揭秘MATLAB拟合曲线函数:掌握7个实用技巧,提升数据分析效率
发布时间: 2024-05-24 13:25:44 阅读量: 19 订阅数: 14 

# 1. MATLAB拟合曲线函数概述**
MATLAB拟合曲线函数是一种强大的工具,可用于从数据中提取有意义的信息。它允许用户创建数学模型来描述数据中的关系,从而可以对数据进行预测、分析和可视化。
MATLAB提供了一系列曲线拟合函数,包括线性回归、非线性回归、多项式拟合和插值。这些函数基于不同的数学模型,可用于拟合各种类型的数据。通过选择合适的函数并调整其参数,用户可以创建准确且可靠的模型来描述数据中的趋势和模式。
# 2. MATLAB拟合曲线函数的理论基础
### 2.1 线性回归和非线性回归
#### 线性回归
线性回归是一种统计建模技术,用于预测因变量(目标变量)与一个或多个自变量(预测变量)之间的线性关系。线性回归模型的方程为:
```
y = β0 + β1x1 + β2x2 + ... + βnxn + ε
```
其中:
* y 是因变量
* x1, x2, ..., xn 是自变量
* β0, β1, ..., βn 是模型系数
* ε 是误差项
#### 非线性回归
非线性回归是一种统计建模技术,用于预测因变量与自变量之间非线性关系。非线性回归模型的方程可以是任意形式,例如:
```
y = a * exp(bx)
y = a + b * log(x)
y = a * sin(bx)
```
### 2.2 最小二乘法和最大似然法
#### 最小二乘法
最小二乘法是一种优化技术,用于找到一组模型系数,使预测值与实际值之间的平方误差最小。最小二乘法目标函数为:
```
SSE = Σ(yi - ŷi)^2
```
其中:
* SSE 是平方误差和
* yi 是实际值
* ŷi 是预测值
#### 最大似然法
最大似然法是一种优化技术,用于找到一组模型系数,使观察到的数据最有可能发生。最大似然法目标函数为:
```
L(β) = Πf(yi | β)
```
其中:
* L(β) 是似然函数
* f(yi | β) 是数据点 yi 的概率密度函数
* β 是模型系数
**代码块:**
```python
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 数据准备
data = pd.read_csv('data.csv')
X = data[['x1', 'x2']]
y = data['y']
# 线性回归模型
model = LinearRegression()
model.fit(X, y)
# 预测值
y_pred = model.predict(X)
# 评估模型
mse = mean_squared_error(y, y_pred)
print('MSE:', mse)
```
**代码逻辑分析:**
* 导入必要的库。
* 加载数据并将其拆分为自变量 X 和因变量 y。
* 拟合一个线性回归模型。
* 使用训练数据预测因变量。
* 计算预测值与实际值之间的均方误差。
**参数说明:**
* `LinearRegression()`:创建一个线性回归模型对象。
* `fit()`:拟合模型。
* `predict()`:使用模型预测因变量。
* `mean_squared_error()`:计算均方误差。
# 3.1 数据预处理和特征工程
在拟合曲线之前,数据预处理和特征工程是至关重要的步骤。数据预处理涉及清理和转换数据,以使其适合拟合。特征工程涉及创建新特征或转换现有特征,以提高拟合模型的性能。
**数据预处理**
数据预处理包括以下步骤:
- **缺失值处理:**处理缺失值,例如删除缺失值、用平均值或中位数填充缺失值或使用插值方法估计缺失值。
- **异常值处理:**识别和处理异常值,例如删除异常值、用邻近值替换异常值或使用平滑技术减少异常值的影响。
- **数据标准化:**将数据标准化为均值为 0、标准差为 1 的形式,以提高拟合模型的稳定性和收敛速度。
- **数据转换:**将数据转换为更适合拟合模型的形式,例如对数转换、平方根转换或 Box-Cox 转换。
**特征工程**
特征工程涉及创建新特征或转换现有特征,以提高拟合模型的性能。常见的特征工程技术包括:
- **特征选择:**选择与目标变量最相关的特征,以减少模型的复杂性和提高其可解释性。
- **特征缩放:**将特征缩放为相同范围,以防止某些特征对拟合模型产生过大影响。
- **特征创建:**创建新特征,例如多项式特征、交互特征或主成分,以捕获数据中的非线性关系或减少特征空间的维度。
- **特征降维:**使用主成分分析 (PCA) 或奇异值分解 (SVD) 等技术将特征空间降维,以减少模型的复杂性和提高其可解释性。
### 3.2 模型选择和评估
在预处理数据并进行特征工程后,下一步是选择和评估拟合模型。MATLAB 提供了各种拟合模型,包括线性回归、非线性回归、多项式拟合、插值和高斯拟合。
**模型选择**
模型选择取决于数据的性质和拟合的目标。以下是一些常见的准则:
- **线性度:**如果数据呈线性关系,则线性回归模型是合适的。
- **非线性度:**如果数据呈非线性关系,则非线性回归模型(例如多项式回归、指数回归或对数回归)是合适的。
- **拟合目标:**如果拟合目标是插值或预测,则插值模型(例如多项式插值或样条插值)或预测模型(例如时间序列模型或神经网络)是合适的。
**模型评估**
模型评估涉及使用各种指标来衡量拟合模型的性能。常见的评估指标包括:
- **均方误差 (MSE):**测量拟合曲线与实际数据的平均平方误差。
- **决定系数 (R^2):**测量拟合曲线解释数据变异的程度。
- **调整决定系数 (R^2):**考虑模型复杂性的决定系数版本。
- **交叉验证分数:**使用交叉验证技术评估模型的泛化性能。
- **残差分析:**检查拟合曲线的残差(实际数据与拟合值之间的差异)以识别模型的不足之处。
### 3.3 拟合曲线的可视化和解释
拟合曲线后,对其进行可视化和解释对于理解拟合结果至关重要。MATLAB 提供了各种可视化工具,例如 `plot`、`scatter` 和 `fit` 函数,用于绘制拟合曲线和数据。
**可视化**
可视化拟合曲线有助于识别拟合的质量和拟合模型的形状。常见的可视化技术包括:
- **拟合曲线图:**绘制拟合曲线和数据点,以查看拟合的质量和拟合模型的形状。
- **残差图:**绘制残差(实际数据与拟合值之间的差异)与拟合值或自变量之间的关系,以识别模型的不足之处。
- **预测区间:**绘制拟合曲线的预测区间,以显示拟合模型的不确定性。
**解释**
解释拟合曲线涉及理解拟合模型的参数和拟合曲线的形状。常见的解释技术包括:
- **参数解释:**解释拟合模型的参数,例如斜率、截距或系数,以了解拟合模型的含义。
- **曲线形状解释:**解释拟合曲线的形状,例如线性、非线性、多项式或指数,以了解数据中的关系。
- **外推预测:**使用拟合曲线对超出拟合范围的数据进行预测,但要谨慎,因为外推预测可能不准确。
# 4. MATLAB拟合曲线函数的高级应用**
## 4.1 多项式拟合和插值
### 4.1.1 多项式拟合
多项式拟合是一种通过使用多项式函数来拟合数据的技术。多项式函数的形式为:
```
f(x) = a0 + a1x + a2x^2 + ... + anx^n
```
其中,`a0`, `a1`, ..., `an` 为多项式系数。
在 MATLAB 中,可以使用 `polyfit` 函数进行多项式拟合。该函数的语法为:
```
p = polyfit(x, y, n)
```
其中:
* `x` 为自变量数据
* `y` 为因变量数据
* `n` 为多项式的阶数
### 4.1.2 插值
插值是一种通过已知数据点来估计未知数据点值的技术。多项式插值是一种使用多项式函数进行插值的方法。
在 MATLAB 中,可以使用 `interp1` 函数进行插值。该函数的语法为:
```
yi = interp1(x, y, xi)
```
其中:
* `x` 为自变量数据
* `y` 为因变量数据
* `xi` 为要插值的自变量值
## 4.2 指数和对数拟合
### 4.2.1 指数拟合
指数拟合是一种通过使用指数函数来拟合数据的技术。指数函数的形式为:
```
f(x) = a * e^(bx)
```
其中,`a` 和 `b` 为指数函数的参数。
在 MATLAB 中,可以使用 `expfit` 函数进行指数拟合。该函数的语法为:
```
p = expfit(x, y)
```
其中:
* `x` 为自变量数据
* `y` 为因变量数据
### 4.2.2 对数拟合
对数拟合是一种通过使用对数函数来拟合数据的技术。对数函数的形式为:
```
f(x) = a + b * log(x)
```
其中,`a` 和 `b` 为对数函数的参数。
在 MATLAB 中,可以使用 `logfit` 函数进行对数拟合。该函数的语法为:
```
p = logfit(x, y)
```
其中:
* `x` 为自变量数据
* `y` 为因变量数据
## 4.3 高斯和洛伦兹拟合
### 4.3.1 高斯拟合
高斯拟合是一种通过使用高斯函数来拟合数据的技术。高斯函数的形式为:
```
f(x) = a * exp(-((x - b)^2) / (2 * c^2))
```
其中,`a`, `b`, `c` 为高斯函数的参数。
在 MATLAB 中,可以使用 `gaussfit` 函数进行高斯拟合。该函数的语法为:
```
p = gaussfit(x, y)
```
其中:
* `x` 为自变量数据
* `y` 为因变量数据
### 4.3.2 洛伦兹拟合
洛伦兹拟合是一种通过使用洛伦兹函数来拟合数据的技术。洛伦兹函数的形式为:
```
f(x) = a / (1 + ((x - b) / c)^2)
```
其中,`a`, `b`, `c` 为洛伦兹函数的参数。
在 MATLAB 中,可以使用 `lorentzfit` 函数进行洛伦兹拟合。该函数的语法为:
```
p = lorentzfit(x, y)
```
其中:
* `x` 为自变量数据
* `y` 为因变量数据
# 5. MATLAB拟合曲线函数的案例研究
### 5.1 拟合实验数据
**任务:**拟合一组实验数据,该数据包含时间和相应的测量值。
**步骤:**
1. **导入数据:**使用 `importdata` 函数导入数据文件。
2. **数据预处理:**去除异常值,并使用 `smoothdata` 函数平滑数据。
3. **模型选择:**根据数据的形状和趋势,选择合适的拟合模型,例如多项式、指数或对数模型。
4. **拟合曲线:**使用 `fit` 函数拟合曲线,指定模型类型和数据。
5. **评估拟合:**使用 `rsquare` 函数计算拟合优度,并检查残差图以评估模型的拟合效果。
**代码块:**
```
% 导入数据
data = importdata('data.csv');
time = data(:,1);
measurements = data(:,2);
% 数据预处理
measurements = smoothdata(measurements, 'gaussian', 5);
% 模型选择
model = fittype('poly5');
% 拟合曲线
fit_model = fit(time, measurements, model);
% 评估拟合
rsq = rsquare(fit_model, time, measurements);
figure;
plot(time, measurements, 'o');
hold on;
plot(time, fit_model(time), 'r-');
xlabel('Time');
ylabel('Measurements');
title('拟合曲线和原始数据');
legend('原始数据', '拟合曲线');
```
**逻辑分析:**
* `importdata` 函数导入数据文件,并将其存储在 `data` 变量中。
* `smoothdata` 函数使用高斯平滑滤波器平滑数据,以去除噪声。
* `fittype` 函数定义了拟合模型类型,在本例中为五次多项式。
* `fit` 函数拟合曲线,并将结果存储在 `fit_model` 变量中。
* `rsquare` 函数计算拟合优度,在本例中为 R 平方值。
* 绘制原始数据和拟合曲线,以可视化拟合效果。
### 5.2 拟合图像数据
**任务:**拟合一幅图像的像素强度分布。
**步骤:**
1. **读取图像:**使用 `imread` 函数读取图像文件。
2. **提取像素强度:**使用 `im2double` 函数将图像转换为双精度浮点数,并提取像素强度。
3. **直方图分析:**使用 `histogram` 函数计算像素强度的直方图。
4. **模型选择:**根据直方图的形状,选择合适的拟合模型,例如正态分布、伽马分布或对数正态分布。
5. **拟合曲线:**使用 `fitdist` 函数拟合曲线,指定模型类型和像素强度数据。
**代码块:**
```
% 读取图像
image = imread('image.jpg');
% 提取像素强度
intensities = im2double(image);
intensities = intensities(:);
% 直方图分析
histogram(intensities, 100);
xlabel('像素强度');
ylabel('频率');
title('像素强度直方图');
% 模型选择
model = fitdist(intensities, 'Normal');
% 拟合曲线
fit_model = fitdist(intensities, model);
```
**逻辑分析:**
* `imread` 函数读取图像文件,并将其存储在 `image` 变量中。
* `im2double` 函数将图像转换为双精度浮点数,并将其存储在 `intensities` 变量中。
* `histogram` 函数计算像素强度的直方图。
* `fitdist` 函数定义了拟合模型类型,在本例中为正态分布。
* `fitdist` 函数拟合曲线,并将结果存储在 `fit_model` 变量中。
### 5.3 拟合金融数据
**任务:**拟合一组金融时间序列数据,例如股票价格或汇率。
**步骤:**
1. **导入数据:**使用 `readtable` 函数导入金融数据文件。
2. **数据预处理:**去除异常值,并使用 `diff` 函数计算收益率。
3. **模型选择:**根据收益率序列的统计特性,选择合适的拟合模型,例如 ARIMA 模型、GARCH 模型或指数平滑模型。
4. **拟合曲线:**使用 `arima`、`garch` 或 `ets` 函数拟合曲线,指定模型类型和收益率数据。
5. **预测和评估:**使用拟合模型预测未来的收益率,并使用 `mse` 函数评估预测的准确性。
**代码块:**
```
% 导入数据
data = readtable('financial_data.csv');
prices = data.Price;
% 数据预处理
returns = diff(log(prices));
% 模型选择
model = arima('Constant', 0, 'AR', [1, 0, 0], 'MA', [1, 1, 0]);
% 拟合曲线
fit_model = estimate(model, returns);
% 预测和评估
forecast = forecast(fit_model, 10);
mse = mean((forecast - returns(end-9:end)).^2);
```
**逻辑分析:**
* `readtable` 函数导入金融数据文件,并将其存储在 `data` 变量中。
* `diff` 函数计算收益率,并将其存储在 `returns` 变量中。
* `arima` 函数定义了 ARIMA 模型,指定常数项、自回归项和移动平均项。
* `estimate` 函数拟合曲线,并将结果存储在 `fit_model` 变量中。
* `forecast` 函数预测未来的收益率,并将其存储在 `forecast` 变量中。
* `mse` 函数计算预测的均方误差。
# 6. MATLAB拟合曲线函数的最佳实践**
**6.1 避免过拟合和欠拟合**
过拟合和欠拟合是曲线拟合中常见的两个问题。过拟合是指模型过于复杂,以至于它捕捉到了训练数据中的噪声和异常值。这会导致模型在新的数据上表现不佳。欠拟合是指模型过于简单,无法捕捉数据中的趋势。这也会导致模型在新的数据上表现不佳。
避免过拟合和欠拟合的一种方法是使用正则化。正则化是一种惩罚模型复杂性的技术。正则化项添加到目标函数中,目标函数是拟合过程中最小化的函数。正则化项的权重越高,模型越简单。
MATLAB 中有几种正则化方法可用。最常用的方法是岭回归和 LASSO 回归。岭回归添加一个 L2 正则化项,而 LASSO 回归添加一个 L1 正则化项。
**6.2 优化拟合参数**
拟合曲线函数时,需要优化拟合参数。拟合参数是控制曲线形状的参数。优化拟合参数可以提高模型的准确性。
MATLAB 中有几种优化算法可用。最常用的算法是梯度下降和共轭梯度法。梯度下降算法沿着目标函数的负梯度方向迭代,共轭梯度法是梯度下降算法的一种变体。
**6.3 提高拟合效率**
拟合曲线函数可能是计算密集型的。可以通过使用并行计算来提高拟合效率。并行计算是一种在多核处理器上同时执行多个任务的技术。
MATLAB 中有几种并行计算工具可用。最常用的工具是并行计算工具箱。并行计算工具箱提供了一组函数,用于创建和管理并行作业。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《MATLAB拟合曲线函数指南》专栏深入探究了MATLAB中拟合曲线函数的方方面面,从基础概念到高级技巧。它提供了10个循序渐进的步骤,帮助用户掌握拟合技术,并通过7个实用技巧提升数据分析效率。专栏还揭示了5个常见的陷阱,帮助用户避免错误。为了优化性能,它提供了3个优化策略,提高速度和精度。此外,它深入探讨了拟合算法的数学原理,并指导用户选择合适的模型。专栏还涵盖了MATLAB拟合曲线函数的自动化、应用场景、最新进展、最佳实践、常见问题解答、替代方案、性能基准测试、扩展工具包、学习资源、行业案例、开源项目、商业应用、道德考虑和跨平台兼容性。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python字典常见问题与解决方案:快速解决字典难题
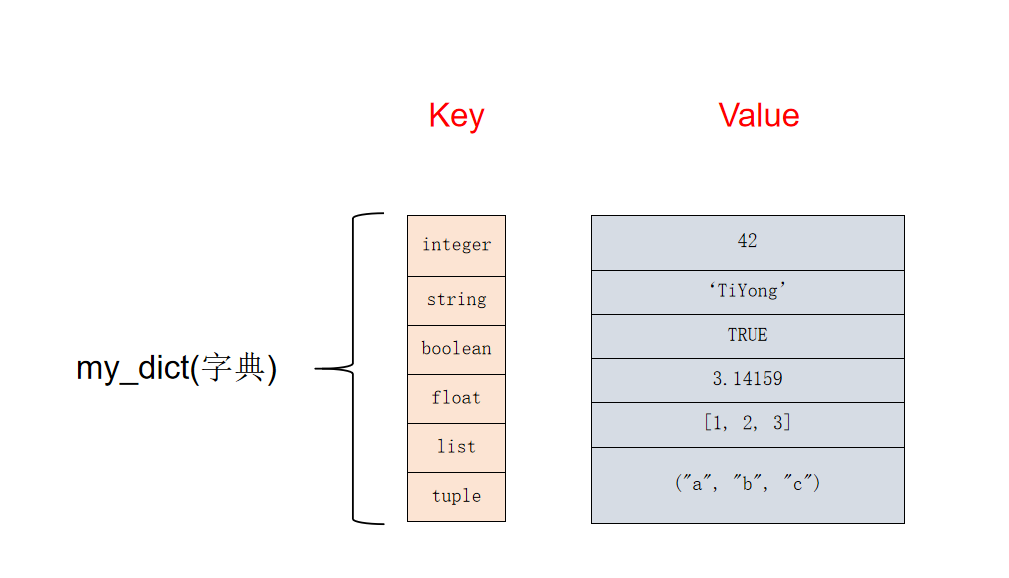
# 1. Python字典简介
Python字典是一种无序的、可变的键值对集合。它使用键来唯一标识每个值,并且键和值都可以是任何数据类型。字典在Python中广泛用于存储和组织数据,因为它们提供了快速且高效的查找和插入操作。
在Python中,字典使用大括号 `{}` 来表示。键和值由冒号 `:` 分隔,键值对由逗号 `,` 分隔。例如,以下代码创建了一个包含键值对的字典:
```py
【实战演练】构建简单的负载测试工具

# 1. 负载测试基础**
负载测试是一种性能测试,旨在模拟实际用户负载,评估系统在高并发下的表现。它通过向系统施加压力,识别瓶颈并验证系统是否能够满足预期性能需求。负载测试对于确保系统可靠性、可扩展性和用户满意度至关重要。
# 2. 构建负载测试工具
### 2.1 确定测试目标和指标
在构建负载测试工具之前,至关重要的是确定测试目标和指标。这将指导工具的设计和实现。以下是一些需要考虑的关键因素:
OODB数据建模:设计灵活且可扩展的数据库,应对数据变化,游刃有余

# 1. OODB数据建模概述
对象-面向数据库(OODB)数据建模是一种数据建模方法,它将现实世界的实体和关系映射到数据库中。与关系数据建模不同,OODB数据建模将数据表示为对象,这些对象具有属性、方法和引用。这种方法更接近现实世界的表示,从而简化了复杂数据结构的建模。
OODB数据建模提供了几个关键优势,包括:
* **对象标识和引用完整性
Python脚本调用与区块链:探索脚本调用在区块链技术中的潜力,让区块链技术更强大

# 1. Python脚本与区块链简介**
**1.1 Python脚本简介**
Python是一种高级编程语言,以其简洁、易读和广泛的库而闻名。它广泛用于各种领域,包括数据科学、机器学习和Web开发。
**1.2 区块链简介**
区块链是一种分布式账本技术,用于记录交易并防止篡改。它由一系列称为区块的数据块组成,每个区块都包含一组交易和指向前一个区块的哈希值。区块链的去中心化和不可变性使其
Python map函数在代码部署中的利器:自动化流程,提升运维效率

# 1. Python map 函数简介**
map 函数是一个内置的高阶函数,用于将一个函数应用于可迭代对象的每个元素,并返回一个包含转换后元素的新可迭代对象。其语法为:
```python
map(function, iterable)
```
其中,`function` 是要应用的函数,`iterable` 是要遍历的可迭代对象。map 函数通
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
Python列表操作的扩展之道:使用append()函数创建自定义列表类

# 1. Python列表操作基础
Python列表是一种可变有序的数据结构,用于存储同类型元素的集合。列表操作是Py
Python Excel数据分析:统计建模与预测,揭示数据的未来趋势
# 1. Python Excel数据分析概述**
**1.1 Python Excel数据分析的优势**
Python是一种强大的编程语言,具有丰富的库和工具,使其成为Excel数据分析的理想选择。通过使用Python,数据分析人员可以自动化任务、处理大量数据并创建交互式可视化。
**1.2 Python Excel数据分析库**
【进阶】Scikit-Learn:K近邻算法(KNN)
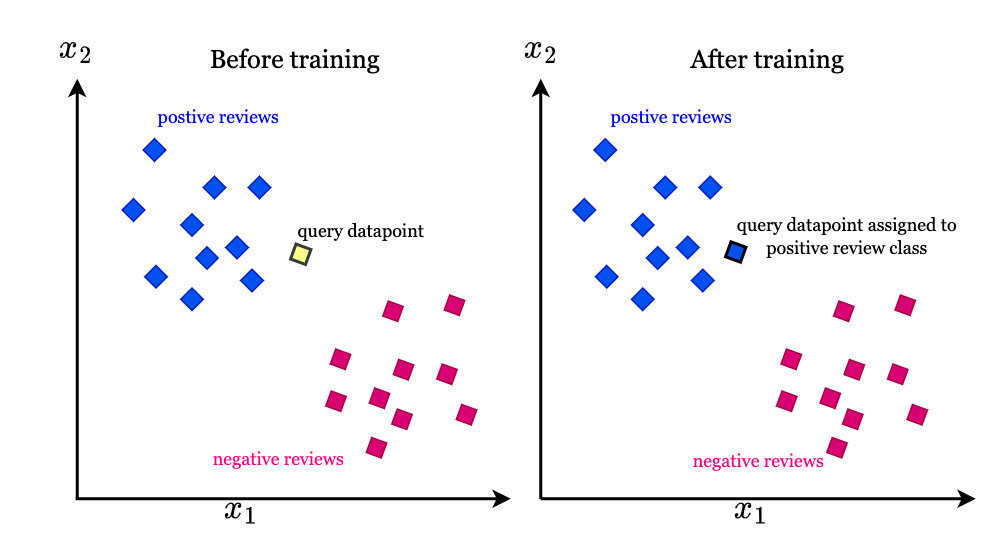
# 1. K近邻算法(KNN)简介**
K近邻算法(KNN)是一种非参数机器学习算法,因其简单易懂、实现方便而被广泛应用。它基于这样的思想:一个样本的类别由其在特征空间中与它最相似的K个样本的类别决定。
KNN算法的原理是:给定一个待分类的样本x,首先计算x与训练集中所有样本的距离,然后选取距离x最近的K个样本,最后根据这K个样本的类别,通过多数投票或加权平均等方式确定x的类别。
# 2. K
【实战演练】综合自动化测试项目:单元测试、功能测试、集成测试、性能测试的综合应用

# 2.1 单元测试框架的选择和使用
单元测试框架是用于编写、执行和报告单元测试的软件库。在选择单元测试框架时,需要考虑以下因素:
* **语言支持:**框架必须支持你正在使用的编程语言。
* **易用性:**框架应该易于学习和使用,以便团队成员可以轻松编写和维护测试用例。
* **功能性:**框架应该提供广泛的功能,包括断言、模拟和存根。
* **报告:**框架应该生成清
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )