MATLAB 2014a 对象导向编程实战:面向对象设计与实现,对象导向编程全攻略
发布时间: 2024-06-14 03:59:31 阅读量: 78 订阅数: 32 

Matlab面向对象编程
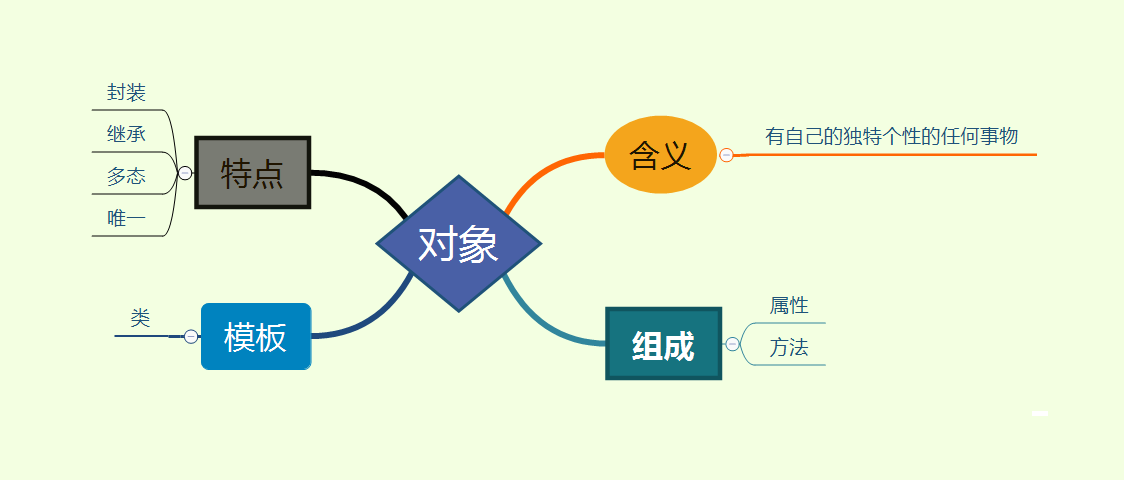
# 1. 面向对象编程(OOP)基础**
面向对象编程(OOP)是一种编程范式,它将程序组织成称为对象的抽象数据类型。对象包含数据(称为属性)和操作数据的方法。OOP 的核心概念包括:
* **封装:**将数据和方法捆绑在一起,形成一个单一的实体。
* **继承:**允许子类从父类继承属性和方法。
* **多态性:**允许对象以不同的方式响应相同的消息,具体取决于它们的类型。
# 2. MATLAB OOP 的理论基础**
**2.1 对象、类和继承**
**对象**
对象是现实世界实体的抽象表示。它封装了数据(属性)和操作(方法)的集合。对象具有状态,它可以被查询或修改。
**类**
类是对象的蓝图,它定义了对象的属性和方法。类提供了一种创建具有相同属性和行为的对象的方法。
**继承**
继承允许一个类(派生类)从另一个类(基类)继承属性和方法。派生类可以重写基类的方法,以提供不同的行为。
**代码块:**
```
class Person
properties
name
age
end
methods
function obj = Person(name, age)
obj.name = name;
obj.age = age;
end
function greet(obj)
disp(['Hello, my name is ', obj.name, ' and I am ', num2str(obj.age), ' years old.']);
end
end
end
class Student < Person
properties
studentId
end
methods
function obj = Student(name, age, studentId)
obj = obj@Person(name, age); % Call the constructor of the base class
obj.studentId = studentId;
end
function greet(obj)
disp(['Hello, my name is ', obj.name, ' and I am ', num2str(obj.age), ' years old. My student ID is ', num2str(obj.studentId), '.']);
end
end
end
```
**逻辑分析:**
* `Person` 类定义了一个具有 `name` 和 `age` 属性和一个 `greet` 方法的对象。
* `Student` 类从 `Person` 类继承,并添加了 `studentId` 属性。
* `Student` 类重写了 `greet` 方法,以显示额外的学生 ID 信息。
**参数说明:**
* `Person` 构造函数:`name`(字符串)、`age`(数字)
* `Student` 构造函数:`name`(字符串)、`age`(数字)、`studentId`(数字)
* `greet` 方法:无参数
**2.2 多态性和抽象类**
**多态性**
多态性允许对象以不同的方式响应相同的操作,具体取决于它们的类型。这使得代码更灵活,更易于维护。
**抽象类**
抽象类是不能被实例化的类。它们用于定义公共接口,而派生类实现该接口。抽象类可以包含抽象方法,这些方法必须在派生类中实现。
**代码块:**
```
abstract class Shape
properties
color
end
methods (Abstract)
area()
perimeter()
end
end
class Rectangle < Shape
properties
width
height
end
methods
function obj = Rectangle(color, width, height)
obj = obj@Shape(color);
obj.width = width;
obj.height = height;
end
function a = area(obj)
a = obj.width * obj.height;
end
function p = perimeter(obj)
p = 2 * (obj.width + obj.height);
end
end
class Circle < Shape
properties
radius
end
methods
function obj = Circle(color, radius)
obj = obj@Shape(color);
obj.radius = radius;
end
function a = area(obj)
a = pi * obj.radius^2;
end
function p = perimeter(obj)
p = 2 * pi * obj.radius;
end
end
end
```
**逻辑分析:**
* `Shape` 抽象类定义了公共接口,包括 `color` 属性和 `area` 和 `perimeter` 抽象方法。
* `Rectangle` 和 `Circle` 派生类实现了 `Shape` 抽象类,并提供了 `area`

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
MATLAB 2014a 专栏深入探讨了 MATLAB 的最新功能和技术,旨在帮助用户提升编程技能和解决复杂问题。专栏涵盖了广泛的主题,包括:
* 性能优化秘籍:揭示加快代码速度的技巧。
* 图形化编程进阶:创建交互式可视化应用程序,提升用户体验。
* 数据分析实战:从数据挖掘到机器学习,解锁数据价值。
* 并行计算探索:加速大型数据处理,缩短计算时间。
* 算法实现指南:从理论到实践,掌握算法精髓。
* 信号处理实战:从基础概念到高级应用,信号处理全解析。
* 图像处理进阶:图像增强、分割和识别,图像处理全攻略。
* 控制系统设计:从建模到仿真,控制系统设计实战。
* 电路仿真实战:从基础元件到复杂系统,电路仿真全解析。
* 机器学习算法解析:原理、实现和应用,机器学习算法全揭秘。
* 深度学习入门:神经网络与图像识别,深度学习入门指南。
* 优化算法详解:从梯度下降到进化算法,优化算法全解析。
* 数据可视化艺术:打造引人入胜的图表,数据可视化实战。
* 脚本编程技巧:提升代码可读性和效率,脚本编程全攻略。
* 函数开发指南:创建可重用和可维护的代码,函数开发全解析。
* 对象导向编程实战:面向对象设计与实现,对象导向编程全攻略。
* 单元测试与调试:确保代码质量与可靠性,单元测试与调试全解析。
* 版本控制入门:协作开发与代码管理,版本控制全攻略。
* 部署与发布:将应用程序推向生产环境,部署与发布全解析。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
AMESim液压仿真秘籍:专家级技巧助你从基础飞跃至顶尖水平

# 摘要
AMESim液压仿真软件是工程师们进行液压系统设计与分析的强大工具,它通过图形化界面简化了模型建立和仿真的流程。本文旨在为用户提供AMESim软件的全面介绍,从基础操作到高级技巧,再到项目实践案例分析,并对未来技术发展趋势进行展望。文中详细说明了AMESim的安装、界面熟悉、基础和高级液压模型的建立,以及如何运行、分析和验证仿真结果。通过探索自定义组件开发、多学科仿真集成以及高级仿真算法的应用,本文
【高频领域挑战】:VCO设计在微波工程中的突破与机遇
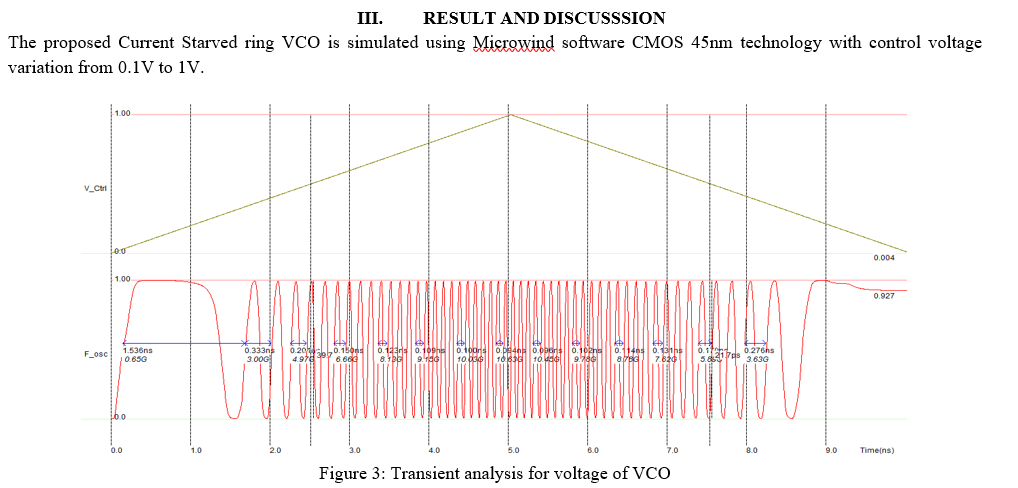
# 摘要
本论文深入探讨了压控振荡器(VCO)的基础理论与核心设计原则,并在微波工程的应用技术中展开详细讨论。通过对VCO工作原理、关键性能指标以及在微波通信系统中的作用进行分析,本文揭示了VCO设计面临的主要挑战,并提出了相应的技术对策,包括频率稳定性提升和噪声性能优化的方法。此外,论文还探讨了VCO设计的实践方法、案例分析和故障诊断策略,最后对VCO设计的创新思路、新技术趋势及未来发展挑战
实现SUN2000数据采集:MODBUS编程实践,数据掌控不二法门
# 摘要
本文系统地介绍了MODBUS协议及其在数据采集中的应用。首先,概述了MODBUS协议的基本原理和数据采集的基础知识。随后,详细解析了MODBUS协议的工作原理、地址和数据模型以及通讯模式,包括RTU和ASCII模式的特性及应用。紧接着,通过Python语言的MODBUS库,展示了MODBUS数据读取和写入的编程实践,提供了具体的实现方法和异常管理策略。本文还结合SUN20
【性能调优秘籍】:深度解析sco506系统安装后的优化策略
# 摘要
本文对sco506系统的性能调优进行了全面的介绍,首先概述了性能调优的基本概念,并对sco506系统的核心组件进行了介绍。深入探讨了核心参数调整、磁盘I/O、网络性能调优等关键性能领域。此外,本文还揭示了高级性能调优技巧,包括CPU资源和内存管理,以及文件系统性能的调整。为确保系统的安全性能,文章详细讨论了安全策略、防火墙与入侵检测系统的配置,以及系统审计与日志管理的优化。最后,本文提供了系统监控与维护的
网络延迟不再难题:实验二中常见问题的快速解决之道
# 摘要
网络延迟是影响网络性能的重要因素,其成因复杂,涉及网络架构、传输协议、硬件设备等多个方面。本文系统分析了网络延迟的成因及其对网络通信的影响,并探讨了网络延迟的测量、监控与优化策略。通过对不同测量工具和监控方法的比较,提出了针对性的网络架构优化方案,包括硬件升级、协议配置调整和资源动态管理等。
期末考试必备:移动互联网商业模式与用户体验设计精讲

# 摘要
移动互联网的迅速发展带动了商业模式的创新,同时用户体验设计的重要性日益凸显。本文首先概述了移动互联网商业模式的基本概念,接着深入探讨用户体验设计的基础,包括用户体验的定义、重要性、用户研究方法和交互设计原则。文章重点分析了移动应用的交互设计和视觉设计原则,并提供了设计实践案例。之后,文章转向移动商业模式的构建与创新,探讨了商业模式框架
【多语言环境编码实践】:在各种语言环境下正确处理UTF-8与GB2312

# 摘要
随着全球化的推进和互联网技术的发展,多语言环境下的编码问题变得日益重要。本文首先概述了编码基础与字符集,随后深入探讨了多语言环境所面临的编码挑战,包括字符编码的重要性、编码选择的考量以及编码转换的原则和方法。在此基础上,文章详细介绍了UTF-8和GB2312编码机制,并对两者进行了比较分析。此外,本文还分享了在不同编程语言中处理编码的实践技巧,
【数据库在人事管理系统中的应用】:理论与实践:专业解析

# 摘要
本文探讨了人事管理系统与数据库的紧密关系,分析了数据库设计的基础理论、规范化过程以及性能优化的实践策略。文中详细阐述了人事管理系统的数据库实现,包括表设计、视图、存储过程、触发器和事务处理机制。同时,本研究着重讨论了数据库的安全性问题,提出认证、授权、加密和备份等关键安全策略,以及维护和故障处理的最佳实践。最后,文章展望了人事管理系统的发展趋
【Docker MySQL故障诊断】:三步解决权限被拒难题
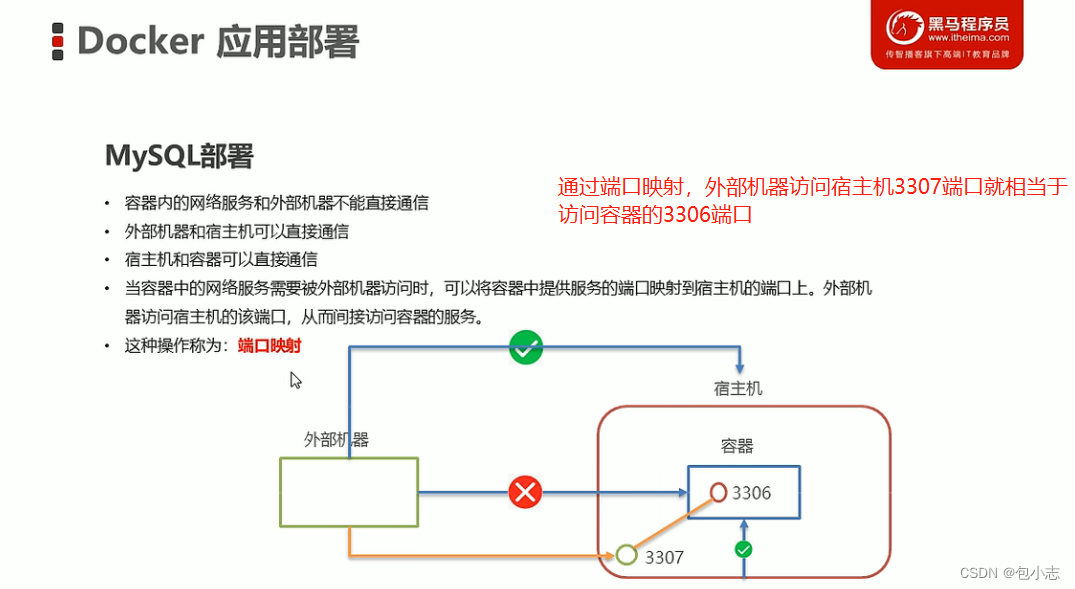
# 摘要
随着容器化技术的广泛应用,Docker已成为管理MySQL数据库的流行方式。本文旨在对Docker环境下MySQL权限问题进行系统的故障诊断概述,阐述了MySQL权限模型的基础理论和在Docker环境下的特殊性。通过理论与实践相结合,提出了诊断权限问题的流程和常见原因分析。本文还详细介绍了如何利用日志文件、配置检查以及命令行工具进行故障定位与修复,并探讨了权限被拒问题的解决策略和预防措施
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )