内存泄漏的实践技巧,涉及设计模式、自动内存管理工具和面
【IT系统性能优化全攻略】:从基础到实战的19个实用技巧

# 摘要
随着信息技术的飞速发展,IT系统性能优化成为确保业务连续性和提升用户体验的关键因素。本文首先概述了性能优化的重要性与基本概念,然后深入探讨了
【C++ Builder 6.0 语法速成】:2小时快速掌握C++编程关键点

# 摘要
本文全面介绍C++ Builder 6.0的开发环境设置、基础语法、高级特性、VCL组件编程以及项目实战应用,并对性能优化与调试技巧进行
【FFT实战案例】:MATLAB信号处理中FFT的成功应用
# 摘要
快速傅里叶变换(FFT)是数字信号处理领域的核心技术,它在理论和实践上都有着广泛的应用。本文首先介绍了FFT的基本概念及其数学原理,探讨了其算法的高效性,并在MATLAB环境下对FFT函数的工作机制进行了详细阐述。接着,文章深入分析了FFT在信号处理中的实战应用,包括信号去噪、频谱分析以及调制解调技术。进一步地,本文探讨了FF
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )