Flink的机器学习扩展:FlinkML详解与案例分析
发布时间: 2023-12-20 02:15:48 阅读量: 48 订阅数: 45 
# 第一章:Flink 介绍与机器学习概述
## 1.1 Flink 简介
Apache Flink 是一个流式处理引擎,具有低延迟、高吞吐量和 Exactly-Once 语义的特点。它支持事件驱动的应用程序,能够处理无界和有界的数据流。Flink 采用基于状态的计算模型,能够在一个统一的系统中处理批处理和流处理任务。
Flink 提供了用于构建流处理和批处理应用程序的丰富 API,同时提供了许多高级特性,如事件时间处理、窗口操作、状态管理等。除了数据处理,Flink 还能够与外部系统集成,如 Apache Kafka、Elasticsearch、Hadoop 等。
## 1.2 机器学习在大数据处理中的作用
随着大数据技术的发展,企业积累了海量的数据,如何从这些数据中挖掘有用的信息成为一个关键的问题。机器学习作为一种能够让计算机系统自动学习并改进的技术,为大数据处理提供了强大的工具。
在大数据处理中,机器学习可以用于预测、分类、聚类、异常检测等任务,帮助企业发现数据中的模式,并作出相应的决策。同时,机器学习也可以利用大规模的数据来训练模型,从而提高模型的准确性和泛化能力。
## 1.3 FlinkML 的概念和价值
FlinkML 是基于 Apache Flink 构建的机器学习库,提供了丰富的机器学习算法和工具,以及与 Flink 的集成。FlinkML 的出现,使得在 Flink 中进行机器学习变得更加便捷,并且能够充分利用 Flink 的流处理和状态管理能力。
FlinkML 能够帮助用户在流式环境下进行实时的模型训练和预测,同时也能够处理大规模数据的特征提取和转换。这对于需要结合流处理和机器学习的场景具有重要的意义,如实时推荐、欺诈检测、智能交通等领域。
### 第二章:FlinkML 的基本概念与组件
在这一章节中,我们将深入探讨 FlinkML 的基本概念和组件,以便更好地理解 FlinkML 的工作原理和功能。我们将介绍 FlinkML 的基本原理、库的组件和功能,以及 FlinkML 与传统机器学习库的对比,帮助读者对 FlinkML 的整体架构有更清晰的认识。
## 第三章:FlinkML 中的常见机器学习算法
在本章中,我们将介绍 FlinkML 中的常见机器学习算法,涵盖分类算法、聚类算法和回归算法,以及它们在大数据处理中的应用场景和实际案例。通过对这些算法的深入理解和实际运用,读者可以更好地掌握 FlinkML 在机器学习领域的实际应用。
### 3.1 分类算法
#### 3.1.1 逻辑回归
逻辑回归是一种经典的分类算法,它使用 logistic 函数对数据进行建模,常用于解决二分类问题。在 FlinkML 中,可以通过 LogisticRegression 类来实现逻辑回归算法,该类提供了灵活的参数设置和简洁的模型训练接口。逻辑回归在金融风控、广告推荐等领域有着广泛的应用。
```java
// Java 代码示例
DataSet<Row> trainingData = ...
LogisticRegression logisticRegression = new LogisticRegression()
.setIterations(10)
.setRegParam(0.01);
logisticRegression.fit(trainingData);
```
#### 3.1.2 决策树
决策树是一种常见的分类与回归方法,通过对数据集进行递归划分,构建一棵树形结构,以实现对数据的分类与预测。FlinkML 提供了 DecisionTree 类来支持决策树算法,用户可以根据需求设置树的深度、划分策略等参数。
```python
# Python 代码示例
from flink.ml.tree import DecisionTree
training_data = ...
dec_tree = DecisionTree()
dec_tree.max_depth = 5
dec_tree.fit(training_data)
```
#### 3.1.3 随机森林
随机森林是一种集成学习方法,通过多个决策树的集成来进行分类与回归预测。在 FlinkML 中,RandomForest 类支持对随机森林算法进行训练和预测,用户可以指定子树的个数和特征采样策略等参数。
```python
# Python 代码示例
from flink.ml.ensemble import RandomForest
training_data = ...
rf = RandomForest()
rf.num_trees = 100
rf.feature_subset_strategy = "sqrt"
rf.fit(training_data)
```
### 3.2 聚类算法
#### 3.2.1 K均值
K均值是一种常见的聚类算法,通过迭代计算来将数据集划分为 K 个不同的类别。在 FlinkML 中,KMeans 类提供了对 K 均值算法的支持,用户可以设置最大迭代次数和初始中心点等参数。
```java
// Java 代码示例
DataSet<Row> trainingData = ...
KMeans kMeans = new KMeans()
.setK(3)
.setMaxIterations(20);
kMeans.fit(trainingData);
```
#### 3.2.2 层次聚类
层次聚类是一种基于树形结构的聚类方法,通过逐步合并样本来构建聚类结构。FlinkML 中的 HierarchicalClustering 类支持对层次聚类算法的实现,用户可以指定距离度量方式和合并策略等参数。
```java
// Java 代码示例
DataSet<Row> trainingData = ...
Hierarc
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏为您全面介绍flink数据处理框架及其核心功能。通过一系列文章,您可以初步了解flink实时流处理框架的概述和安装方法。在掌握基本概念后,您将深入了解流、转换、窗口和状态等核心概念,并学习如何连接kafka和socket进行数据源与数据接收。专栏还详细解析了数据转换的map、flatMap和filter操作,以及窗口操作中的tumbling窗口和sliding窗口。此外,您还将了解flink中的时间处理,包括event time和processing time,以及状态管理和数据连接与关联的方法。我们还会介绍flink与kafka、hive、hbase和elasticsearch等工具的集成方法,以及在实时数据可视化、搜索、机器学习扩展和图计算支持方面的应用。与此同时,我们还会探讨flink的容错机制、内存管理和性能调优,以及集群部署和资源分配等实用技巧。通过专栏的学习,您将全面掌握flink数据处理框架的应用与技术细节。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Android应用中的MAX30100集成完全手册:一步步带你上手
# 摘要
本文综合介绍了MAX30100传感器的搭建和应用,涵盖了从基础硬件环境的搭建到高级应用和性能优化的全过程。首先概述了MAX30100的工作原理及其主要特性,然后详细阐述了如何集成到Arduino或Raspberry Pi等开发板,并搭建相应的硬件环境。文章进一步介绍了软件环境的配置,包括Arduino IDE的安装、依赖库的集成和MAX30100库的使用。接着,通过编程实践展示了MAX30100的基本操作和高级功能的开发,包括心率和血氧饱和度测量以及与Android设备的数据传输。最后,文章探讨了MAX30100在Android应用中的界面设计、功能拓展和性能优化,并通过实际案例分析
【AI高手】:掌握这些技巧,A*算法解决8数码问题游刃有余
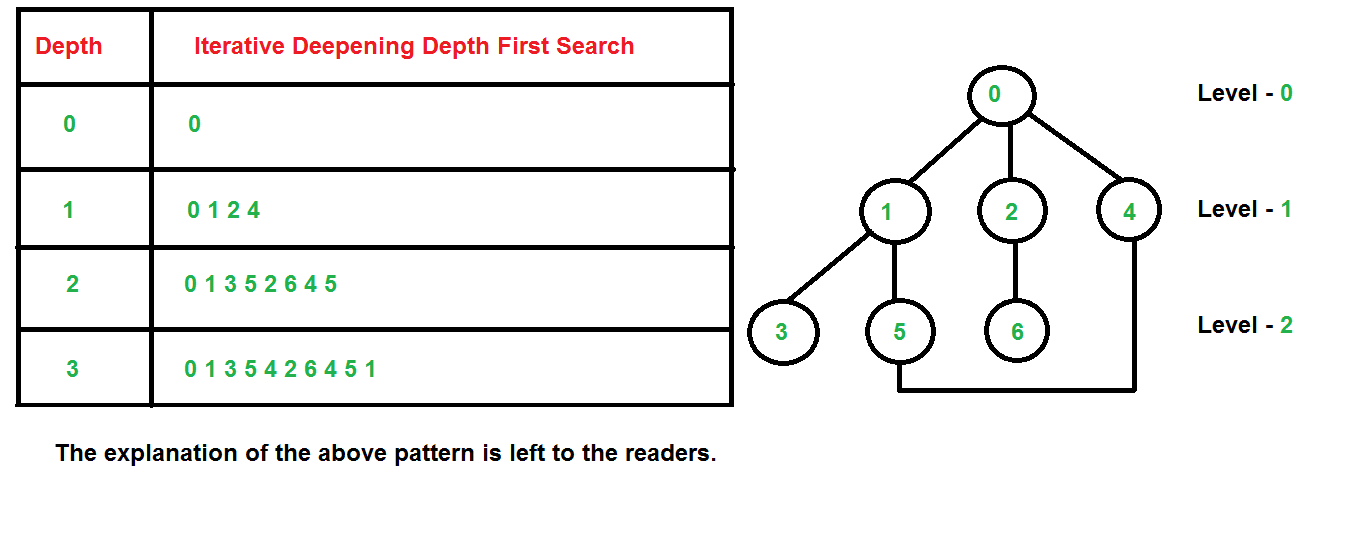
# 摘要
A*算法是计算机科学中广泛使用的一种启发式搜索算法,尤其在路径查找和问题求解领域表现出色。本文首先概述了A*算法的基本概念,随后深入探讨了其理论基础,包括搜索算法的分类和评价指标,启发式搜索的原理以及评估函数的设计。通过结合著名的8数码问题,文章详细介绍了A*算法的实际操作流程、编码前的准备、实现步骤以及优化策略。在应用实例部分,文章通过具体问题的实例化和算法的实现细节,提供了深入的案例分析和问题解决方法。最后,本文展望
【硬件软件接口艺术】:掌握提升系统协同效率的关键策略
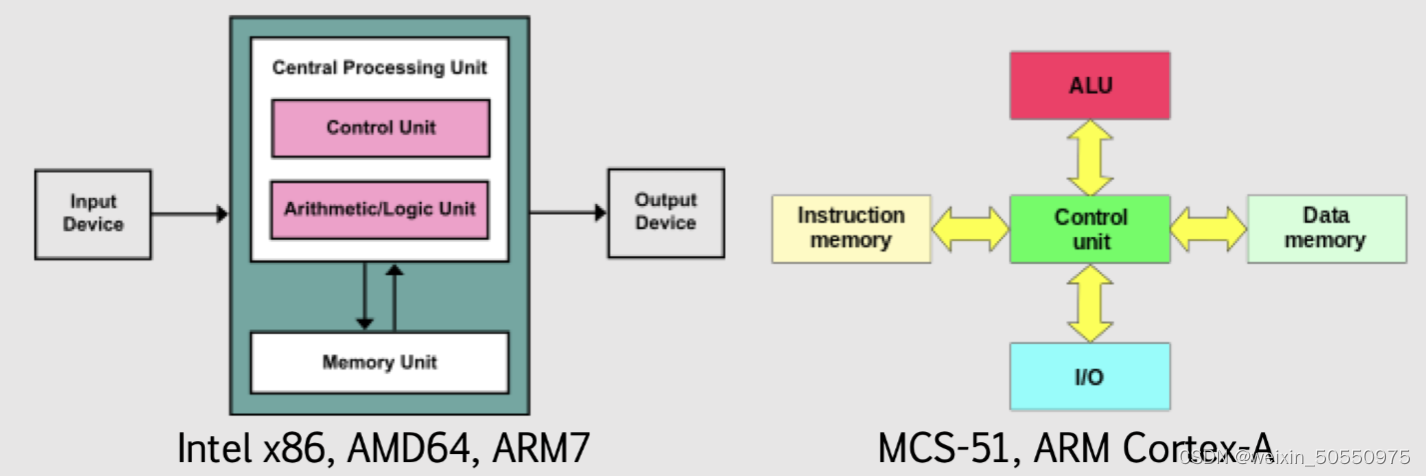
# 摘要
硬件与软件接口是现代计算系统的核心,它决定了系统各组件间的通信效率和协同工作能力。本文首先概述了硬件与软件接口的基本概念和通信机制,深入探讨了硬件通信接口标准的发展和主流技术的对比。接着,文章分析了软件接口的抽象层次,包括系统调用、API以及驱动程序的作用。此外,本文还详细介绍了同步与异步处理机制的原理和实践。在探讨提升系统协同效率的关键技术方面,文中阐述了缓存机制优化、多线程与并行处理,以及
PFC 5.0二次开发宝典:API接口使用与自定义扩展
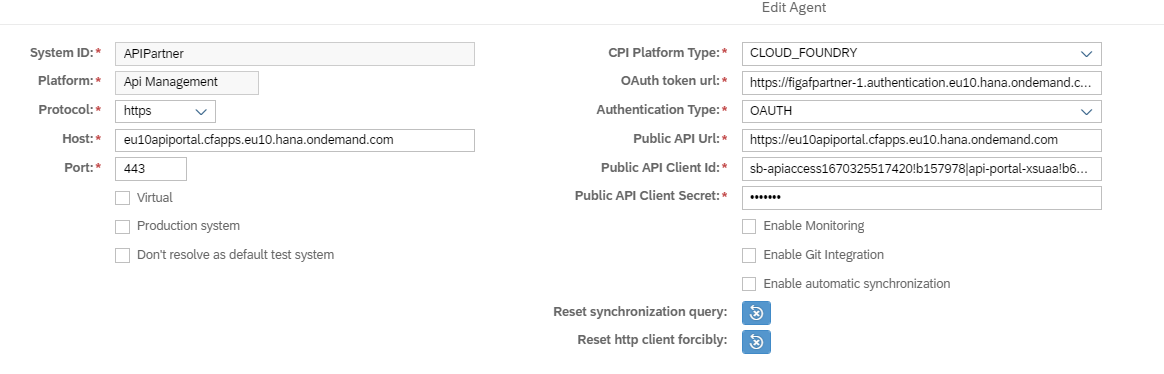
# 摘要
本文深入探讨了PFC 5.0的技术细节、自定义扩展的指南以及二次开发的实践技巧。首先,概述了PFC 5.0的基础知识和标准API接口,接着详细分析了AP
【台达VFD-B变频器与PLC通信集成】:构建高效自动化系统的不二法门

# 摘要
本文综合介绍了台达VFD-B变频器与PLC通信的关键技术,涵盖了通信协议基础、变频器设置、PLC通信程序设计、实际应用调试以及高级功能集成等各个方面。通过深入探讨通信协议的基本理论,本文阐述了如何设置台达VFD-B变频器以实现与PLC的有效通信,并提出了多种调试技巧与参数优化策略,以解决实际应用中的常见问题。此外,本文
【ASM配置挑战全解析】:盈高经验分享与解决方案

# 摘要
自动存储管理(ASM)作为数据库管理员优化存储解决方案的核心技术,能够提供灵活性、扩展性和高可用性。本文深入介绍了ASM的架构、存储选项、配置要点、高级技术、实践操作以及自动化配置工具。通过探讨ASM的基础理论、常见配置问题、性能优化、故障排查以及与RAC环境的集成,本文旨在为数据库管理员提供全面的配置指导和操作建议。文章还分析了ASM在云环境中的应用前景、社区资源和
【自行车码表耐候性设计】:STM32硬件防护与环境适应性提升

# 摘要
本文详细探讨了自行车码表的设计原理、耐候性设计实践及软硬件防护机制。首先介绍自行车码表的基本工作原理和设计要求,随后深入分析STM32微控制器的硬件防护基础。接着,通过研究环境因素对自行车码表性能的影响,提出了相应的耐候性设计方案,并通过实验室测试和现场实验验证了设计的有效性。文章还着重讨论了软件防护机制,包括设计原则和实现方法,并探讨了软硬件协同防护
STM32的电源管理:打造高效节能系统设计秘籍
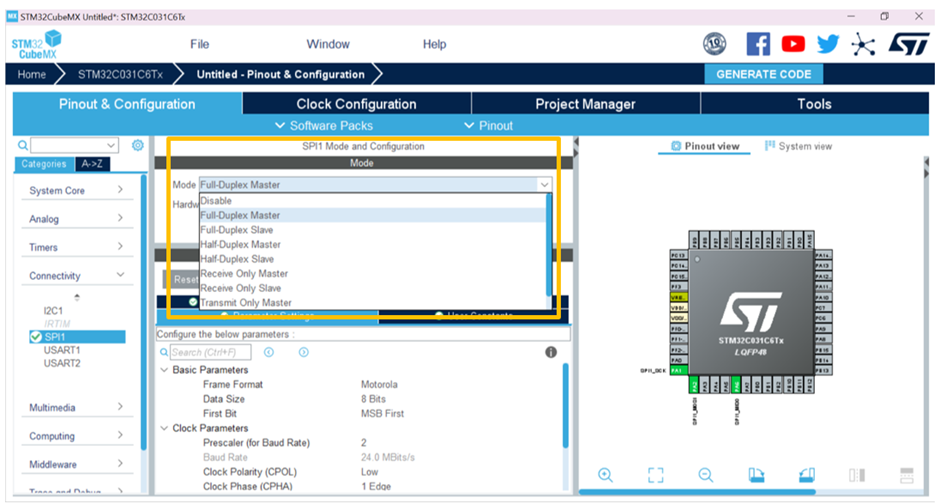
# 摘要
随着嵌入式系统在物联网和便携设备中的广泛应用,STM32微控制器的电源管理成为提高能效和延长电池寿命的关键技术。本文对STM32电源管理进行了全面的概述,从理论基础到实践技巧,再到高级应用的探讨。首先介绍了电源管理的基本需求和电源架构,接着深入分析了动态电压调节技术、电源模式和转换机制等管理策略,并探讨了低功耗模式的实现方法。进一步地,本文详细阐述了软件工具和编程技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )